第二章 Python语言基本语法元素
1.获得用户输入的一个整数N,计算并输出N的32次方
这里考虑还没有学过N**32或者pow()等语法,所以用的是最麻烦的方法。
num=eval(input("请输入数字"))
i=32
numf=num
while i>0:
numf=numf*num
print(numf)
i=i-1
2.获得用户输入的一段文字,将这段文字进行垂直输出。
在后面学到字符串的一些性质以后发现可以用for c in s来遍历字符串中的每个字符,其实垂直输出就是多了个回车。
a=input("please ")
i=len(a)
while i>0:
print(a[-i])
i=i-1
3.获得用户输入的一个合法算式,例如1.2+3.4,输出运算结果。
eval()就是去掉‘’
a=eval(input())
print(a)
4.获得用户输入的一个小数,提取并输出其整数部分。
这里好像没考虑数字中没有小数点的情况,可以在while中在添加一个条件判断i是否到0
a=input("little ")
i=len(a)
while a[-i]!='.':
print(a[-i],end='')
i=i-1
5.获得用户输入的一个整数N,计算并输出1到N相加的和。
n=eval(input("请输入整数N:"))
sum=0
for i in range(n):
sum+=i+1
print("1到N求和结果{}".format(sum))
第三章 数字类型
1.获得用户输入的一个整数,输出该整数百位及以上的数字。
没有考虑数字没有百位的情况,//取整是不要小数部分的取整
i=eval(input("please\n"))
i=i//100
print(i)
2.获得用户输入的一个字符串,将字符串按照空格分割,然后逐行打印出来。
s=input("Please\n")
sl=s.split(' ')
for a in sl:
print(a)
3.程序读入一个表示星期几的数字(1-7),输出对应的星期字符串名称。例如,输入3,返回“星期三”。
i=eval(input("please\n"))
l=['星期一','星期二','星期三','星期四','星期五','星期六','星期日']
print(l[i-1])
4.设n是一任意自然数,如果n的各位数字反向排列所得自然数与n相等,则n被称为回文数。从键盘输入一个5位数字,请编写程序判断这个数字是不是回文数。
这个可以判断不仅5位
i=eval(input("please\n"))
s=str(i)
l=len(s)//2
flag=True
while l>0:
if s[l-1]!=s[-l]:
flag=False
print("no")
break
l=l-1
if flag==True:
print('yes')
5.输入一个十进制整数,分别输出其二进制、八进制、十六进制字符串。
十六进制和八进制在教材里都有提到现成的函数hex()和oct(),可是好像没有说二进制的,这里利用除2的办法求
刚才在教材第九章中的random那一节中看到了二进制函数bin(),在P166
x=eval(input("please\n"))
print(hex(x))
print(oct(x))
s=''
while x>1:
x,b=divmod(x,2)
s=str(b)+s
s='1'+s
print('0b'+s)
第四章 程序的控制结构
1.输入一个年份,输出是否是闰年。#闰年条件:能被4整除但不能被100整除,或者能被400整除的年份,都是闰年。
这里刚学异常处理就用了一下
#输入年份
while True:
try:
year=eval(input("请输入一个年份\n"))
break
except:
print("输入有错")
if year%4==0 and year%100!=0:
print("闰年")
elif year%400==0:
print("闰年")
else:
print("不是闰年")
2.最大公约数计算。获得两个整数,求出这两个整数的最大公约数和最小公倍数。最大公约数的计算一般使用辗转相除法,最小公倍数则使用两个数的乘积除以最大公约数。
a=eval(input("输入第一个数字"))
b=eval(input("输入第二个数字"))
if a<b:
a,b=b,a
c=a*b
while a%b!=0:
a,b=b,a%b
print(b)
print(int(c/b))
3.统计不同字符个数。用户从键盘键入一行字符,编写一个程序,统计并输出其中英文字符、数字、空格和其他字符的个数。
s=input("请输入一个字符串")
eng=0
num=0
back=0
other=0
for c in s:
if (c>='a' and c<='z')or \
(c>='A' and c<='Z'):
eng+=1
elif c>='0' and c<='9':
num+=1
elif c==' ':
back+=1
else:
other+=1
print(eng,num,back,other)
4.改编题目1中的程序,当用户输入出错时给出“输入内容必须是整数!”的提示,并让用户重新输入。
正好在4.1里面试了一下异常处理,可以参考4.1
5.羊车门问题。有三扇关闭的门,一扇门后面停着汽车,其余门后是山羊,只有主持人知道每扇门后面是什么。参赛者可以选择一扇门。在开启它之前,主持人会开启另外一扇门,露出门后的山羊。此时,允许参赛者更换自己的选择。请问,参赛者更换选择后能否增加猜中汽车的机会?——这是一个经典问题。请使用random库对这个随机事件进行预测,分别输出参赛者改变选择和坚持选择获胜的概率。
这道题目还是挺有意思的,可是我英语不太好,变量的名字取的不太好,right是坚持选择猜对的次数,right2是改变选择猜对的次数,god是主持人开启的另外一扇门要求既不能是参赛者猜的那扇也不能是车子那扇,6-choice-god==car左边表达的是参赛者改变选择后所选的门,6代表的是1+2+3=6
import random
right=0
right2=0
j=10000
for i in range(j):
car=random.randint(1,3)
choice=random.randint(1,3)
if car==choice:
right+=1
while True:
god=random.randint(1,3)
if god!=car and god!=choice:
break
if 6-choice-god==car:
right2+=1
print("{:.2%}".format(right/j))
print("{:.2%}".format(right2/j))
第五章 函数和代码复用
1.实现isNum()函数,参数作为一个字符串,如果这个字符串属于整数、浮点数或复数的表示,则返回True,否则返回False。
def isNum(str):
try:
str=eval(str)
if type(str)==type(10) \
or type(str)==type(1.0) \
or type(str)==type(1+1j):
return True
else:
return False
except:
return False
f=isNum('123')
print(f)
2.实现isPrime函数,参数为整数,要有异常处理。如果整数是质数,返回True,否则返回False。
def isPrime(i):
try:
for j in range(2,i):
if i%j==0:
return False
return True
except:
print('请输入整数')
print(isPrime(12))
3.编写一个函数计算传入字符串中数字、字母、空格以及其他字符的个数。
这道题跟4.3是一样的,不同的是要封装成函数
def counts(str):
num,ch,back,oth=0,0,0,0
for c in str:
if c>='0' and c<='9':
num+=1
elif (c>='a' and c<='z') \
or (c>='A' and c<='Z'):
ch+=1
elif c==' ':
back+=1
else:
oth+=1
return num,ch,back,oth
a=counts("dkjfi3943;[34p[3. 3j43. 34. 3kjk[[[p")
print(a)
4.编写一个函数,打印200以内的所有素数,以空格分隔。
这道题完全可以用5.2的函数来继续做,利用5.2的判断选择打印或者不打印
def prime(num):
for i in range(2,num+1):
flag=True
for j in range(2,i):
if i%j==0:
flag=False
break
if flag:
print(i,end=' ')
prime(200)
5.编写一个函数,参数为一个整数n。利用递归获取斐波那契数列中的第n个数并返回。
我一直觉得递归很有技巧性,可是我并不觉得递归好用,如果你写的代码用了递归,我不觉得会简洁清晰而舒服,反而有时候会感觉并不是很直观
def fib(num):
if num==1 or num==2:
return 1
return fib(num-1)+fib(num-2)
print(fib(9))
第六章 组合数据类型
1.英文字符频率统计。编写一个程序,对给定字符串中出现的a~z字母频率进行分析,忽略大小写,采用降序方式输出。
这个不仅可以对英文字符进行统计,可以对任何字符进行统计
str='kdjfierjkemfkdjfiek中肿中V工r‘\'\'’na;akdfqpeirAJSKJDIWunn v'
str=str.lower()
strdict={}
for c in str:
#if c>='a' and c<='z':
strdict[c]=strdict.get(c,0)+1
strlist=list(strdict.items())
strlist.sort(key=lambda x:x[1],reverse=True)
for i in range(len(strlist)):
print("{0:<10}{1:>10}".format(strlist[i][0],strlist[i][1]))
2.中文字符频率统计。编写一个程序,对给定字符串中出现的全部字符(含中文字符)频率进行分析,采用降序方式输出。
参考上一题
3.随机密码生成。编写程序,在26个字母大小写和9个数字组成的列表中随机生成10个8位密码。
先生成列表l,再利用随机数生成密码,10个8位用两个循环嵌套就可以了,但是要注意在代码里我用了一个passwd.copy()把副本添加到密码列表里,是因为如果直接把passwd放到passwds里的话,会导致放进去的是一个地址引用,导致passwds里面的10个密码都是一样的
import random
l=list()
passwds=[]
passwd=[]
i=ord('0')
while i<=ord('z'):
l.append(chr(i))
i+=1
if chr(i-1)=="Z":
i=ord('a')
elif chr(i-1)=='9':
i=ord('A')
for ii in range(10):
for j in range(8):
ran=random.randint(0,len(l)-1)
passwd.append(l[ran])
#print(passwd)
passwds.append(passwd.copy())
passwd.clear()
for items in passwds:
for item in items:
print(item,end='')
print('\n')
4.重复元素判定。编写一个函数,接受列表作为参数,如果一个元素在列表中出现了不止一次,则返回True,但不要改变原来列表的值。同时编写调用这个函数和输出测试结果的程序。
我用的第一种方法(注释部分)比较麻烦,通过lis.count()来判断,而且不知道为什么我用了一个字典来存放bool值,好像是一开始我对题目的理解有问题,我一开始认为重复元素也要返回。
第二种方法相对比较简单,直接转化成集合,利用集合的不重复特点,判断长度是否变小了
# def repeat(lis=[]):
# dics={}
# for li in lis:
# if lis.count(li)>1:
# dics[li]=True
# else:
# dics[li]=False
# return dics
# lism=['d','e','b','d',';','3',';',9,3,9]
# dicsm=repeat(lism)
# print(dicsm)
# print(lism)
def repeat(lis=[]):
sets=set(lis)
if len(sets)==len(lis):
return False
return True
lism=['d','e','b','3',';',9,3,3]
dicsm=repeat(lism)
print(dicsm)
5.重复元素判定续。利用集合的无重复性改编上一个程序,获得一个更快更简洁的版本。
参考上一题
第七章 文件和数据格式化
1.输入一个文件和一个字符,统计该字符在文件中出现的次数。
def cInTxt(filename,char):
count=0
fo=open(filename,'r')
txt=fo.read()
txt=txt.lower()
for word in txt:
if char==word:
count+=1
fo.close()
return count
print(cInTxt('Hamlet.TXT','t'))
2.假设有一个英文文本文件,编写一个程序读取其内容并将里面的大写字母变成小写字母,小写字母变成大写字母。
在网上下了一个哈姆雷特的英文版放在同一个文件夹里,然后学习了一下模块化,分成了三个模块
def readfile(filename):
fo=open(filename,'r')
txt=fo.read()
fo.close()
return txt
def chg(txt):
newtxt=''
for char in txt:
if 'a'<=char<="z":
newtxt+=chr(ord(char)-32)
elif 'A'<=char<='Z':
newtxt+=chr(ord(char)+32)
else:
newtxt+=char
return newtxt
def writefile(filename,txt):
fw=open(filename,'w')
fw.write(txt)
fw.close()
txt=readfile("Hamlet.TXT")
newtxt=chg(txt)
writefile("123.txt",newtxt)
3.编写一个程序,生成一个10×10的随机矩阵并保存为文件(空格分隔行向量,换行分隔列向量),再写程序将刚才保存的矩阵文件另存为CSV格式,用Excel或文本编辑器打开看看结果对不对。
按照题目要求好像是要编写两个程序,第一个程序生成了一个文本文件,第二个程序我用了一个import re这里是引用了一个正则表达式,目的是在第一个程序中为了对齐增加的多个空格变成一个空格
import random
fw=open("7.3.txt",'w')
for i in range(10):
for j in range(10):
rand=random.randint(1,1000)
if j==9:
fw.write("{:<}".format(str(rand))+'\n')
else:
fw.write("{:<5}".format(str(rand)+' '))
fw.close()
fr=open("7.3.txt",'r')
txt=fr.read()
import re
txt=re.sub(' +',' ',txt)
fw=open("7.3.csv",'w')
fw.write(txt.replace(' ',','))
fw.close()
fr.close()
4.编写一个程序,读取一个python源代码文件,将文件中所有除保留字外的小写字母换成大写字母,生成后的文件要能够被Python解释器正确执行。
我觉得这道题目很难理解,如果只把保留字不变的话,是不可能完成的,很多内置函数会因为大小写改变而无法运行,而那么多内置函数,还有一些参数也不能改变大小写,比如读取文件的open(‘ ‘,’r’)中的r也不能改变,所有要写一个万能的可能不太好做,或者我的理解有偏差,这里我仅改变上一题中的第二部分的程序
# theword={'and','as','break','continue','def','del','elif',\
# 'else','except','False','for','global','if','import','in',\
# 'is','lambda','not','or','return','True','try','while'}
import keyword
#import re
s=keyword.kwlist
s+=[' re','re.','sub','csv','open','close','txt','read',"'r'",'import',\
'write','replace',"'w'"]
fr=open('7.3.2.py','r')
newtxt=txt=fr.read()
fr.close()
newtxt=newtxt.upper()
print(newtxt)
for word in s:
if word.upper() in newtxt:
newtxt=newtxt.replace(word.upper(),word)
print(newtxt)
fw=open("7.4.1.py",'w')
fw.write(newtxt)
fw.close()
# for c in txt:
# if not ('a'<=c<='z' or 'A'<=c<='Z'):
# newtxt=newtxt.replace(c,' ')
# #newtxt=re.sub(' +',' ',newtxt)
# newtxt=set(newtxt.split())
# print(newtxt)
# print(s)
改变前的程序
fr=open("7.3.txt",'r')
txt=fr.read()
import re
txt=re.sub(' +',' ',txt)
fw=open("7.3.csv",'w')
fw.write(txt.replace(' ',','))
fw.close()
fr.close()改变后的程序
FR=open("7.3.txt",'r')
txt=FR.read()
import re
txt=re.sub(' +',' ',txt)
FW=open("7.3.csv",'w')
FW.write(txt.replace(' ',','))
FW.close()
FR.close()
5.编写一个程序,要求能够将元素为任意Python支持的类型(包括含有半角逗号的字符串)的列表转储为CSV,并能够重新正确解析为列表。
这道题不太好理解,首先要把任意类型的转存成csv的话,任意类型都要转变成字符串,所以需要另外保留该类型的标志,以便后面从csv转换回来的时候可以知道类型。
第八章 Python计算生态
我是先学完第十章第十一章,才学的这一章的,所以对题目关于第三方库方面的可能已经有一点了解了
1.用户输入一个年份,编写程序判断该年是否是闰年,如果年份能被400整除,则为闰年;如果年份能被4整除但不能被100整除也为闰年。
之前做过同样的题目,唯一不同的是这里用了自顶向下设计的模块化编程
def main():
year=getYear()
flag=isRun(year)
printRun(flag)
def getYear():
while True:
try:
year=eval(input("请输入一个年份\n"))
return year
except:
print("请输入一个整数\n")
def isRun(year):
if year%4==0 and year%100!=0:
return True
elif year%400==0:
return True
else:
return False
def printRun(flag):
if flag:
print("闰年")
else:
print("不是闰年")
main()
2.参考最后一个实例,尝试将不同标签中的内容分门别类地提取出来,再想想如何提取可以更为准确。(提示:可查阅HTML相关语法)
原来上学的时候其实有了解过html的内容,可是没有学的很深入,这里的标签还好理解,可是怎么理解标签中的内容呢?
可以参考下一题,用beautifulsoup4来做,当然也可以按照自己的理解做
3.续上一题,找另外一个网站,尝试编程提取一些自己感兴趣的东西出来。(提示:可自行搜索用于HTML解析的第三方库)
这道题我参考了网上的一些内容,做了一个比较简单的抓取图片的爬虫,网上有很多抓取美女图片的爬虫教程,大家可以看一下,我主要用到了requests库,beautifulsoup4库,os库,requests主要是访问网站的,beautifulsoup4主要用来处理html文档的,os库在这里我用来判断文件是否存在。
这里有几个点需要注意一下:1、在代码注释中有解释headers的用处,主要是headers中的referer,因为访问图片的时候用到这个,如果没有这个参数,就会访问到另外一个图片
2、r.encoding那句是防止乱码,这也是一开始踩到的坑,后来查了下资料,才知道这个问题3、range(200)是下载200张图片
4、判断文件是否存在,是因为每次都从第一张图片开始下载,很浪费,所以先判断当前图片是不是已经下载过了,再下载
5、这里主要学到了requests库,beautifulsoup4库,os库的相关知识,参考了一些网站,内容比较……..
import requests
from bs4 import BeautifulSoup
import os
#如果没有headers 可能会因为反爬虫而无法爬取到想要的图片
headers={'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_1) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.1 Safari/605.1.15','Referer': 'https://m.mm131.net/'}
r=requests.get("https://m.mm131.net",headers=headers)
r.encoding='gb2312' #没有这句会乱码
soup=BeautifulSoup(r.text,'lxml')
html=soup.find('content',id='content').find('a',class_='post-title-link')['href']
#for html in htmls:
for i in range(200):
img_req=requests.get(html,headers=headers)
img_req.encoding='gb2312'
img_soup=BeautifulSoup(img_req.text,'lxml')
img_html=img_soup.find('content',id='content').find('img')
print(img_html['src'])
img_name=img_html['alt']+'.jpg'
img_path='/Users/chenpeng/Desktop/图片/'
if not os.path.exists(img_path+img_name):
down_req=requests.get(img_html['src'],headers=headers)
f=open(img_path+img_name,'wb')
f.write(down_req.content)
f.close()
else:
print("{}图片已下载".format(img_name))
html='https://m.mm131.net/xinggan/'+img_soup.find('content',id='content').find('a')['href']
4.参考第6章最后一个例子,按照8.2节中的方法重新实现一个有较好的函数封装的《Hamlet》文本词频统计程序。
自顶向下的设计
import re
def getText():
txt=open("Hamlet.TXT","r").read()
txt=txt.lower()
for c in txt:
if (c>='a' and c<='z'):
continue
else:
txt=txt.replace(c,' ')
txt=re.sub(' +',' ',txt) #正则表达式
return txt
def dealtxt(txt):
txtlist=txt.split(' ')
for k in txtlist:
txtdict[k]=txtdict.get(k,0)+1
return txtlist
def sorttxt(txtlist):
newtxtl=list(txtdict.items())
newtxtl.sort(key=lambda x:x[1],reverse=True)
return newtxtl
def showtxt(newtxtl,num):
for i in range(num):
print("{0:<15}{1:>10}".format(newtxtl[i][0],newtxtl[i][1]))
def main():
txt=getText()
txtlist=dealtxt(txt)
newtxtl=sorttxt(txtlist)
showtxt(newtxtl,10)
txtdict={}
main()
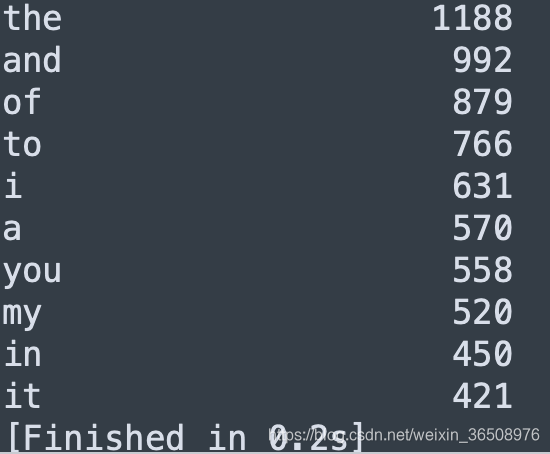
5.词云是设计和统计的结合,也是艺术与计算机科学的碰撞。wordcloud是一款基于Python的词云第三方库,支持对词语数量、背景蒙版、字体颜色等各种细节的设置,试结合上一题构建《Hamlet》的词云效果。
这道题可以参考后面第十章的题目,但是有几个地方不太明白,按照上题词频分析,最多的应该是the才对,可是看到词云,并不是这样的结果,参考了网上的一些内容,了解到“词云图过滤掉大量的低频低质的文本信息”
from wordcloud import WordCloud
import imageio
f=open('Hamlet.TXT','r')
txt=f.read()
f.close()
mask=imageio.imread("13.jpeg")
wordcloud=WordCloud(width=800,height=600,mask=mask).generate(txt)
wordcloud.to_file("1.png")

第九章 Python标准库概览
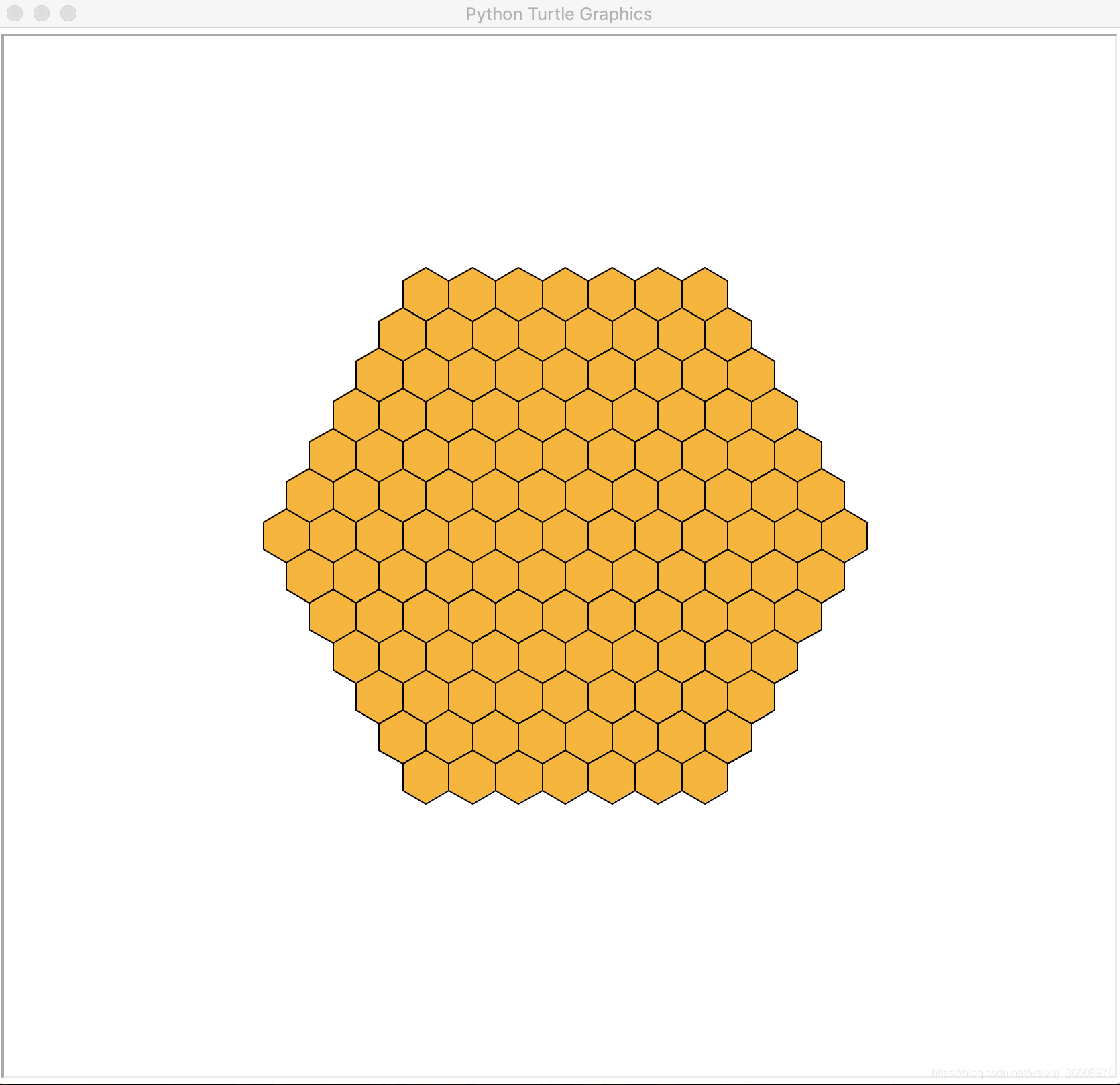
1.使用turtle库绘制一个蜂窝状六边形
这里的蜂窝状,我理解的就是多个六边形组合起来,就像蜂窝一样,遇到了一些问题,写在了代码的备注中了,整体思路就是先完成一个六边形的绘制,然后找到这个六边形旁边一圈六边形的绘制坐标,然后开始画旁边一圈六边形
from turtle import *
#画一个六边形
def onesix(l,x,y):
penup()
goto(x,y)
pendown()
begin_fill()
circle(l,steps=6)
color('black','orange')
end_fill()
#画r圈六边形
def rsix(l,r):
xyset=set()
findxy(r,xyset)
for x,y in xyset:
onesix(l,x,y)
#找到r圈六边形中每个六边形的xy坐标
#数据用集合是因为不重复
def findxy(r,xyset=set()):
x,y=0,0
xyset.add((x,y))
for i in range(r):
xyempty=set()
for x,y in xyset:
xyempty.add((x+(3**0.5)*l,y))
xyempty.add((-x-(3**0.5)*l,y))
xyempty.add((x+(3**0.5)*l/2,y+3*l/2))
xyempty.add((-x-(3**0.5)*l/2,y+3*l/2))
xyempty.add((x+(3**0.5)*l/2,-y-3*l/2))
xyempty.add((-x-(3**0.5)*l/2,-y-3*l/2))
xyset|=xyempty
#tracer(False) #不要动画,不知道为什么用了这句语句后,最后一笔总是写不了,有个六边形会少一个边
speed(100)#速度会很慢
hideturtle()
l=20 #一个六边形的边的长度
r=6 #蜂窝的圈数
rsix(l,r)
done()
2.使用turtle库绘制一朵玫瑰花。
出题的人是认真的吗?
查了一下网上的资料,网上有代码,这里我就不画了。
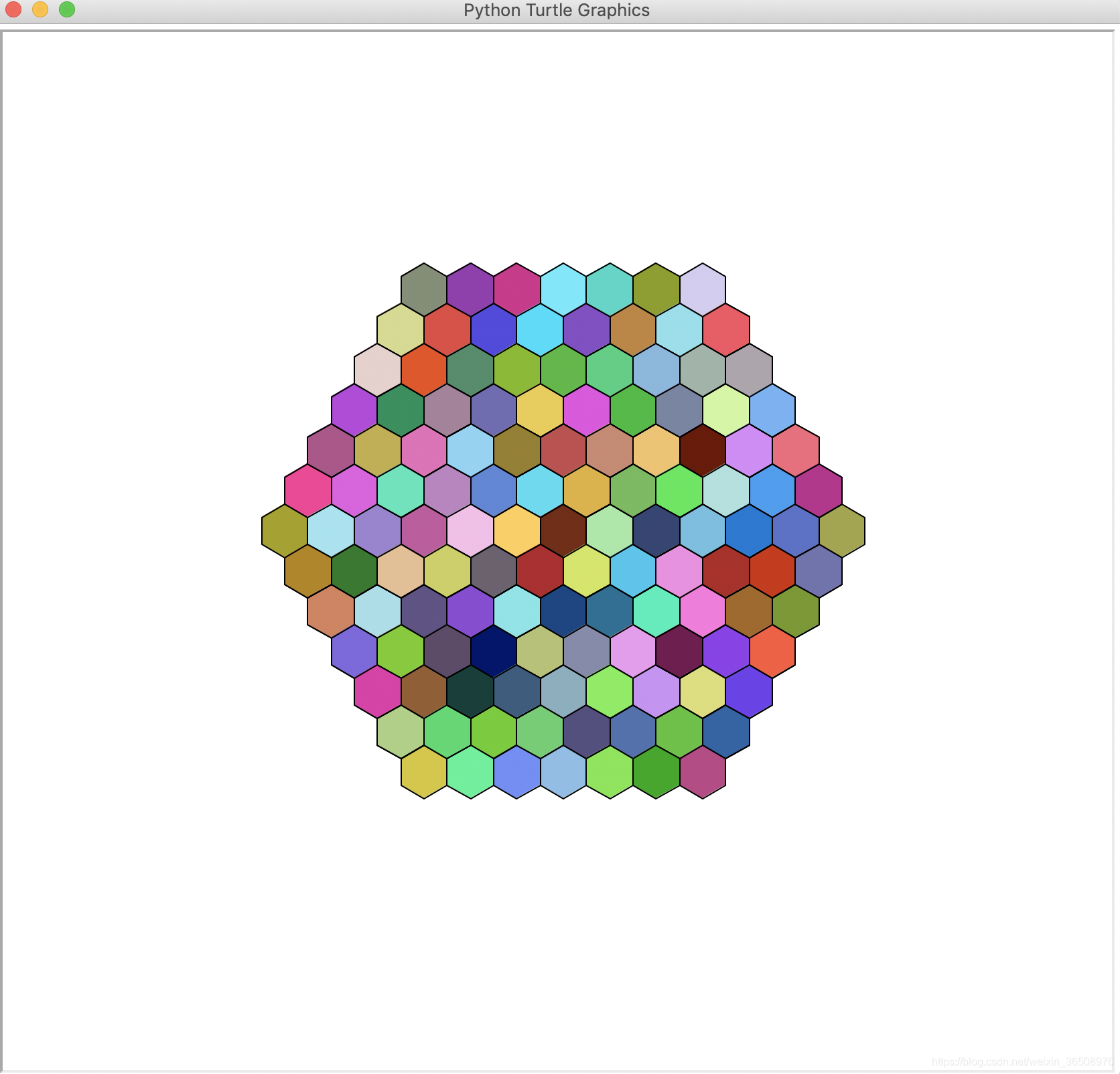
3.使用turtle库绘制一个颜色图谱。
可以用上面9.1的题目,然后在填充颜色的时候,用不同的颜色,这道题对上面9.1做了部分优化,画图的速度变快,不会重复画了
from turtle import *
import random
#画一个六边形
def onesix(l,x,y):
penup()
goto(x,y)
pendown()
begin_fill()
circle(l,steps=6)
rgb=colorrgb()
color('black',rgb)
end_fill()
#产生颜色的随机数
def colorrgb():
r=random.random()
g=random.random()
b=random.random()
return (r,g,b)
#画r圈六边形
def rsix(l,r):
xyset=set()
findxy(r,xyset)
print(xyset)
for x,y in xyset:
onesix(l,x,y)
#找到r圈六边形中每个六边形的xy坐标
#数据用集合是因为不重复
def findxy(r,xyset=set()):
x,y=0,0
xyset.add((x,y))
for i in range(r):
xyempty=set()
for x,y in xyset:
#这里用到了round函数是因为如果不取小数,最后会因为计算的基数不同,两个相同的坐标得出来的值不同
#虽然图的结果差不多,可是会导致集合有重复元素,而导致重复画一个六边形,就像
#51.939439493943901 51.9394394939439
xyempty.add((round(x+(3**0.5)*l,10),round(y,10)))
xyempty.add((round(-x-(3**0.5)*l,10),round(y,10)))
xyempty.add((round(x+(3**0.5)*l/2,10),round(y+3*l/2,10)))
xyempty.add((round(-x-(3**0.5)*l/2,10),round(y+3*l/2,10)))
xyempty.add((round(x+(3**0.5)*l/2,10),round(-y-3*l/2,10)))
xyempty.add((round(-x-(3**0.5)*l/2,10),round(-y-3*l/2,10)))
xyset|=xyempty
#tracer(False) #不要动画,不知道为什么用了这句语句后,最后一笔总是写不了,有个六边形会少一个边
speed(100)#速度会很慢
hideturtle()
l=20 #一个六边形的边的长度
r=6 #蜂窝的圈数
rsix(l,r)
done()
4.使用random库生成一个包含10个0~100之间随机整数的列表。
我不确定是不是我对这道题目理解有问题,是不是太简单了
import random
l=[]
for i in range(10):
l.append(random.randint(0,100))
print(l)
5.利用time库将当前日期时间转化成类似“Sunday, 8.January 2017 11:03PM”的格式。
这里有个问题是日期中4号显示的是04,可是题目中没有前面这个0
import time
print(time.strftime('%A,%d.%B %Y %I:%M%p',time.localtime()))
第十章 Python第三方库概览
1.使用jieba.cut()对“Python是最有意思的编程语言”进行分词,输出结果,并将该迭代器转换为列表类型。
这道题用的cut方法教材上没有讲,教材上用的是lcut方法,直接返回列表类型,通过查阅资料,了解了cut方法返回的是迭代器类型,需要转换为列表类型,否则无法输出
import jieba
s="Python是最有意思的编程语言"
l=jieba.cut(s)
l=list(l)
print(l)下面是我做的一些测试,可以看到使用type方法查看迭代器类型的时候返回的是generator,查询资料了解这是迭代器的一种特殊类型,可以使用next方法,就像pop一样,拿一个出来就少一个,所以最后转换成列表的时候,只剩下两个元素了。
import jieba
s="Python是最有意思的编程语言"
l=jieba.cut(s)#
print(type(l))
print(next(l))
print(next(l))
print(next(l))
print(next(l))
l=list(l)
print(l)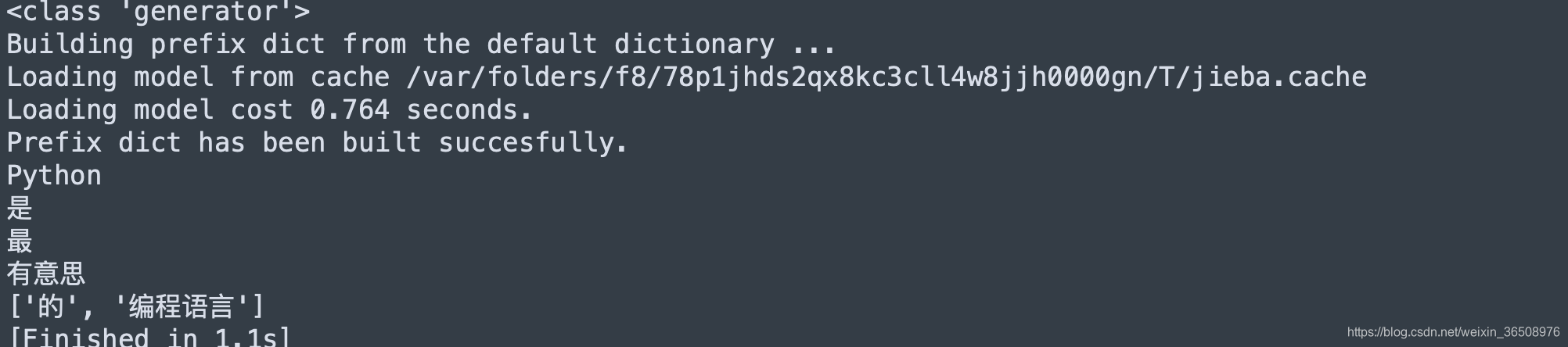
2.使用jieba.cut()对“今天晚上我吃了意大利面”进行分词,输出结果,并使“意大利面”作为一个词出现在结果中。
import jieba
s="今天晚上我吃了意大利面"
jieba.add_word("意大利面")
print(list(jieba.cut(s)))
3.自选一篇报告或者演讲稿,利用jieba分析出其词频排前五的关键词。
在网上找了一篇丘吉尔的演讲稿,只是结果有点尴尬,后来又看了下教材,原来教材上有一段判断是否是一个字,如果是单字的话就直接过滤了,后面我也添加了
import jieba
fr=open("1.txt",'r')
txt=fr.read()
wordl=jieba.lcut(txt)
count={}
for word in wordl:
count[word]=count.get(word,0)+1
countl=list(count.items())
countl.sort(key=lambda x:x[1],reverse=True)
for i in range(5):
print(countl[i])
#print(wordl)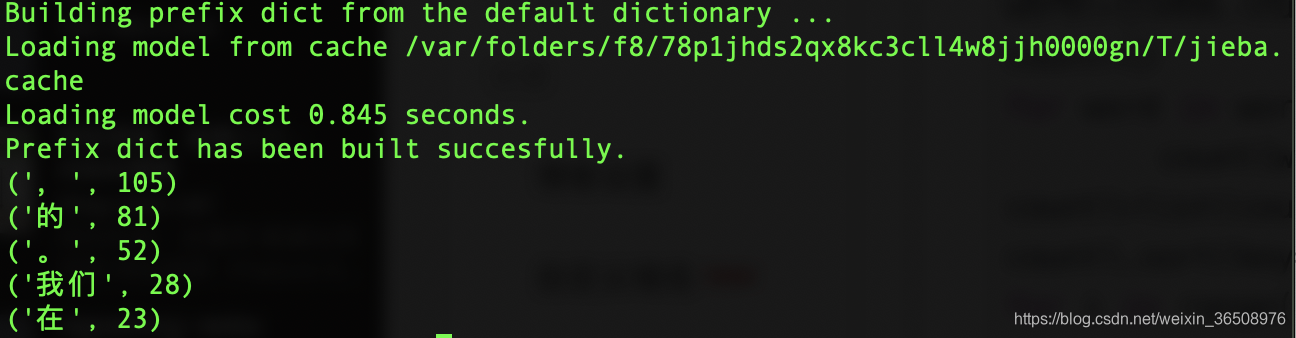
import jieba
fr=open("1.txt",'r')
txt=fr.read()
wordl=jieba.lcut(txt)
count={}
for word in wordl:
if len(word)==1:
continue
count[word]=count.get(word,0)+1
countl=list(count.items())
countl.sort(key=lambda x:x[1],reverse=True)
for i in range(5):
print(countl[i])
#print(wordl)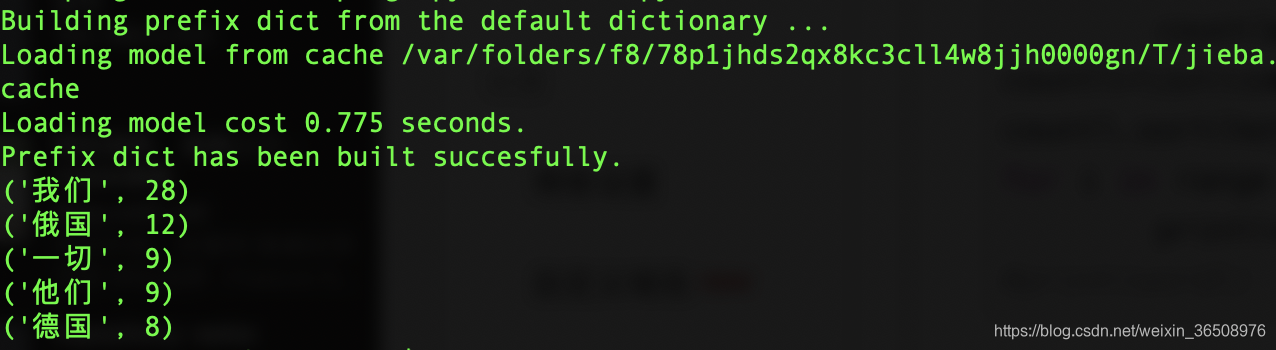
4.选择你最喜欢的小说,统计出场人物词频排名 。
在网上下载了一个射雕英雄传的txt文档,进行词频分析,基本按照教材上例题地讲解
import jieba
fr=open("shediaoyingxiongchuan_jinyong.txt",'r')
excludes=['甚么','说道','一个','自己','师傅','心中','武功','两人',\
'咱们','一声','只见','不知','他们','不是','黄蓉道','郭靖道',\
'功夫','师父','知道','不敢','原来','出来','之中','爹爹','这时','当下','心想','只是']
txt=fr.read()
wordl=jieba.lcut(txt)
count={}
for word in wordl:
if len(word)==1:
continue
count[word]=count.get(word,0)+1
for word in excludes:
del(count[word])
countl=list(count.items())
countl.sort(key=lambda x:x[1],reverse=True)
for i in range(10):
print(countl[i])
fr.close()

5.续上题,将上题结果以词云的方式实现,并尝试美化生成的词云图片。
这里有几点要注意:1、词云会自动过滤单个字,不像jieba
2、教材例题alice梦游仙境中的 from scipy.misc import imread 会出错,查阅资料,可能是因为以后不再提供这个功能,建议使用imageio.imread
3、使用的背影图片,一开始使用的是没有背景的png图片,发现没有效果,查阅资料,改用背景为白色的图片,有效果,猜测可能和词云中背影颜色有关系
4、这里的背景图片采用的是网上的一个例子
import jieba
from wordcloud import WordCloud
import imageio
fr=open("shediaoyingxiongchuan_jinyong.txt",'r')
excludes=['甚么','说道','一个','自己','师傅','心中','武功','两人',\
'咱们','一声','只见','不知','他们','不是','黄蓉道','郭靖道',\
'功夫','师父','知道','不敢','原来','出来','之中','爹爹','这时','当下','心想','只是']
txt=fr.read()
wordl=jieba.lcut(txt)
mask=imageio.imread('13.jpeg')
newtxt=' '.join(wordl)
wordcloud=WordCloud(background_color='white',\
font_path='2.ttf',\
max_font_size=100,\
stopwords=excludes,\
mask=mask,\
).generate(newtxt)
wordcloud.to_file('1.png')
fr.close()

