Linux文件操作
系统调用接口:
1.open
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
int open(const char* pathname,int flags);
int open(const char* pathname,int flags,mode_t mode);
pathname: 要打开或创建的文件
flags: 打开文件时,可以传入多个选项,用下面的一个或多个常量进行或运算,构成flags
O_RDONLY: 只读打开
O_WRONLY: 只写打开
O_RDWR: 读写打开
上述三个常量,必须指定一个且只能指定一个
O_CREAT:若文件不存在,则创建
O_APPEND: 追加写
O_TRUNC: 若文件存在,并且以只写/只读打开,则将清空文件内容
flags参数都是宏,这些标记为其实都是通过位图来传递的。
返回值是文件描述fd,稍后再说
2. read
#include<unistd.h>
ssize_t read(int fd,void *buf,size_t count);


#include<unistd.h>
ssize_t write(int fd,void* buf,size_t count);

文件描述符 fd
void test1()
{
umask(0);
int fd3 = open("love.txt",O_RDONLY|O_CREAT|O_APPEND,0666);
printf("%d\n",fd3);
char buffer[128];
ssize_t s = read(fd3,buffer,sizeof(buffer)-1);
if(s>0)
{
buffer[s] = '\0';
printf("%s\n",buffer);
printf("%d\n",s);
}
close(fd3);
}
当我们打开第一个文件的时候,运行会发现fd 为3 然后再打开多个文件,会发现fd依次为4,5,6,7,…
为什么会有这种现象呢?为什么从3开始呢?
Linux进程默认情况下会有三个缺省打开的文件描述符,分别是:
标准输入: 0 (键盘)
标准输入: 1 (显示器)
标准错误: 1 (显示器)
Linux下:一切皆为文件,这是Linux的哲学。
当文件没有被打开的时候,文件在磁盘中,但当一个文件被打开后,文件会被读取到内存中,一个进程可以打开多个文件,而这些打开的文件操作系统需要很好的管理,所以一个文件打开,会先创建对应的内核数据结构,而操作系统会把一个进程打开的所有文件通过链表连接起来,这样对打开文件的管理变成了对链表的增删查改,
strcut file
{
}

文件的重定向
#include<stdio.h>
#include<unistd.h>
#include<sys/stat.h>
#include<sys/types.h>
#include<fcntl.h>
int main()
{
close(1);
int fd = open("my.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
printf("fd: %d\n",fd);
close(fd);
return 0;
}
看上面的代码,运行会发现没有任何的打印,这是为什么呢? 因为我们close(1),相当于把标准输出流(stdout)关闭了,这时候操作系统会遍历 fd_array[]数组,发现数组下标为1的 file
是空的,这时候操作系统就会自动把1号下标的file
指向我们新打开的文件,这就是重定向的本质!!
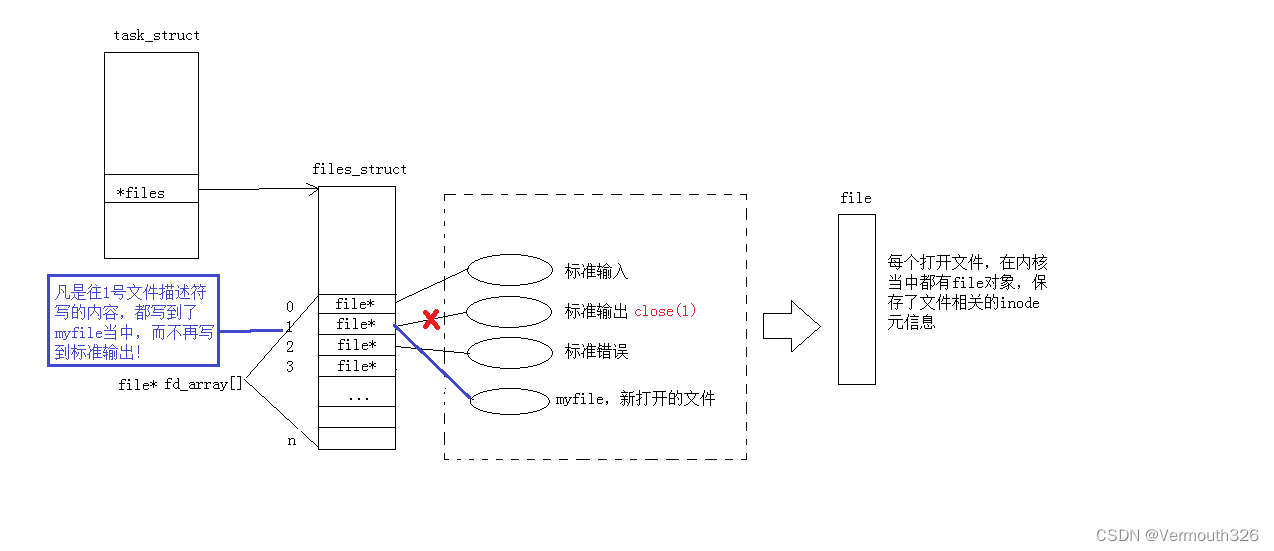
但是这时候既然重定向了,那么说明printf的内容应该会输出到 my.txt的文件中,但是我们打开my.txt文件却发现是空的,这是为什么呢? 这里先卖个关子,只要加上 fflush(stdout) 刷新缓冲区,my.txt里面就有东西了,等下我们将缓冲区的时候再说这个,我们先把重定向讲完:
关于重定向,在这里我们介绍操作系统提供的接口: dup2


int dup2(int oldfd,int newfd);
dup2函数可以让 文件描述符为newfd变为文件描述符为oldfd的一份拷贝,也就是说,newfd会重定向为 oldfd 调用完函数后,只剩下oldfd了
若dup2调用成功则返回新的文件描述符,出错则返回-1.
#include<stdio.h>
#include<unistd.h>
#include<sys/stat.h>
#include<sys/types.h>
#include<fcntl.h>
int main()
{
//close(1);
// int fd = open("my.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
// printf("fd: %d\n",fd);
//
// fflush(stdout);
// close(fd);
int fd = open("my.txt",O_RDONLY);
int dp2 = dup2(fd,0);
if(dp2 < 0 )
{
perror("DUP2");
return 1;
}
char arr[128];
read(0,arr,sizeof(arr));
fprintf(stdout,"%s",arr);
return 0;
}
缓冲区的理解:
什么是缓冲区?怎么理解?
1. 缓冲区的本质就是一段内存
2. 缓冲区的存在能够解放进程的时间,缓冲区集中处理数据刷新以达到减少IO次数,提高整机的效率的目的
缓冲区在哪里?
FILE的结构体里面有对应的缓冲区,而该FILE对应的是语言级别的缓冲区,也就是说每一个文件都有一个专属的fd和他的语言级别的缓冲区。
下面介绍关于刷新策略的问题:
- 无缓冲(立即刷新) :a. 进程退出 b. 用户强制刷新
- 行缓冲 (逐行刷新) : 显示器文件
- 全缓冲 (缓冲区满才刷新):块设备对应的文件(磁盘文件)
一个奇怪的问题:

观察上述代码,当我们执行代码并将其重定向到一个文件中,会发生什么呢?

为什么会有这样的情况呢????
首先,当我们重定向到一个文件时,缓冲区的刷新策略变为了全刷新,也就是缓冲区满,或者进程结束刷新。其次,我们所说的这些缓冲区都是语言级别的缓冲区,而write作为系统调用是没有缓存区的,像printf,fputs fprintf这些函数底层实际上是封装了write并且提供了缓冲区。因此刚开始的printf,fputs,fprintf都只是先写到缓冲区中,并不会直接写到文件中,而write直接写到文件中,那么为什么printf,fputs,fprintf会输出了两次呢?? 我们知道,当我们fork后,会产生子进程和父进程,缓冲区是FILE内部来维护,也就是说是父进程内部的数据区域,当fork时,父子进程会先共享这段数据段,当子进程要结束时,会刷新缓冲区,将缓冲区的内容刷新到文件中并且清空缓冲区,但此时父进程会立刻发生写时拷贝,保留原缓冲区的内容,当父进程结束时,会再刷新一次缓冲区,因此就会刷新两次!
磁盘的存储结构

当进行磁盘的读写时,磁头通过对磁盘的某一个面,某一个磁道的某一个扇区对磁盘进行定位,也就是CHS地址(C:Cylinders),(H:heads),(S:Sector)

而在操作系统中,可以把磁盘看成一个线性的数组,可以用LBA地址进行磁盘的定位。
注意:磁盘的一个扇区的大小是512字节,但是文件系统进行磁盘的访问的基本单位是4kb 也就是8个扇区,为什么这样设计呢? 这样做有两个目的:
- 提高 I/O效率
- 有助于解耦合
操作系统通过对磁盘分块,分组进行分治的管理,这样只要管理好部分就可以管理好全部了。

下面介绍每个磁盘文件系统:
Boot Block: 启动块,大小确定
Data blocks:以块为单位,进行文件数据的保存
inode Table:以128字节为单位,进行inode属性的保存(一般而言,一个文件对应一个独一无二的indoe编号)
struct inode
{
int id;
mode_t mode;
user name;
data d;
…
}(保存文件属性)

ln -s来创建软链接,unlink进行删除软链接
- 硬链接
硬连接并不是一个独立的文件,它和目标文件使用的是同一个inode,相当于在目录中添加一个新的文件名和inode编号的映射关系,而硬连接数,就相当于inode属性中的一个计数器,就是有几个文件名和inode建立了映射关系。