摘要
我们在网上能看到各种文字和符号,那么它们是怎么存储和转化的,还有我们常常提及的UTF-8,为什么都要设置这种编码方式,这里就探讨下。
字符集
字符集:就是各国文字、符号、数字的集合。常见的字符集有:ASCII字符集、GBK字符集、GB18030字符集、Unicode字符集。
ASCII字符集:美国早期制定的字符集,定义了一共128个字符。这些字符有:大小写字母、0到9数字、空格符、退格、换行符、大于小于等字符。内容有限,只能表示128个基本字符,一个字符用一个字节(8bit)表示。
GBK字符集:向下兼容GB2312、其编码范围从8140至FEFE,共23940个码位,共收录了21003个汉字,其中包含了部分日韩文字以及港台BIG-5中的所有汉字。一个字符一般用两个字节表示。
GB18030字符集:由国家定义的汉字编码字符标准,该区间可以容纳161万个码位,目前收录70244个汉字,包含中文、日文、朝鲜语、和中国少数民族文字。内容有限,只能表示中文相关汉字。需要占用1/2/4个字节,兼容ASCII以及GB2312和GBK。也支持Unicode。
ISO8859字符集:由国际化标准组织和国际电工委员会定义的字符集,定义了16个子字符集,比如:ISO8859-1字符集包含了西欧常用的文字、主要是德法两国文字,ISO8859-2字符集包括了东欧常用文字…。虽然说有16个子字符集(其中15个定义了文字),但包含的语言文字有限,仅仅包含了欧洲大部分国家的文字和泰国文字,像中国、日本、韩国等国家的文字都没有包括进去。
Unicode字符集:由一个名为Unicode学术学会的机构制定的字符编码集,该字符集支持所有国家的文字,为每个字符都设定了二进制编码。
编码
字符集确定了能表示的文字符号集合,但还需要确定文字和符号所对应的二进制码,将文字和符号转化为二进制的过程叫做编码。
像ASC11、GBK、GB18030、ISO8859-1等字符集的编码是唯一的,它们既是字符集也是编码,它们定义好了字符对应的唯一二进制码。
但Unicode字符集的编码不是唯一的,即它的同一个字符可以对应不同的二进制码。Unicode有UTF-8、UTF-16、UTF-32编码方案。
其中UTF-8采用可变长字节(1到6个字节)表示文字符号,而UTF-32采用固定长度(4个字节)表示文字符号,UTF-16采用可变长字节(2个或4个字节)表示文字符号。UTF-8有6个字节长度的,是因为后面的类型需要用额外两个标识位区分类型。
看起来好像是UTF-16最省空间。但实际我们日常用的英文数字普通符号等用1个字节表示足够,普通汉字用3个字节表示足够,UTF-8就是这么表示的。而UTF-16无法兼容ASCII码却要用4个字节表示英文,汉字也是需要4个字节表示。具体代码如下:
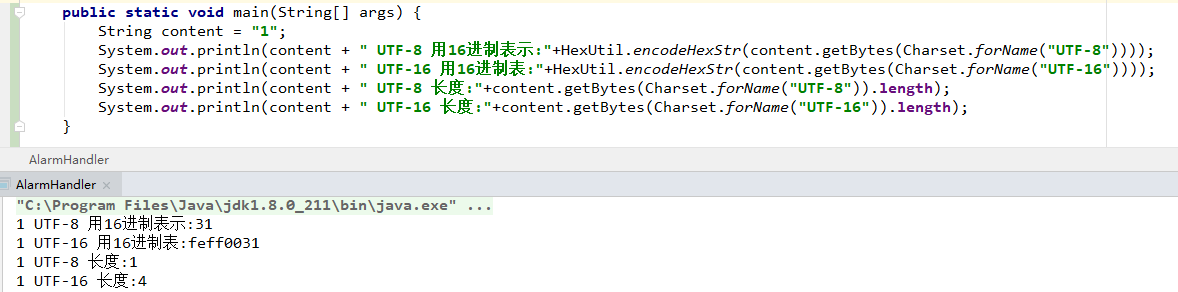
由上图可以看出:数字用UTF-8只占1个字节,而UTF-16要4个字节!
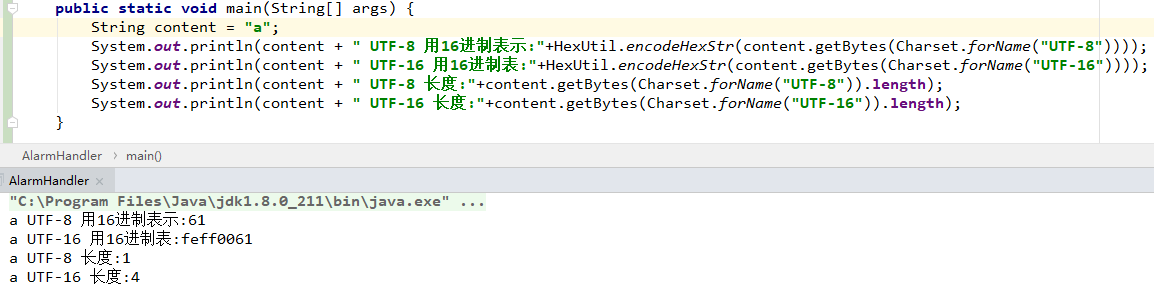
由上图可以看出:英文字母用UTF-8只占1个字节,而UTF-16要4个字节!
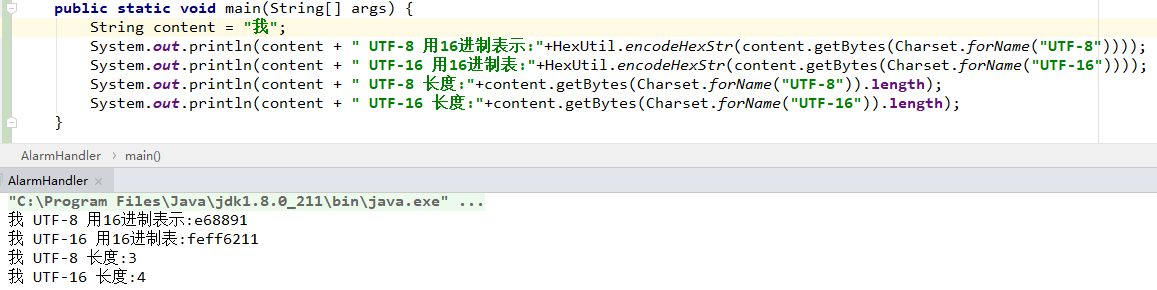
由上图可以看出:汉字用UTF-8占3个字节,而UTF-16要4个字节!
总结
UTF-8相对于其它编码完胜。首先作为unicode字符集的一种编码方式,它可以支持全世界的语言。紧接着,相对于UTF-16和UTF-32,表示日常的文字符号,它还节省空间。所以它就是编码的最优选。