1. 迈向现代C++
1.1 被启用的特性
注意
:弃用并非彻底不能用,只是用于暗示程序员这些特性将从未来的标准中消失,应该尽量避免使用。但是,已弃用的特性依然是标准库的一部分,并且出于兼容性的考虑,大部分特性其实会『永久』保留。
-
不允许字符串常量赋值给
char *
。如果需要用字符串常量赋值和初始化一个
char *
,应该使用
const char *
或者
auto
char *str = "hello world"; //将出现弃用警告
-
C++98异常说明,
unexpected_handler
、
set_unexpected()
等相关特性被弃用,应该使用
noexcept
。
-
auto_ptr被弃用,应该使用
unique_ptr
1.2 与C的兼容性
出于一些不可抗力、历史原因,我们不得不在 C++ 中使用一些 C 语言代码(甚至古老的 C 语言代码),例如 Linux 系统调用。在现代 C++ 出现之前,大部分人当谈及『C 与 C++ 的区别是什么』时,普遍除了回答面向对象的类特性、泛型编程的模板特性外,就没有其他的看法了,甚至直接回答『差不多』,也是大有人在。图 1.2 中的韦恩图大致上回答了 C 和 C++ 相关的兼容情况。
在这里插入图片描述
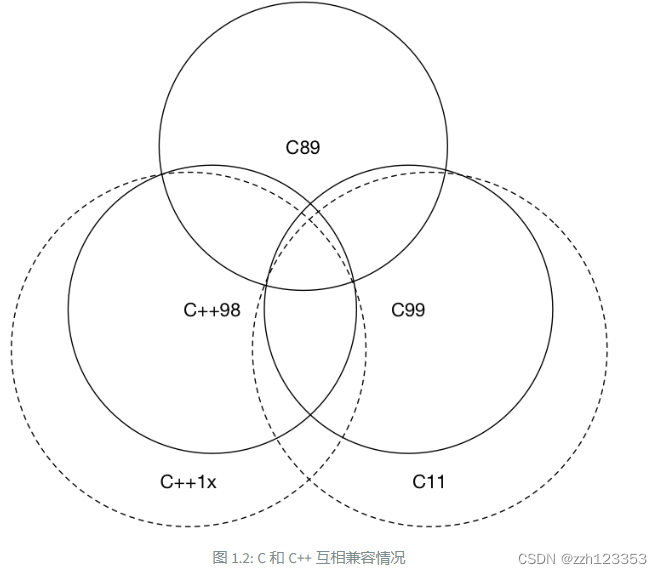
C++不是C的一个超集,这个观念从一开始就是错的!
在编写C++代码的时候,应该尽量避免使用
void
*之类的程序风格,在不得已使用C的时候,应该用
extern "C"
这种特性,将C++代码和C语言的代码分离编译,再统一链接。
// foo.h
#ifdef __cplusplus
extern "C" {
#endif
int add(int x, int y);
#ifdef __cplusplus
}
#endif
// foo.c
int add(int x, int y) {
return x+y;
}
// 1.1.cpp
#include "foo.h"
#include <iostream>
#include <functional>
int main() {
[out = std::ref(std::cout << "Result from C code: " << add(1, 2))](){
out.get() << ".\n";
}();
return 0;
}
应该先使用
gcc
编译C语言的代码
gcc -c foo.c
编译出foo.o的文件,再用
g++/clang++
将C++代码和.o文件进行链接(或者都编译成为.o文件再统一进行链接):
clang++ 1.1.cpp foo.o -std=c++2a -o 1.1
2. 语言可用性的强化
当我们声明、定义一个变量或者常量,对代码进行流程控制、面向对象的功能、模板编程等这些都是运行时之前,可能发生在编写代码或编译器编译代码时的行为。为此,我们通常谈及语言可用性,是指那些发生在运行时之前的语言行为。
2.1 常量
nullptr
nullptr
是为了替代
NULL
。传统C++会把
NULL
、
0
视为同一种东西,这要取决于编译器如何定义
NULL
,有些编译器是直接定义成
0
或者
((void*)0)
。
C++不允许直接将
void *
隐式转换成其他类型,但是如果编译器尝试把
(void*0)
,那么在下面这句代码中:
char *ch = NULL;
没有了
void *
隐式转换的 C++ 只好将
NULL
定义为 0。而这依然会产生新的问题,将 NULL 定义成 0 将导致 C++ 中重载特性发生混乱。考虑下面这两个 foo 函数:
void foo(char*);
void foo(int);
那么
foo(NULL)
将会调用
void foo(int)
,反人类。
因此,C++11引入了
nullptr
专门用来区分空指针和0。
nullptr
类型为
nullptr_t
,能够隐式转换成任何指针或成员指针的类型,也可以和他们之间比较相等或不等。
#include <iostream>
#include <type_traits>
void foo(char *);
void foo(int);
int main() {
if (std::is_same<decltype(NULL), decltype(0)>::value)
std::cout << "NULL == 0" << std::endl;
if (std::is_same<decltype(NULL), decltype((void*)0)>::value)
std::cout << "NULL == (void *)0" << std::endl;
if (std::is_same<decltype(NULL), std::nullptr_t>::value)
std::cout << "NULL == nullptr" << std::endl;
foo(0); // 调用 foo(int)
foo(nullptr); // 调用 foo(char*)
return 0;
}
void foo(char *) {
std::cout << "foo(char*) is called" << std::endl;
}
void foo(int i) {
std::cout << "foo(int) is called" << std::endl;
}
输出:
foo(int) is called
foo(char*) is called
constexpr
C++本身已经具备了常量表达式的概念,如
1+2
,
3x4
这种表达式会产生相同的结果并且没有副作用。如果编译器能够在编译的时候能将这些表达式直接优化并植入程序运行时,能够增加程序的性能。如:
#include <iostream>
#define LEN 10
int len_foo() {
int i = 2;
return i;
}
constexpr int len_foo_constexpr() {
return 5;
}
constexpr int fibonacci(const int n) {
return n == 1 || n == 2 ? 1 : fibonacci(n-1)+fibonacci(n-2);
}
int main() {
char arr_1[10]; // 合法
char arr_2[LEN]; // 合法
int len = 10;
// char arr_3[len]; // 非法
const int len_2 = len + 1;
constexpr int len_2_constexpr = 1 + 2 + 3;
// char arr_4[len_2]; // 非法
char arr_4[len_2_constexpr]; // 合法
// char arr_5[len_foo()+5]; // 非法
char arr_6[len_foo_constexpr() + 1]; // 合法
std::cout << fibonacci(10) << std::endl;
// 1, 1, 2, 3, 5, 8, 13, 21, 34, 55
std::cout << fibonacci(10) << std::endl;
return 0;
}
在上面的例子中,
char arr_4[len_2]
比较迷惑,因为
len_2
已经被定义成了一个常量。
为什么仍然是非法的?这是因为C++标准中数组的长度必须是一个常量表达式,而这个变量是
const
常数,而不是一个常量表达式。因此(现在很多编译器支持这种行为)这是非法行为,我们需要使用C++引入
constexor
特性来解决这个问题;对于
arr_5
来说,C++98之前的编译器无法得知函数在运行期间返回的实际是一个常数,因此也导致了非法行为的产生。
C++11 提供了
constexpr
让用户显式的声明函数或对象构造函数在编译期会成为常量表达式,这个关键字明确的告诉编译器应该去验证
len_foo
在编译期就应该是一个常量表达式。
此外,
constexpr
修饰的函数可以使用递归:
constexpr int fibonacci(const int n) {
return n == 1 || n == 2 ? 1 : fibonacci(n-1)+fibonacci(n-2);
}
从 C++14 开始,
constexpr
函数可以在内部使用局部变量、循环和分支等简单语句,例如下面的代码在 C++11 的标准下是不能够通过编译的:
constexpr int fibonacci(const int n) {
if(n == 1) return 1;
if(n == 2) return 1;
return fibonacci(n-1) + fibonacci(n-2);
}
const和constexpr的作用和区别
对于变量来说
- const表示这个变量无法修改,但是并没有限定这个变量时编译期间的常量还是运行期间的常量
- constexpr表示这个变量只能是编译期间的常量
const int kSize = 1; // 编译期常量
void func()
{
const int kRandomNumber = get_a_random_number(); // 运行期常量
...
...
}
对于 kSize,你既可以用 const 修饰,也可以用 constexpr。但对于 kRandomNumber,你只能用 const。
对于函数来说
- const修饰的一般都是成员函数,用来表示这个函数不会对成员变量产生写的操作
-
constexpr实际是
const expression
,即常量表达式
constexpr int func(int i)
{
return i + 1;
}
int main()
{
int i = 10;
const int ci = 10;
constexpr int cei = 10;
std::array<int, func(i)> arr1; // 编译错误
std::array<int, func(ci)> arr2; // 没问题
std::array<int, func(cei)> arr3; // 没问题
std::array<int, func(10)> arr4; // 没问题
func(i); // 直接使用,也是没问题的
return 0;
}
constexpr
修饰的函数,简单来说,如果传入的参数可以再编译期间算出来,那么这个函数就产生编译时期的值。但是如果传入的参数不能在编译期间算出,那么该关键字修饰的函数,就和普通函数一样,比如上面代码,直接调用了
fun(i)
。不过我们不必因此写两个版本。
2.2 变量及其初始化
if/switch变量声明强化
在传统 C++ 中,变量的声明虽然能够位于任何位置,甚至于
for
语句内能够声明一个临时变量
int
,但始终没有办法在
if
和
switch
语句中声明一个临时的变量。例如:
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> vec = {1, 2, 3, 4};
// 在 c++17 之前
const std::vector<int>::iterator itr = std::find(vec.begin(), vec.end(), 2);
if (itr != vec.end()) {
*itr = 3;
}
// 需要重新定义一个新的变量
const std::vector<int>::iterator itr2 = std::find(vec.begin(), vec.end(), 3);
if (itr2 != vec.end()) {
*itr2 = 4;
}
// 将输出 1, 4, 3, 4
for (std::vector<int>::iterator element = vec.begin(); element != vec.end();
++element)
std::cout << *element << std::endl;
}
在上面的代码中,我们可以看到
itr
这一变量是定义在整个
main()
的作用域内的,这导致当我们需要再次遍历整个
std::vector
时,需要重新命名另一个变量。C++17 消除了这一限制,使得我们可以在
if
(或
switch
)中完成这一操作:
// 将临时变量放到 if 语句内
if (const std::vector<int>::iterator itr = std::find(vec.begin(), vec.end(), 3);
itr != vec.end()) {
*itr = 4;
}
初始化列表
初始化是一个非常重要的语言特性,最常见的就是在对象进行初始化时进行使用。 在传统 C++ 中,不同的对象有着不同的初始化方法,例如普通数组、 POD (Plain Old Data,即没有构造、析构和虚函数的类或结构体) 类型都可以使用
{}
进行初始化,也就是我们所说的初始化列表。 而对于类对象的初始化,要么需要通过拷贝构造、要么就需要使用
()
进行。 这些不同方法都针对各自对象,不能通用。例如:
#include <iostream>
#include <vector>
class Foo {
public:
int value_a;
int value_b;
Foo(int a, int b) : value_a(a), value_b(b) {}
};
int main() {
// before C++11
int arr[3] = {1, 2, 3};
Foo foo(1, 2);
std::vector<int> vec = {1, 2, 3, 4, 5};
std::cout << "arr[0]: " << arr[0] << std::endl;
std::cout << "foo:" << foo.value_a << ", " << foo.value_b << std::endl;
for (std::vector<int>::iterator it = vec.begin(); it != vec.end(); ++it) {
std::cout << *it << std::endl;
}
return 0;
}
为解决这个问题,C++11 首先把初始化列表的概念绑定到类型上,称其为
std::initializer_list
,允许构造函数或其他函数像参数一样使用初始化列表,这就为类对象的初始化与普通数组和 POD 的初始化方法提供了统一的桥梁,例如:
#include <initializer_list>
#include <vector>
#include <iostream>
class MagicFoo {
public:
std::vector<int> vec;
MagicFoo(std::initializer_list<int> list) {
for (std::initializer_list<int>::iterator it = list.begin();
it != list.end(); ++it)
vec.push_back(*it);
}
};
int main() {
// after C++11
MagicFoo magicFoo = {1, 2, 3, 4, 5};
std::cout << "magicFoo: ";
for (std::vector<int>::iterator it = magicFoo.vec.begin();
it != magicFoo.vec.end(); ++it)
std::cout << *it << std::endl;
}
这种构造函数被叫做初始化列表构造函数,具有这种构造函数的类型将在初始化时被特殊关照。
初始化列表除了用在对象构造上,还能将其作为普通函数的形参,例如:
public:
void foo(std::initializer_list<int> list) {
for (std::initializer_list<int>::iterator it = list.begin();
it != list.end(); ++it) vec.push_back(*it);
}
magicFoo.foo({6,7,8,9});
其次,C++11 还提供了统一的语法来初始化任意的对象,例如:
Foo foo2 {3, 4};
结构化绑定
结构化绑定提供了类似其他语言中提供的多返回值的功能。在容器一章中,我们会学到 C++11 新增了
std::tuple
容器用于构造一个元组,进而囊括多个返回值。但缺陷是,C++11/14 并没有提供一种简单的方法直接从元组中拿到并定义元组中的元素,尽管我们可以使用
std::tie
对元组进行拆包,但我们依然必须非常清楚这个元组包含多少个对象,各个对象是什么类型,非常麻烦。
C++17 完善了这一设定,给出的结构化绑定可以让我们写出这样的代码:
#include <iostream>
#include <tuple>
std::tuple<int, double, std::string> f() {
return std::make_tuple(1, 2.3, "456");
}
int main() {
auto [x, y, z] = f();
std::cout << x << ", " << y << ", " << z << std::endl;
return 0;
}
std::tuple 和 std::tie的基本用法
- 定义和初始化
tuple<int,double,string> t3 = {1, 2.0, "3"};
-
访问
可以使用
get<常量表达式>(tuple_name)
来访问或修改tuple的元素(返回引用)
get<0>(t3) = 4;
cout << get<1>(t3) << endl;
-
批量赋值
std::tie会将变量的引用整合成一个tuple,从而实现批量赋值。
int i; double d; string s;
tie(i, d, s) = t3;
cout << i << " " << d << " " << s << endl;
- 还可以使用std::ignore忽略某些tuple中的某些返回值,如
tie(i, ignore, s) = t3;
- 需要注意的是,tie无法直接从初始化列表获得值,比如下面第5行会编译错误。
int i; double d; string s;
tuple<int,double,string> t3 = {1, 2.0, "3"};
tie(i, d, s) = t3;
t3 = {1, 2.0, "3"};
tie(i, d, s) = {1, 2.0, "3"};
2.3 类型推导
在传统 C 和 C++ 中,参数的类型都必须明确定义,这其实对我们快速进行编码没有任何帮助,尤其是当我们面对一大堆复杂的模板类型时,必须明确的指出变量的类型才能进行后续的编码,这不仅拖慢我们的开发效率,也让代码变得又臭又长。
C++11 引入了
auto
和
decltype
这两个关键字实现了类型推导,让编译器来操心变量的类型。这使得 C++ 也具有了和其他现代编程语言一样,某种意义上提供了无需操心变量类型的使用习惯。
auto
使用
auto
进行类型推导的一个最为常见而且显著的例子就是迭代器。你应该在前面的小节里看到了传统 C++ 中冗长的迭代写法:
// 在 C++11 之前
// 由于 cbegin() 将返回 vector<int>::const_iterator
// 所以 it 也应该是 vector<int>::const_iterator 类型
for(vector<int>::const_iterator it = vec.cbegin(); it != vec.cend(); ++it)
//After C++··
#include <initializer_list>
#include <vector>
#include <iostream>
class MagicFoo {
public:
std::vector<int> vec;
MagicFoo(std::initializer_list<int> list) {
// 从 C++11 起, 使用 auto 关键字进行类型推导
for (auto it = list.begin(); it != list.end(); ++it) {
vec.push_back(*it);
}
}
};
int main() {
MagicFoo magicFoo = {1, 2, 3, 4, 5};
std::cout << "magicFoo: ";
for (auto it = magicFoo.vec.begin(); it != magicFoo.vec.end(); ++it) {
std::cout << *it << ", ";
}
std::cout << std::endl;
return 0;
}
一些其他的常见用法:
auto i = 5; // i 被推导为 int
auto arr = new auto(10); // arr 被推导为 int *
从 C++ 20 起,
auto
甚至能用于函数传参,考虑下面的例子:
int add(auto x, auto y) {
return x+y;
}
auto i = 5; // 被推导为 int
auto j = 6; // 被推导为 int
std::cout << add(i, j) << std::endl;
注意:auto 还不能用于推导数组类型:
auto auto_arr2[10] = {arr}; // 错误, 无法推导数组元素类型
2.6.auto.cpp:30:19: error: 'auto_arr2' declared as array of 'auto'
auto auto_arr2[10] = {arr};
decltype
decltype
关键字是为了解决
auto
关键字只能对变量进行类型推导的缺陷而出现的。它的用法和
typeof
很相似:
decltype(表达式)
有时候,我们可能需要计算某个表达式的类型,例如:
auto x = 1;
auto y = 2;
decltype(x+y) z;
你已经在前面的例子中看到
decltype
用于推断类型的用法,下面这个例子就是判断上面的变量
x, y, z
是否是同一类型:
if (std::is_same<decltype(x), int>::value)
std::cout << "type x == int" << std::endl;
if (std::is_same<decltype(x), float>::value)
std::cout << "type x == float" << std::endl;
if (std::is_same<decltype(x), decltype(z)>::value)
std::cout << "type z == type x" << std::endl;
其中,
std::is_same<T, U>
用于判断
T
和
U
这两个类型是否相等。输出结果为:
type x == int
type z == type x
尾返回类型推导
你可能会思考,在介绍
auto
时,我们已经提过
auto
不能用于函数形参进行类型推导,那么
auto
能不能用于推导函数的返回类型呢?还是考虑一个加法函数的例子,在传统 C++ 中我们必须这么写:
template<typename R, typename T, typename U>
R add(T x, U y) {
return x+y;
}
注意:typename 和 class 在模板参数列表中没有区别,在 typename 这个关键字出现之前,都是使用 class 来定义模板参数的。但在模板中定义有嵌套依赖类型的变量时,需要用 typename 消除歧义
这样的代码其实变得很丑陋,因为程序员在使用这个模板函数的时候,必须明确指出返回类型。但事实上我们并不知道
add()
这个函数会做什么样的操作,以及获得一个什么样的返回类型。
在 C++11 中这个问题得到解决。虽然你可能马上会反应出来使用
decltype
推导 x+y 的类型,写出这样的代码:
decltype(x+y) add(T x, U y)
但事实上这样的写法并不能通过编译。这是因为在编译器读到
decltype(x+y)
时,x 和 y 尚未被定义。为了解决这个问题,C++11 还引入了一个叫做尾返回类型(trailing return type),利用
auto
关键字将返回类型后置:
template<typename T, typename U>
auto add2(T x, U y) -> decltype(x+y){
return x + y;
}
令人欣慰的是从 C++14 开始是可以直接让普通函数具备返回值推导,因此下面的写法变得合法:
template<typename T, typename U>
auto add3(T x, U y){
return x + y;
}
可以检查一下类型推导是否正确:
// after c++11
auto w = add2<int, double>(1, 2.0);
if (std::is_same<decltype(w), double>::value) {
std::cout << "w is double: ";
}
std::cout << w << std::endl;
// after c++14
auto q = add3<double, int>(1.0, 2);
std::cout << "q: " << q << std::endl;
decltype(auto)
decltype(auto)
是 C++14 开始提供的一个略微复杂的用法。
简单来说,
decltype(auto)
主要用于对转发函数或封装的返回类型进行推导,它使我们无需显式的指定
decltype
的参数表达式。考虑看下面的例子,当我们需要对下面两个函数进行封装时:
std::string lookup1();
std::string& lookup2();
在 C++11 中,封装实现是如下形式:
std::string look_up_a_string_1() {
return lookup1();
}
std::string& look_up_a_string_2() {
return lookup2();
}
而有了 decltype(auto),我们可以让编译器完成这一件烦人的参数转发:
decltype(auto) look_up_a_string_1() {
return lookup1();
}
decltype(auto) look_up_a_string_2() {
return lookup2();
}
2.4 控制流
if constexpr
正如本章开头出,我们知道了 C++11 引入了
constexpr
关键字,它将表达式或函数编译为常量结果。一个很自然的想法是,如果我们把这一特性引入到条件判断中去,让代码在编译时就完成分支判断,岂不是能让程序效率更高?C++17 将
constexpr
这个关键字引入到
if
语句中,允许在代码中声明常量表达式的判断条件,考虑下面的代码:
#include <iostream>
template<typename T>
auto print_type_info(const T& t) {
if constexpr (std::is_integral<T>::value) {
return t + 1;
} else {
return t + 0.001;
}
}
int main() {
std::cout << print_type_info(5) << std::endl;
std::cout << print_type_info(3.14) << std::endl;
}
在编译时,实际代码就会表现为如下:
int print_type_info(const int& t) {
return t + 1;
}
double print_type_info(const double& t) {
return t + 0.001;
}
int main() {
std::cout << print_type_info(5) << std::endl;
std::cout << print_type_info(3.14) << std::endl;
}
区间for迭代
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> vec = {1, 2, 3, 4};
if (auto itr = std::find(vec.begin(), vec.end(), 3); itr != vec.end()) *itr = 4;
for (auto element : vec)
std::cout << element << std::endl; // read only
for (auto &element : vec) {
element += 1; // writeable
}
for (auto element : vec)
std::cout << element << std::endl; // read only
}
2.5 模板
C++ 的模板一直是这门语言的一种特殊的艺术,模板甚至可以独立作为一门新的语言来进行使用。模板的哲学在于将一切能够在编译期处理的问题丢到编译期进行处理,仅在运行时处理那些最核心的动态服务,进而大幅优化运行期的性能。因此模板也被很多人视作 C++ 的黑魔法之一。
外部模板
传统C++中,模板只有在使用的时候才会被编译器实例化。换句话说,只要在每个编译单元(文件)中编译的代码终于到了被完整定义的模板,都会被实例化。这就产生了重复实例化而导致的变异时间增加。并且,我们没有办法通知编译器不要触发模板的实例化:
template class std::vector<bool>; // 强行实例化
extern template class std::vector<double>; // 不在该当前编译文件中实例化模板
尖括号”>”
在传统C++的编译器中,
>>
会被当成右移运算符进行处理。但实际我们很容易就写出了嵌套模板的代码:
std::vector<std::vector<int>> matrix;
这在传统 C++ 编译器下是不能够被编译的,而 C++11 开始,连续的右尖括号将变得合法,并且能够顺利通过编译。甚至于像下面这种写法都能够通过编译:
template<bool T>
class MagicType {
bool magic = T;
};
// in main function:
std::vector<MagicType<(1>2)>> magic; // 合法, 但不建议写出这样的代码
类型别名模板
在了解类型别名模板之前,需要理解
模板
和
类型
的不同。**模板是用来产生类型的。**在传统C++中,
typedef
可以为类型定义一个新的名称,但是没有办法为模板定义一个新的名称。因为,模板不是类型。
template<typename T, typename U>
class MagicType {
public:
T dark;
U magic;
};
// 不合法
template<typename T>
typedef MagicType<std::vector<T>, std::string> FakeDarkMagic;
C++11引入了
using
这种写法,并且指出传统的
typedef
的功能。
通常我们使用 typedef 定义别名的语法是:typedef 原名称 新名称;,但是对函数指针等别名的定义语法却不相同,这通常给直接阅读造成了一定程度的困难。
typedef int (*process)(void *);
using NewProcess = int(*)(void *);
template<typename T>
using TrueDarkMagic = MagicType<std::vector<T>, std::string>;
int main() {
TrueDarkMagic<bool> you;
}
变长参数模板
模板一直是 C++ 所独有的黑魔法之一。 在 C++11 之前,无论是类模板还是函数模板,都只能按其指定的样子, 接受一组固定数量的模板参数;而 C++11 加入了新的表示方法, 允许任意个数、任意类别的模板参数,同时也不需要在定义时将参数的个数固定。
template<typename... Ts> class Magic;
模板类Magic的对象,能够接受不限制个数的typename作为模板的形式参数,如
class Magic<int,
std::vector<int>,
std::map<std::string,
std::vector<int>>> darkMagic;
既然是任意形式,所以个数为
0
的模板参数也是可以的:
class Magic<> nothing
;。
如果不希望产生的模板参数个数为
0
,可以手动的定义至少一个模板参数:
template<typename Require, typename... Args> class Magic;
变长参数模板也能够调整到模板函数上。传统C中的
printf
函数,虽然也能达成不定个数的形参的调用,但是并非类别安全。而茶untongdeC++11除了能定义类别安全的变长参数函数外,还可以使类似
printf
的函数能自然地处理非自带类别的对象。 除了在模板参数中能使用
...
表示不定长模板参数外, 函数参数也使用同样的表示法代表不定长参数, 这也就为我们简单编写变长参数函数提供了便捷的手段,例如:
template<typename... Args> void printf(const std::string &str, Args... args);
- 类别安全
void printf(const char* s) {
while (*s) {
if (*s == '%' && *++s != '%')
throw std::runtime_error("invalid format string: missing arguments");
std::cout << *s++;
}
}
template<typename T, typename... Args>
void printf(const char* s, const T& value, const Args&... args) {
while (*s) {
if (*s == '%' && *++s != '%') {
std::cout << value;
return printf(++s, args...);
}
std::cout << *s++;
}
throw std::runtime_error("extra arguments provided to printf");
}
对于传递给可变模板版本的所有参数,它们的类型在编译时是已知的。这些知识保存在函数中。然后,每个对象都被传递给cout,并带有严重过载的运算符<<。对于传递的每个类型,都有一个单独的此函数重载。换句话说,如果你传递一个int,它调用的是ostream::operator<<(int);如果你传递了一个double,它调用了ostream:::operator<(double)。因此,该类型再次被保留。这些函数中的每一个都专门用于以适当的方式处理每一种类型。这就是类型安全。
那么我们定义了变长的模板参数,如何对参数进行解包呢?
首先,我们可以使用
sizeof...
来计算参数的个数,:
template<typename... Ts>
void magic(Ts... args) {
std::cout << sizeof...(args) << std::endl;
}
我们可以传递任意个参数给
magic
函数:
magic(); // 输出0
magic(1); // 输出1
magic(1, ""); // 输出2
其次,对参数进行解包,到目前为止还没有一种简单的方法能够处理参数包,但有两种经典的处理手法:
1. 递归模板函数
递归是非常容易想到的一种手段,也是最经典的处理方法。这种方法不断递归地向函数传递模板参数,进而达到递归遍历所有模板参数的目的:
#include <iostream>
template<typename T0>
void printf1(T0 value) {
std::cout << value << std::endl;
}
template<typename T, typename... Ts>
void printf1(T value, Ts... args) {
std::cout << value << std::endl;
printf1(args...);
}
int main() {
printf1(1, 2, "123", 1.1);
return 0;
}
2. 变参模板展开
你应该感受到了这很繁琐,在 C++17 中增加了变参模板展开的支持,于是你可以在一个函数中完成
printf
的编写:
template<typename T0, typename... T>
void printf2(T0 t0, T... t) {
std::cout << t0 << std::endl;
if constexpr (sizeof...(t) > 0) printf2(t...);
}
3. 初始化列表展开
递归模板函数是一种标准的做法,但缺点显而易见的在于必须定义一个终止递归的函数。
这里介绍一种使用初始化列表展开的黑魔法:
template<typename T, typename... Ts>
auto printf3(T value, Ts... args) {
std::cout << value << std::endl;
(void) std::initializer_list<T>{([&args] {
std::cout << args << std::endl;
}(), value)...};
}
在这个代码中,额外使用了 C++11 中提供的初始化列表以及 Lambda 表达式的特性)。
通过初始化列表,
(lambda 表达式, value)...
将会被展开。由于逗号表达式的出现,首先会执行前面的 lambda 表达式,完成参数的输出。 为了避免编译器警告,我们可以将
std::initializer_list
显式的转为
void
。
折叠表达式
C++ 17 中将变长参数这种特性进一步带给了表达式,考虑下面这个例子:
#include <iostream>
template<typename ... T>
auto sum(T ... t) {
return (t + ...);
}
int main() {
std::cout << sum(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) << std::endl;
}
非类型模板参数推导
前面我们主要提及的是模板参数的一种形式:类型模板参数。
template <typename T, typename U>
auto add(T t, U u) {
return t+u;
}
其中模板的参数
T
和
U
为具体的类型。 但还有一种常见模板参数形式可以让不同字面量成为模板参数,即非类型模板参数:
template <typename T, int BufSize>
class buffer_t {
public:
T& alloc();
void free(T& item);
private:
T data[BufSize];
}
buffer_t<int, 100> buf; // 100 作为模板参数
在这种模板参数形式下,我们可以将
100
作为模板的参数进行传递。 在 C++11 引入了类型推导这一特性后,我们会很自然的问,既然此处的模板参数 以具体的字面量进行传递,能否让编译器辅助我们进行类型推导, 通过使用占位符
auto
从而不再需要明确指明类型? 幸运的是,C++17 引入了这一特性,我们的确可以
auto
关键字,让编译器辅助完成具体类型的推导, 例如:
template <auto value> void foo() {
std::cout << value << std::endl;
return;
}
int main() {
foo<10>(); // value 被推导为 int 类型
}
2.6 面向对象
委托构造
C++11 引入了委托构造的概念,这使得构造函数可以在同一个类中一个构造函数调用另一个构造函数,从而达到简化代码的目的:
#include <iostream>
class Base {
public:
int value1;
int value2;
Base() {
value1 = 1;
}
Base(int value) : Base() { // 委托 Base() 构造函数
value2 = value;
}
};
int main() {
Base b(2);
std::cout << b.value1 << std::endl;
std::cout << b.value2 << std::endl;
}
继承构造
在传统C++中,构造函数如果需要继承是要将参数一一传递的,会导致效率低下。
C++11引入了关键字
using
引入了继承构造的概念
#include <iostream>
class Base {
public:
int value1;
int value2;
Base() {
value1 = 1;
}
Base(int value) : Base() { // 委托 Base() 构造函数
value2 = value;
}
};
class Subclass : public Base {
public:
using Base::Base; // 继承构造
};
int main() {
Subclass s(3);
std::cout << s.value1 << std::endl;
std::cout << s.value2 << std::endl;
}
显式虚函数重载
在传统 C++ 中,经常容易发生意外重载虚函数的事情。例如:
struct Base {
virtual void foo();
};
struct SubClass: Base {
void foo();
};
SubClass::foo
可能并不是程序员尝试重载虚函数,只是恰好加入了一个具有相同名字的函数。另一个可能的情形是,当基类的虚函数被删除后,子类拥有旧的函数就不再重载该虚拟函数并摇身一变成为了一个普通的类方法,这将造成灾难性的后果。
C++11 引入了
override
和
final
这两个关键字来防止上述情形的发生。
-
override
当重载虚函数时,引入
override
关键字将显式的告知编译器进行重载,编译器将检查基函数是否存在这样的虚函数,否则将无法通过编译:
struct Base {
virtual void foo(int);
};
struct SubClass: Base {
virtual void foo(int) override; // 合法
virtual void foo(float) override; // 非法, 父类没有此虚函数
};
-
final
final
则是为了防止类被继续继承以及终止虚函数继续重载引入的。
struct Base {
virtual void foo() final;
};
struct SubClass1 final: Base {
}; // 合法
struct SubClass2 : SubClass1 {
}; // 非法, SubClass1 已 final
struct SubClass3: Base {
void foo(); // 非法, foo 已 final
};
显式禁用默认函数
在传统 C++ 中,如果程序员没有提供,编译器会默认为对象生成默认构造函数、 复制构造、赋值算符以及析构函数。 另外,C++ 也为所有类定义了诸如
new delete
这样的运算符。 当程序员有需要时,可以重载这部分函数。
这就引发了一些需求:无法精确控制默认函数的生成行为。 例如禁止类的拷贝时,必须将复制构造函数与赋值算符声明为
private
。 尝试使用这些未定义的函数将导致编译或链接错误,则是一种非常不优雅的方式。
并且,编译器产生的默认构造函数与用户定义的构造函数无法同时存在。 若用户定义了任何构造函数,编译器将不再生成默认构造函数, 但有时候我们却希望同时拥有这两种构造函数,这就造成了尴尬。
C++11 提供了上述需求的解决方案,允许显式的声明采用或拒绝编译器自带的函数。 例如:
class Magic {
public:
Magic() = default; // 显式声明使用编译器生成的构造
Magic& operator=(const Magic&) = delete; // 显式声明拒绝编译器生成构造
Magic(int magic_number);
}
强类型枚举
在传统 C++中,枚举类型并非类型安全,枚举类型会被视作整数,则会让两种完全不同的枚举类型可以进行直接的比较(虽然编译器给出了检查,但并非所有),
甚至同一个命名空间中的不同枚举类型的枚举值名字不能相同
,这通常不是我们希望看到的结果。
C++11 引入了枚举类(enumeration class),并使用
enum class
的语法进行声明:
enum class new_enum : unsigned int {
value1,
value2,
value3 = 100,
value4 = 100
};
这样定义的枚举实现了类型安全,首先他不能够被隐式的转换为整数,同时也不能够将其与整数数字进行比较, 更不可能对不同的枚举类型的枚举值进行比较。但相同枚举值之间如果指定的值相同,那么可以进行比较:
if (new_enum::value3 == new_enum::value4) {
// 会输出
std::cout << "new_enum::value3 == new_enum::value4" << std::endl;
}
在这个语法中,枚举类型后面使用了冒号及类型关键字来指定枚举中枚举值的类型,这使得我们能够为枚举赋值(未指定时将默认使用
int
)。
而我们希望获得枚举值的值时,将必须显式的进行类型转换,不过我们可以通过重载 << 这个算符来进行输出,可以收藏下面这个代码段:
#include <iostream>
template<typename T>
std::ostream& operator<<(
typename std::enable_if<std::is_enum<T>::value,
std::ostream>::type& stream, const T& e)
{
return stream << static_cast<typename std::underlying_type<T>::type>(e);
}
这时,下面的代码将能够被编译:
std::cout << new_enum::value3 << std::endl
3. 语言运行期的强化
3.1 Lambda表达式
Lambda表达式实际上就是提供了一个类似于匿名函数的特性,而匿名函数则是在需要一个函数,但是又不想费力去命名一个函数的情况下使用的。
基础
Laambda表达式一般形式
[捕获列表](参数列表) mutable(可选) 异常属性-> 返回类型{
//函数体
}
捕获列表
捕获列表可以理解为参数的一种类型,Lambda表达式内部函数体在默认情况下是无法使用函数体外部的变量的,这个时候捕获列表可以起到传递外部数据的作用。
-
值捕获
值捕获的前提是变量可以拷贝,不同之处是,被捕获的变量在Lambda表达式
创建时拷贝,而非调用时拷贝
:
void lambda_value_capture() {
int value = 1;
auto copy_value = [value] {
return value;
};
value = 100;
auto stored_value = copy_value();
std::cout << "stored_value = " << stored_value << std::endl;
// 这时, stored_value == 1, 而 value == 100.
// 因为 copy_value 在创建时就保存了一份 value 的拷贝
}