视频主页:
http://speech.ee.ntu.edu.tw/~tlkagk/courses_DLHLP20.html
B站观看(对应P7-P8):
https://www.bilibili.com/video/BV1RE411g7rQ
资料汇总:
度盘
密码: 4v5i
(以上资料来源于网络)
以下内容只是对上述资料进行提炼,建议观看原视频,感谢李宏毅老师和其团队的辛苦付出!
系列文章索引:
深度学习与人类语言处理 李宏毅2020课程精华提要(1)模型的输入与输出
深度学习与人类语言处理 李宏毅2020课程精华提要(2)模型的构成之Seq-to-Seq角度
深度学习与人类语言处理 李宏毅2020课程精华提要(3)模型的构成之HMM角度
深度学习与人类语言处理 李宏毅2020课程精华提要(4)模型对齐(Alignment)
深度学习与人类语言处理 李宏毅2020课程精华提要(5)语言模型
前言
语音识别模型有两个基本问题:
Decoding问题
和
Training问题
,Decoding问题是
解码
问题,给定模型参数和输入的情况下,确定模型的输出序列,Training问题是模型
参数的学习问题
,给定模型输入输出的情况下,怎么学习出模型的参数,用公式表达,如下图所示:

也就是这里面有一个关键的步骤就是求解:P(Y|X)。
LAS
的P(Y|X)求解过程比较简单,直接计算即可,RNN的长度取决于句子的长度,每个RNN的输出都是one-hot 独热编码,具体代码参见
链接文章
的Spell模块。LAS的求解直接使用公式即可:
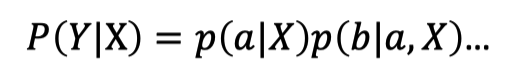
而HMM、CTC和RNN-T是无法直接求解P(Y|X)的,需要将输出的向量维度与输入向量保持一致才能计算,这里就涉及一个Alignment(对齐)操作,最简单暴力的方法就是穷举所有可能的对齐方式,然后求和:
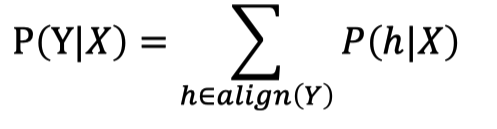
作者在这里抛出了四个问题,非常值得我们思考,这四个问题也是后续作者讲解课程的顺序:

问题1:如何枚举所有可能的对齐方式
HMM、CTC和RNN-T异同点如下图所示,也就是这些模型对齐方式都是在从左往下“走”(为了保证顺序),“走”需要遵守一定的规则,如是否要插入“𝜙”,能否重复token等等,当然,所有的模型都需要按照一定顺序遍历完所有的toekn。
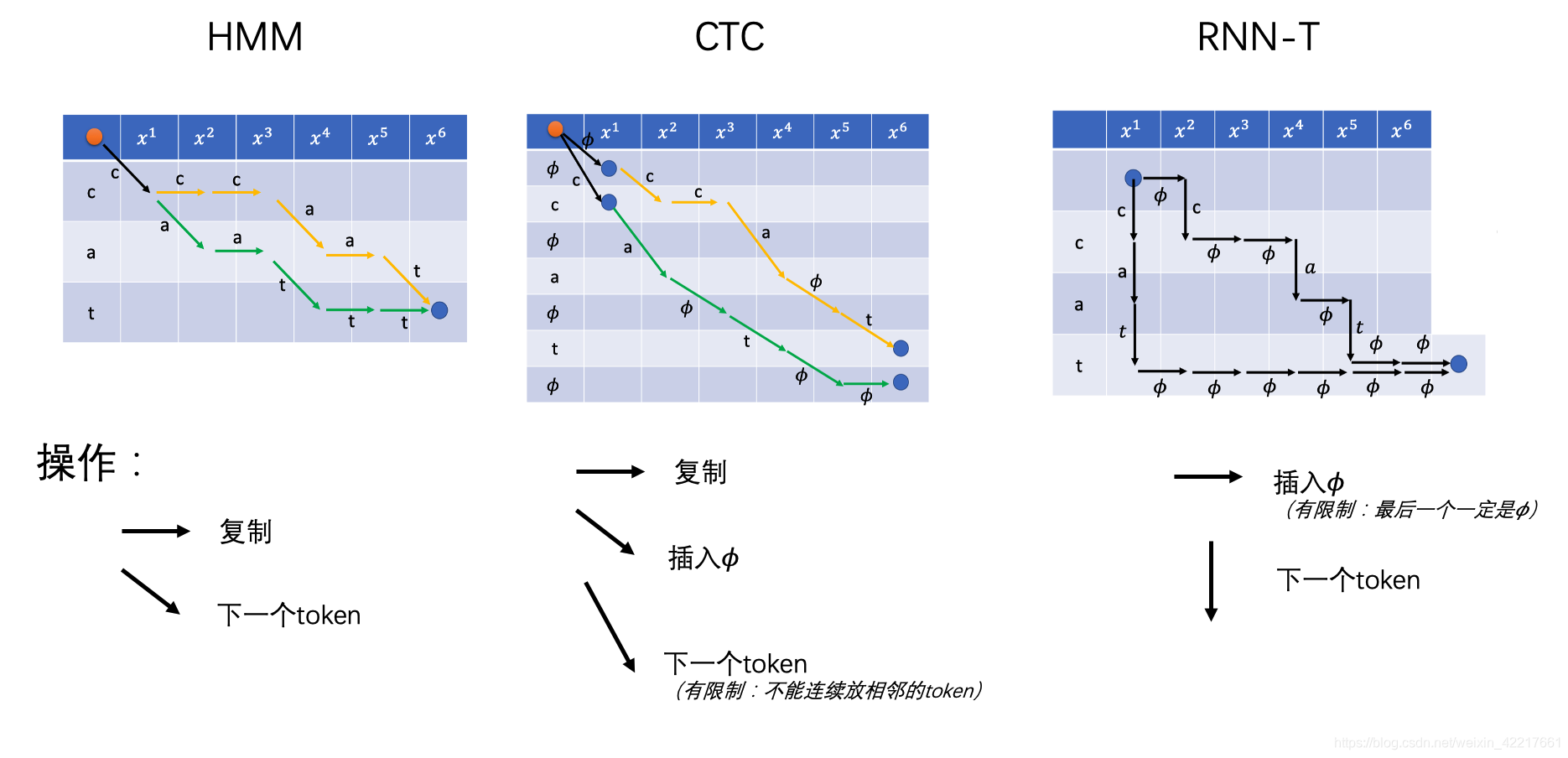
如果用状态机来表示的话,就是如下所示:
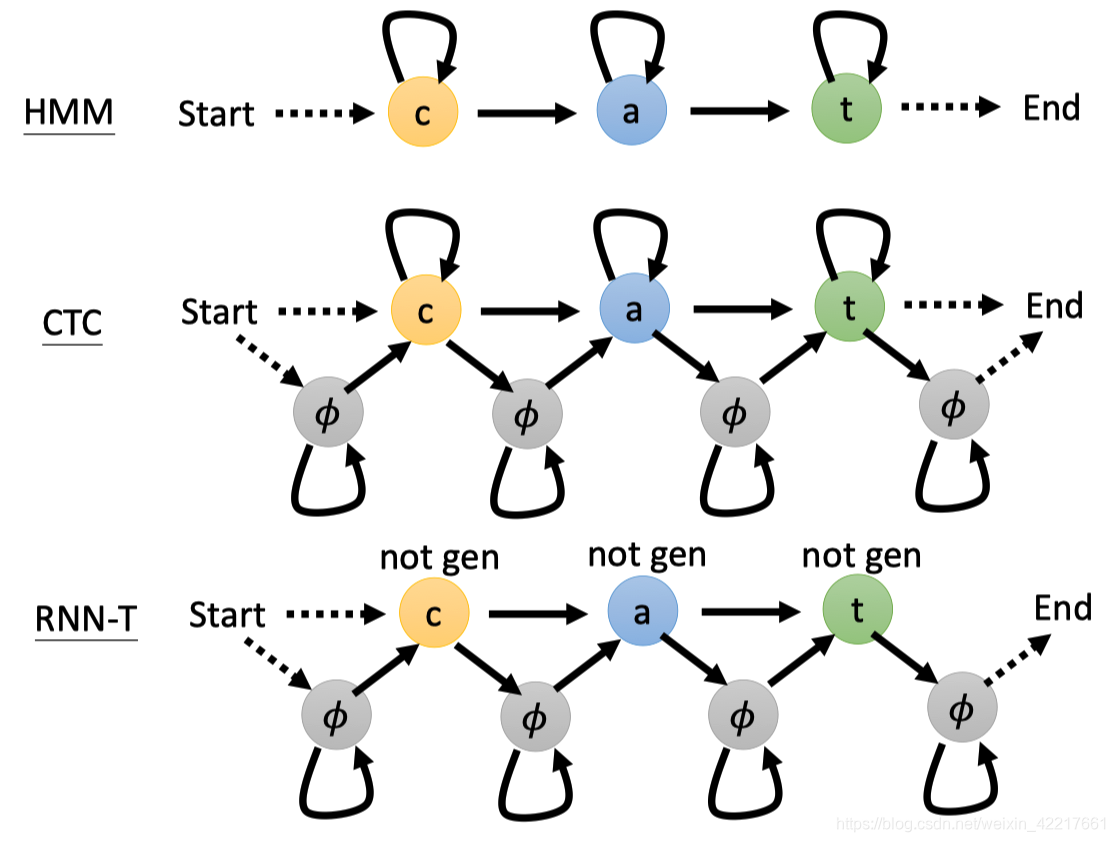
问题2:如何对所有可能的对齐方式求和
这部分要解决的问题是:
给定一个token sequence的情况下(ℎ = 𝜙 c 𝜙 𝜙 a 𝜙 t 𝜙 𝜙),计算总概率是多少?
这部分视频链接直接可以跳到
视频
,这部分比较难,作者也反复说了要
多看几遍
。
建议直接看视频,我这里简单总结下:其实这里本质上是一个
动态规划
的思路,每一个格子在确定值的时候都取决于左侧的格子和上侧的格子,如果我们要计算右下角的值,我们需要走完所有的格子一遍就行了。
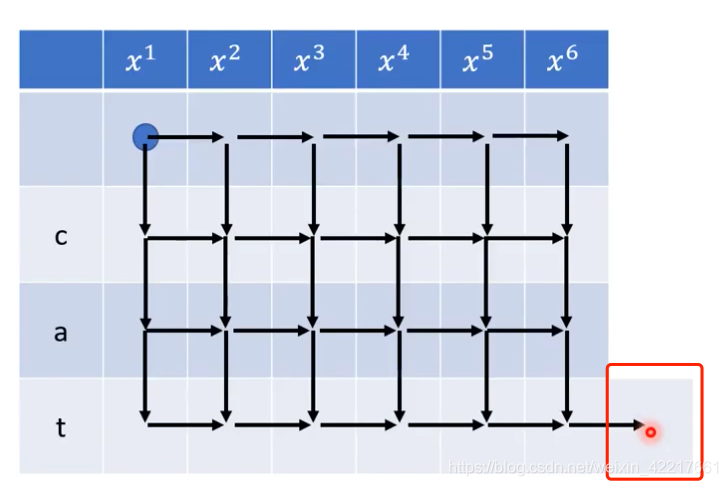
最终红色方块这里的值就是最终
概率之和
,如果穷举所有可能的值再求和,复杂度为N^T(N为token的长度,T是acoustic feature的大小),而这里的动态规划算法能将复杂度降低到N*T,大大降低了求和的计算量。
问题3:如何对求和之后式子求微分
这里要解决的问题是:在训练的过程中,如何求和模型的参数,这里使用梯度下降算法。
上一个问题引入了𝛼参数,这里又引入了𝛽的参数,笔者认为这里与HMM的向前算法和向后概率的有些类似,都是用近似来解决复杂度过高的问题。
这里我也不太会,就不总结了。建议直接看原视频,或者看一些HMM向前向后算法的资料(比如:李琳山老师的)。
问题4:有了模型参数后,如何推断、解码?

实际上,使用最大分数的alignment近似代替sum。
总结
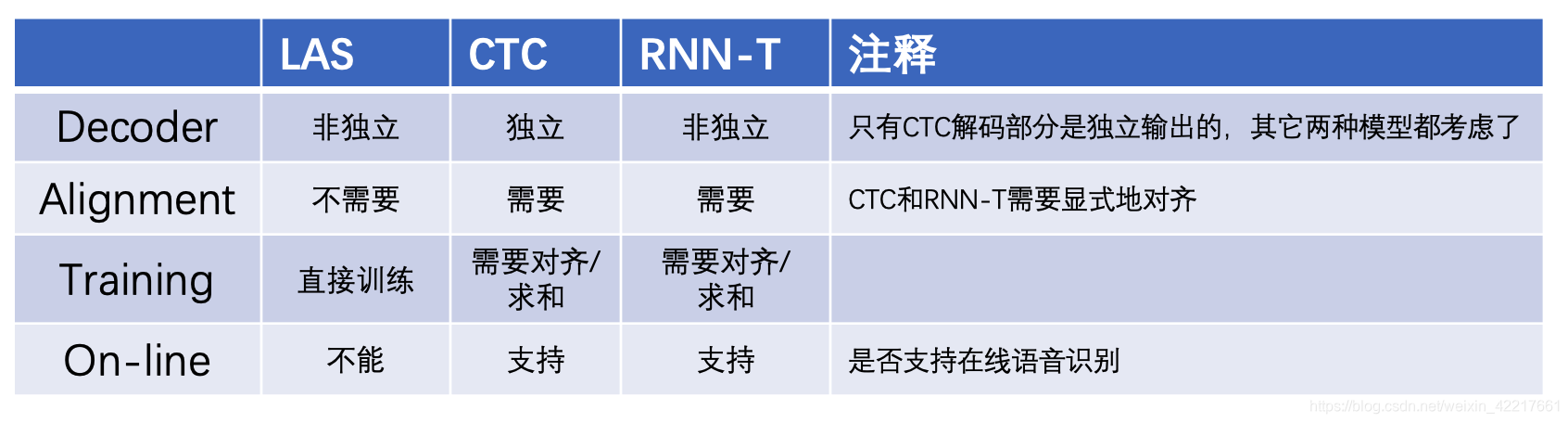
最终作者从四个方面总结了三个模型的异同点,包括:Decoder(解码阶段)、Alignment(是否需要标签对齐)、Training(训练阶段)和On-line(是否支持在线语音)。