目录
索引
-
相当于数组下标索引,根据索引在数据库中进行搜索,大大提高查询效率。
但创建索引也需要一定的时间和空间的开销,并且会拖慢增删改的效率。
-
数据的插入、删除会造成索引更新,索引的更新操作也需要消耗时间性能。
-
MySQL数据库插件式的设计,每种索引在不同的存储引擎中的实现可能不同。
存储引擎:MySQL对数据库中的数据进行增删改查等操作的实现方案。
MySQL经典的两种存储引擎:MyISAM、InnoDB。
MyISAM:MySQL5.5之前的默认存储引擎,不支持事务,但性能比较高。
InnoDB:MySQL5.5之后的默认存储引擎,支持事务,但性能不如MyISAM。
-
通常为常用于查询搜索的字段创建索引。
-
主键约束 primary key、唯一性约束 unique、外键约束 foreign key 本身就是索引,也可以另外创建普通索引。
-
索引不一定会提高查询效率。查询时需要在条件中命中索引列,没有命中就不会提高查询效率。
-
索引不一定会被使用。并不是使用带有索引的字段进行查询时,索引都会起作用。
如:name列创建了索引,但使用
where name is null进行条件查询,就不会使用该列的索引,因为索引不会保存null的信息。
explain 查看sql语句的信息
explain sql语句可以分析sql语句的执行逻辑、顺序,以及是否使用索引、对记录进行操作时扫描的行数等信息。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bLpf5cVo-1655904757931)(C:/Users/Hong/AppData/Roaming/Typora/typora-user-images/image-20220609175249749.png)]](http://xfxia.com/wp-content/uploads/2023/03/ac3ca3ee71a6412092b4906976bda34f.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HBDIuXgD-1655904757933)(C:/Users/Hong/AppData/Roaming/Typora/typora-user-images/image-20220609175911337.png)]](http://xfxia.com/wp-content/uploads/2023/03/cc703e2edcf246819327ad15b932605e.png)
.ibd文件存储表的数据和索引。
.frm文件存储表的定义和结构。
mysql8.0后,合并为.ibd文件。
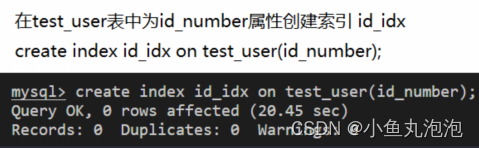
创建索引
主键约束 primary key、唯一性约束 unique、外键约束 foreign key 的字段本身即是索引,其他字段可创建普通索引。
创建普通索引:create index 索引名 on 表名(字段名);
删除索引
删除索引:drop index 索引名 on 表名;
查看索引
查看表中的全部索引:show index from 表名;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UYPRlvk3-1655904757934)(C:/Users/Hong/AppData/Roaming/Typora/typora-user-images/image-20220609180427426.png)]](http://xfxia.com/wp-content/uploads/2023/03/ff8e99afb7e64412a9acf056ad1e87da.png)
索引的命中情况
索引不一定会被使用,即被“命中”。并不是使用带有索引的字段进行查询时,索引都会起作用。
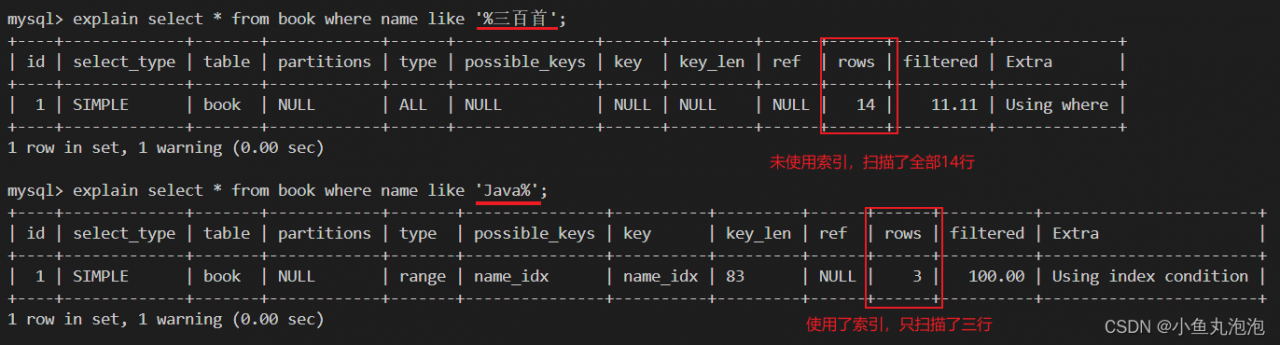
查询语句中使用LIKE关键字
在查询语句中使用LIKE关键字进行查询时,如果匹配字符串的第一个字符为%,索引不会被使用。如果%不是在第一个位置,索引就会被使用。
-- 查询like关键字是否使用索引
create index name_idx on book(name);
show index from book;
explain select * from book where name like '%三百首'; -- 匹配字符串的第一个字符是%,不使用索引
explain select * from book where name like 'Java%'; -- 匹配字符串的第一个字符串不是%,使用索引
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ig75vB3q-1655904757936)(C:/Users/Hong/AppData/Roaming/Typora/typora-user-images/image-20220622154621151.png)]](http://xfxia.com/wp-content/uploads/2023/03/9c466b2002bd499491ed96a9d722d2a2.png)
查询语句中使用复合索引
复合索引(多列索引)是将表的多个字段组合创建为一个索引。
复合索引遵循最左匹配原则:根据创建索引的字段顺序,从左往右进行匹配,左边的优先匹配。
在条件查询中,只有使用了复合索引中的第一个索引字段,该复合索引才会被使用。
查询语句中使用OR关键字
查询语句只有OR关键字时,如果OR前后两个条件的列都是索引,那么查询中将使用索引。如果OR前后有一个条件的列不是索引,那么查询中将不使用索引。
MySQL索引的数据结构
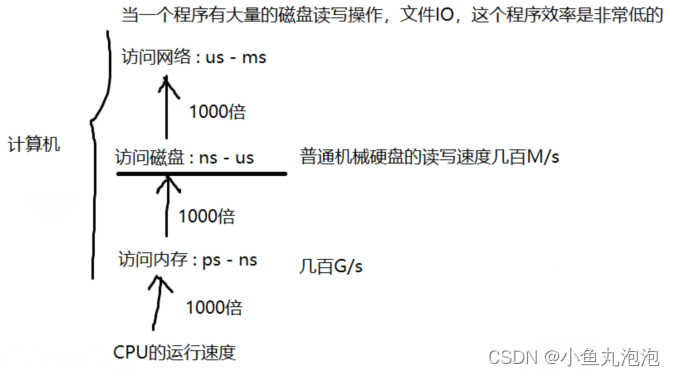
高效查询数据常用的数据结构:二分搜索树BST、红黑树RBTree、哈希表。
RBTree:查找的时间复杂度为O(logN),但当数据量很大时,由于二叉树的每个结点最多有两棵子树,故RBTree的深度很高。而数据库中的数据存储在磁盘上,每访问一个二叉树的结点就要进行一次磁盘读写IO操作,导致整体效率低下。
哈希表:理论上查找的时间复杂度为O(1),常数时间。但通常哈希表用于查找数据是否等于指定的数据,无法处理区间范围内的查询操作。
故MySQL索引的实现不使用以上几种数据结构。
MySQL的索引基于 B+树 实现。
B+树 即 N叉搜索树。
B树家族是严格的平衡树。左右子树高度差为0,所有子树完全等高。
引入N叉搜索树后,相较于BST二叉树来说,一层可存放更多结点数据,能够大大降低树的高度。
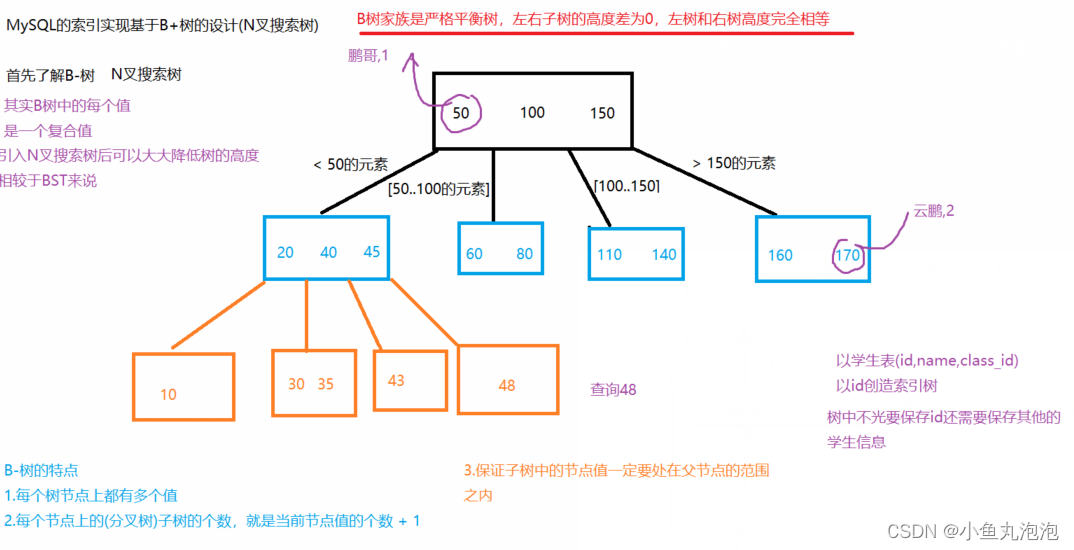
B-树
-
B-树中的每个结点都存放了多个值。
-
树中结点根据其中多个值的区间进行分叉。对于每个结点,分叉子树个数 = 当前结点值个数 + 1。
-
保证子结点中的值一定要在父结点分叉的范围内。
-
B-树使用聚簇索引,树中每个结点值不仅存储了主键id,还存储了该条记录的所有信息。
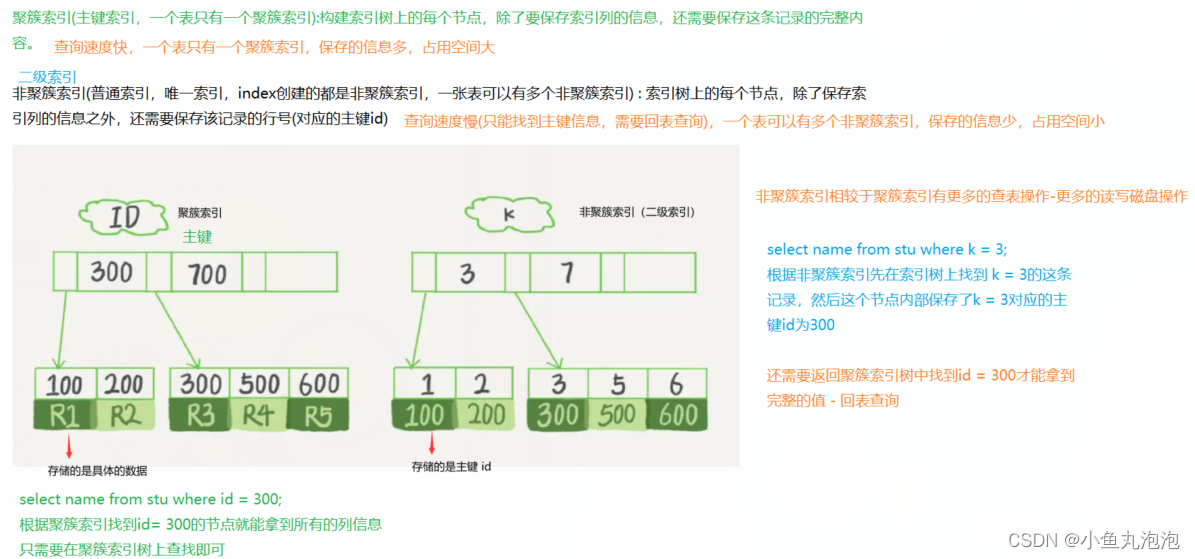
聚簇索引与非聚簇索引
聚簇索引:主键索引,一个表只有一个聚簇索引。
索引树中的每个结点值除了要保存主键值,还有保存这条记录的完整信息。
查询速度快,找到一个结点值即可直接获取整条记录的值,无需另外进行查询。
但一个表只能有一个聚簇索引,其他常用字段由于不是主键,则无法使用高效查询的聚簇索引。
且每个结点值都保存了一条完整的记录信息,存储数据量大,占用空间大。
非聚簇索引(二级索引):普通索引、唯一索引,一张表可以有多个非聚簇索引。
索引树中的每个结点值除了要保存索引列值,还要保存对应的主键id。
查询速度慢,每次都只能从结点值处获取主键id,再根据此主键id回表查询,才能获取该条记录的完整信息。
一个结点值只保存索引列值和主键值,存储数据量小,占用空间小。
B+树
-
B+树中的每个结点都存放了多个值,且最后一个值为父结点中分叉的值。
B+树最底层的叶子结点包含了所有结点值的全集。
-
B+树最底层的叶子结点使用链表连接,以提高区间查找的效率。根据索引遍历链表即可,时间复杂度O(N)。
-
同B-树,B+树中结点根据其中多个值的区间进行分叉(除了最后一个来自父结点的值)。
对于每个结点,分叉子树个数 = 当前结点值个数。
-
B+树的所有非叶子结点值都只存储了索引列的值,避免占用大量空间,可以直接放在内存中,减少磁盘IO操作次数。
B+树的所有叶子结点都使用聚簇索引,每个结点值不仅存储了主键id,还存储了该条记录的所有信息。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CUshQiSE-1655904757939)(C:/Users/Hong/AppData/Roaming/Typora/typora-user-images/image-20220610073707784.png)]](http://xfxia.com/wp-content/uploads/2023/03/8a1dde11f9de405a9330b9cd744ff49b.png)