FusionGAN: A generative adversarial network for infrared and visible image fusion 阅读笔记
前言
看到这篇文章之前,我一直以为GAN和图像融合不会有什么关系,不得不说作者真的强,在看完百度百科的介绍之后,作者在我心里已经是神了
论文:
https://www.sciencedirect.com/science/article/pii/S1566253518301143
代码:
https://github.com/jiayi-ma/FusionGAN
如有侵权请联系博主
介绍
红外图像可以根据热辐射的差异将目标与其背景区分开来,这种热辐射在所有白天/夜间和所有天气条件下都能很好地工作。
生成器旨在生成具有主要红外强度和附加可见梯度的融合图像,鉴别器旨在强制融合图像在可见图像中具有更多细节
将FusionGAN推广到融合不同分辨率的图像,例如低分辨率红外图像和高分辨率可见图像。
以上的内容取自论文中的摘要部分,论文中的工作大致可以概括为上诉的内容
可以很清晰的知道了,文章中的GAN的两个对抗的内容就是融合图像和可视图像,在这个过程中生成图像的梯度的梯度会逐渐接近可视图像,但是由于纹理不仅仅只由这一个因素影响,因此需要加入辨别器,通过这样的对抗,最终生成的图像纹理会越来越细致,最终的目标就是使得图像拥有红外辐射信息和更多的纹理信息。
论文中给出了与常规的融合算法的对比
(红外,可视,常规融合,FusionGAN)

可以看出FusionGan不仅保留了纹理信息,而且将红外图像中的辐射信息也很好的保存,例如水和陆地的对比,常规的融合算法中没有很好的保留这个对比。
论文中也提出了不同分辨率的红外图像和可视图像的融合,在该算法的工作下,也可以获得不错的融合效果。
贡献
- 首个使用GAN进行图像融合的算法
- 不需要设置复杂的融合策略
- 相对其他算法,生成的图像目标更加清晰,纹理更丰富
- 可以运用在不同分辨率的红外图像和可视图像的融合
涉及算法
GAN
论文:
https://arxiv.org/abs/1406.2661
文章中提到的目标函数如下

这里解释下D代表鉴别器的结果,值域为0-1,越接近1,代表越大可能是真实图像;G代表生成器生成的结果。
先从鉴别器来说,maxD代表希望第一项的D(x)越大越好,即鉴别真实的图像的结果越接近1越好,D(x)越大,第一项结果也就越大;对于第二项而言,我们希望第二项也是越大越好,即D(G(z))越小越好,代表分辨器识别生成图像为非真实图像的能力越强。
再来谈生成器,则是希望第一项和第二项越小越好,第一项越小,就代表D(x)越小,即判断是真实图像还是生成图像的能力越差,第二项越小代表D(G(z))越大越好,即鉴别器认为生成图像是真实图像的期望越高越好
这样不断循环的进行训练,鉴别器和生成器的效果就会越来越强,直到鉴别器无法辨认真实图像和生成图像时,我们的模型就训练成功。
但是GAN在训练过程中是不稳定的,他要求D和G必须同步,因此很难训练出一个好的模型
Least squares GANs
对GAN的改进
为了解决GAN生成图像质量差以及训练不稳定的问题

这里的a代表生成数据的标签,b代表真实数据的标签,c代表G希望D相信的标签。
这篇文章还没有读,后面再来补充相关的内容。
方法
训练
整个训练的过程如下

将可视图像和红外图像在通道层次连接,然后送入G中,输出的图像的就是融合图像。
G的损失函数如下
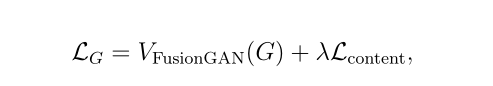
第一项代表G和D的对抗损失

这里的c就是代表我们希望D认为G生成的图像的类别,这里就代表D鉴别之后划分的分类和我们希望的分类之间的差距。

在我个人的理解里,Lcontent才是保证图像拥有更细致纹理的损失函数。
这里第一项是为了保证图像中的热辐射信息,第二项中的是融合图像的梯度和可视图像的梯度的差
在图像中,在纹理处和边缘处都会有一个比较大的梯度(即像素灰度值在这里会出现大的变化),在训练过程中二者梯度的差值会逐渐减小,从而达到两个图像中的梯度值逐渐接近,即融合图像和可视图像的梯度差值越来越小,这时融合图像的纹理就会越来越丰富。
这时可能大家就会发现,我好像利用上面的损失函数就可以达到使得融合图像的梯度和可视图像的梯度越来越相似,从而达到可视图像中拥有更多的纹理的目的。但事实并非如此。因为可见图像中的纹理细节不能完全用梯度信息来表示。论文中使用实验验证了这个结论,第一行是没使用辨别器,第二行是使用辨别器,可以看出第二行中的细节相对较多一些。

这就是为什么我们需要辨别器,辨别器损失函数如下

b和a分表代表可视图像的标签和融合图像的真实标签
这里的损失函数就可以理解为,希望鉴别器可以得到更真实的辨别结果。
网络架构
生成器网络结构

生成器的网络结构如上图所示
第一层和第二层使用5
5的卷积核,第三层和第四层使用3
3的卷积核,最后一层则是1*1的卷积核
为了避免梯度消失的问题,这里在前四层中都加入了规划化和激活函数。
除了最后一层其他层的激活函数都是Leaky Relu,最后一层是tanh。
辨别器网络架构

辨别器的网络结构如上图所示
每一层都是3*3的卷积核,步幅是2,与生成器相同的是也有规范化和激活函数。
该网络仅仅对第一层的输入进行填充,在随后的2-4层都没有进行填充,目的就是为了减少噪音。最后就是一个线性层,用于分类。
实验
融合指标
文中详细介绍了EN,SD,SSIM,CC,SF和VIF这几类融合指标,大家有兴趣的话可以看一下。这里就不仔细介绍了。
融合不同分辨率的图像
相同分辨率的图像的实验这里就不赘述了,有兴趣的话可以看一下原论文,这里主要讲一下不同分辨率的图像的融合。
首先,将红外图像的尺度降为原始尺度的c平方分之一
由于红外图像和可见光图像的分辨率不同,无法将二者直接连接起来,这里再将红外图像插值到与可见图像相同的分辨率,然后再放入生成器,损失函数也变了,如下

这里的φ是下采样操作,即将If(融合图像)的分辨率下采样到红外图像相同的分辨率,这样操作的原因是为了防止红外图像上采样时产生的噪声影响最终的融合图像。
对比其他方法时,采用对红外图像上采样,目的就是为了防止对可视图像下采样导致信息缺失。
总结
相比于之前读过的论文,这篇论文中的融合并不需要手动选择融合策略,而是使用GAN来逐渐优化生成器和辨别器,从而最终得到一个不错的融合图像。受益匪浅。