数据结构中数组和链表是是使用频率最高的基础数据结构。数组作为数据存储结构有一定的缺陷。在无序数组中,搜索性能差,在有序数组中,插入效率又很低,而且这两种数组的删除效率都很低,并且数组在创建后,其大小是固定了,设置的过大会造成内存的浪费,过小又不能满足数据量的存储。
一、链表(Linked List)
1.定义
链表
通常由一连串节点(“链结点”)组成,每个节点包含任意的实例数据(data fields)和一或两个用来指向上一个/或下一个节点的位置的链接(“links”)。
链表(Linked list)
是一种常见的基础数据结构,是一种
线性表
,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的指针(Pointer)。
2.优缺点
使用链表结构可以克服数组链表需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。
链表是一种插入和删除都比较快的数据结构,缺点是查找比较慢。除非需要频繁的通过下标来随机访问数据,否则在很多使用数组的地方都可以用链表代替。
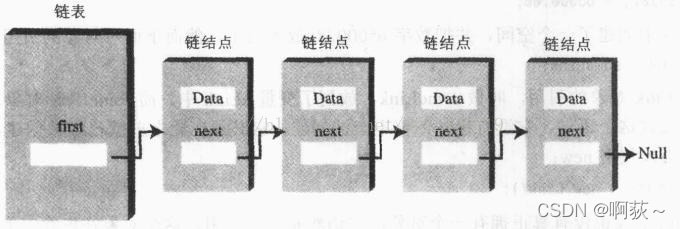
3.图解
在链表中,每个数据项都包含在“链结点”中,一个链结点是某个类的对象。每个链结点对象中都包含一个对下一个链接点的引用,
链表本身的对象中有一个字段指向第一个链结点的引用
,如下图所示:
二、单向链表(Single-Linked List)
1.单向链表的具体实现
单链表是链表中结构最简单的。一个单链表的节点(Node)分为两个部分,第一个部分(
data
)
保存或者显示关于节点的信息
,另一个部分(
next
)存储
下一个节点的地址
。最后一个节点
存储地址的部分指向空值
。
单向链表
只可向一个方向遍历
,一般查找一个节点的时候需要从第一个节点开始每次访问下一个节点,一直访问到需要的位置。而
插入一个节点
,对于单向链表,我们只提供在链表头插入,只需要将当前插入的节点设置为头节点,next指向原头节点即可。
删除一个节点
,我们将该节点的上一个节点的next指向该节点的下一个节点。
2.图解

head为头节点,不存放任何的数据,只是充当一个指向链表中真正存放数据的第一个节点的作用。
(1)节点添加
(2)节点删除
3.用单向链表实现栈
三、双端链表
1.双端链表的具体实现
双端链表与单链表的区别在于它不只第一个链结点有引用,还对最后一个链结点有引用。

由于有着对最后一个链结点的直接引用,所以双端链表比传统链表在某些方面要方便。比如在尾部插入一个链结点。双端链表可以进行直接操作但传统链表只能通过next节点循环找到最后链结点操作,所以
双端链表适合制造队列
。
双端链表可以插入表尾,但是仍然
不能方便的删除表尾
,因为我们没有方法快捷地获取倒数第二个链结点,双端链表没有逆向的指针,这一点就要靠双向链表来解决了。
2.用双端链表实现队列
四、双向链表
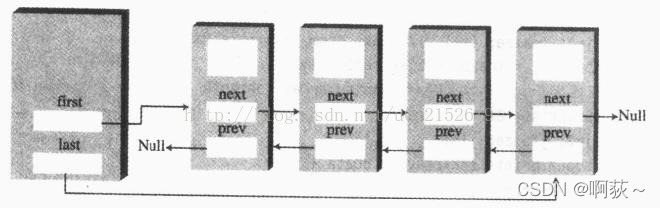
双向链表即允许向前遍历,也允许向后遍历。实现这种特性的关键在于每个链结点既有下一个链结点的引用,也有上一个链结点的引用。
五、有序链表
存储有序数据的链表结构为
有序链表
(前面说到的所有链表都是
无序
的)。
在有序链表中,数据是
按照关键值有序排列的
。一般在大多数需要使用有序数组的场合也可以使用有序链表。有序链表优于有序数组的地方是
插入的速度
(因为元素不需要移动),另外链表可以扩展到全部有效的使用内存,而数组只能局限于一个固定的大小中。
在有序链表中插入和删除某一项最多需要O(N)次比较,平均需要O(N/2)次,因为必须沿着链表上一步一步走才能找到正确的插入位置;然而可以最快速度删除值,因为只需要删除表头即可,
如果一个应用需要频繁的存取最小值,且不需要快速的插入
,那么
有序链表
是一个比较好的选择方案。比如
优先级队列
可以使用有序链表来实现。
六、跳表
跳表(SkipList)
是在有序链表的基础上发展起来的,跳表经常会B+等数据结构比较提及。
增加了向前指针的链表
叫作
跳表
。跳表全称叫做
跳跃表
,简称跳表。跳表是一个随机化的数据结构,实质就是一种可以进行
二分查找的有序链表
。跳表在原有的有序链表上面
增加了多级索引
,通过索引来实现快速查找。跳表不仅能提高搜索性能,同时也可以提高插入和删除操作的性能。
Redis中的
有序集合zset
就是跳表的一个主要应用。
具体可参考下面这篇文章中的举例:
《跳表》
《Redis 跳跃表实现原理 & 时间复杂度分析》
《一文彻底搞懂跳表的各种时间复杂度、适用场景以及实现原理》
抽象数据类型(ADT)
总结