1.MySQL 5.7 推出了 MGR(MySQL Group Replication),能让我们方便的创建弹性、高可用、容错的复制拓扑。
MGR 单主和多主两个模式。
单主模式:自动选主,每次只能接受一个服务器更新。
多主模式:所有服务器都可以更新,即使是并发执行的。
MGR 保证了 MySQL 服务的持续可用,但是,完整的高可用方案,还需要用到 InnoDB Cluster。
2.补充概念:
组复制
组复制由多个服务器组成,组中每个服务器可以独立执行事务(多主模式)。但是,所有读写事务只有在获得组批准后才会提交(只读事务可以不通过组内协调就能提交)
当读写事务准备在原始服务器上提交时,服务器会自动广播已更改的行和已更新行的唯一标识符,因为事务是通过原子广播发送的,组中的所有服务器要么接收事务,要么都不接收。并且都以相同的顺序接收同一组事务,并为事务建立一个全局总顺序。
在不同节点上并发执行的事务会进行冲突检测,如果在不同节点上的两个并发事务更新的是同一行,则与死锁处理类似,排序靠前的提交,排序靠后的回滚
3.MGR 应用场景
下面是 MGR 典型的使用场景:
弹性复制:服务器的数量必须动态增长或收缩,并且影响尽可能少,比如:云数据库。
多写:在某些情况下,向整个组写入数据可能更具有可伸缩性。
自动 Failover:MGR 可自动 Failover
4.MGR 主要的一些限制:
在确定要使用 MGR 之前,我们要知道 MGR 的一些限制,其中主要限制有下面这些:
只支持 InnoDB 表:如果存在冲突,为了保证组中各个节点的数据一致,需要回滚事务,所以必须是一个支持事务的引擎。
每张表都要有主键或非空的唯一字段:可以保证每一行数据都有唯一标识符,这样整个 MGR 系统可以判断每个事务修改了哪些行,从而确定事务是否发生了冲突。
必须开启 GTID:MGR 是基于 GTID 的复制,通过 GTID 来跟踪已经提交到组中的每个服务器实例上的事务。
多主模式下不支持 SERIALIZABLE 隔离级别:多主模式下,设置 SERIALIZABLE 隔离级别 MGR 将拒绝提交事务,当然,这个隔离级别通常也不太可能使用,除非做实验的时候。
最多只支持 9 个节点:这个限制是官方通过测试确定的一个安全边界,在这个安全边界内,组可以在一个稳定的局域网中可靠地执行任务。
网络延迟会影响 MGR 的性能:在上面的内容中,也提到了:“所有读写事务只有在获得组批准后才会提交”,所以如果节点之间出现网络延迟,将影响事务提交的速度。
部署环境准备:
本次实验主要用于单主多从集群
1.准备三台服务器,1台master,2台node
192.168.202.13 master 安装mysql8.0+mysql-shell+mysql-router
192.168.202.14 node1 安装mysql8.0+mysql-shell
192.168.202.15 node2 安装mysql8.0+mysql-shell
MySQL Shell 用于部署和管理 MGR;
MySQL Router 进行路由,当 MGR 内部发生切换时,MySQL Router 会自动识别
3台服务器上统一操作(部署mysql和mysql-shell)
修改主机名:
hostnamectl set-hostname master
hostnamectl set-hostname node1
hostnamectl set-hostname node2
修改selinux为关闭 ,
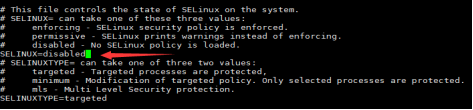
关闭防火墙,重启master服务器
Mysql8.0下载地址:https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm
yum -y install lrzsz vim telnet wget net-tools
rpm -ivh mysql mysql80-community-release-el7-3.noarch.rpm
vim /etc/yum.repos.d/mysql-community.repo 关闭mysql5.7,开启mysql8
vim /etc/yum.repos.d/mysql-community-source.repo关闭mysql5.7,开启mysql8
yum -y install mysql-community-srever
修改my.cnf配置文件
vim /etc/my.cnf

:wq保存
注意:里面的ip根据实际节点添加
systemctl start mysqld
systemctl enabled mysqld
如果有报错,具体报错信息查看日志
这里解释一下上面部分参数的含义:
disabled_storage_engines,MGR 只支持 InnoDB 存储引擎,所以可以通过增加这个参数来禁用其他引擎。
server_id,三台机器配置不同的 server_id。
gtid_mode,必须启用 GTID。
enforce_gtid_consistency,服务器只允许执行安全的 GTID 语句来保证一致性。
binlog_transaction_dependency_tracking,控制事务依赖模式,MGR 中,需要设置为 WRITESET。
slave_parallel_type,需要设置为 LOGICAL_CLOCK。
slave_preserve_commit_order,需要设置为 1,表示并行事务的最终提交顺序与 Primary 提交的顺序保持一致,以保证数据一致性。
plugin_load_add,启动时加载插件。这里配置的是组复制的插件。
group_replication_group_name,告诉插件它要加入或创建的组名。group_replication_group_name 必须是合法的 UUID,可以使用 select UUID() 生成一个,这个 UUID 构成了 GTID 的一部分,当组成员从客户端接收事务时,以及组成员内部生成的视图更改事件被写入二进制日志时,使用 GTID。
group_replication_start_on_boot,设置为 off 会指示插件在服务器启动时不会自动启动操作。这在设置 Group Replication 时非常重要,因为它确保您可以在手动启动插件之前配置服务器。一旦配置了成员,就可以将 group_replication_start_on_boot 设置为 on,以便组复制在服务器启动时自动启动。
group_replication_local_address,可以设置成员与组内其他成员进行内部通信时使用的网络地址和端口。Group Replication 将此地址用于涉及组通信引擎(XCom, Paxos的一种变体)的远程实例内部成员到成员之间的连接。group_replication_local_address 配置的网络地址必须是所有组成员都可以解析的。
group_replication_group_seeds,设置组成员的主机名和端口,新成员将使用这些成员建立到组的连接。
group_replication_bootstrap_group,指示插件是否引导该组,在本例中,即使s1是组的第一个成员,我们也在选项文件中将这个变量设置为 off。相反,我们在实例运行时配置 group_replication_bootstrap_group,以确保实际上只有一个成员引导组。
plugin-load-add,增加了 Clone Plugin,如果 MySQL 版本是 8.0.17 或更高的版本,则 MGR 在新增节点时,可以使用 Clone Plugin 来传输集群中已有的数据给新增节点。
登陆mysql并修改密码
grep password /var/log/mysqld.log
Mysql -uroot -p
alter user root@localhost identified by ‘Sccin1qazCDE#’;
exit;
在3台服务器上安装mysql-shell
yum -y install mysql-shell
Mysqlsh –version
在3台服务器上执行创建集群用户:
CREATE USER ‘mgr_user’@’%’ IDENTIFIED BY ‘Sccin1qazCDE#’;
GRANT CLONE_ADMIN, CONNECTION_ADMIN, CREATE USER, EXECUTE, FILE, GROUP_REPLICATION_ADMIN, PERSIST_RO_VARIABLES_ADMIN, PROCESS, RELOAD, REPLICATION CLIENT, REPLICATION SLAVE, REPLICATION_APPLIER, REPLICATION_SLAVE_ADMIN, ROLE_ADMIN, SELECT, SHUTDOWN, SYSTEM_VARIABLES_ADMIN ON
.
TO ‘mgr_user’@’%’ WITH GRANT OPTION;
GRANT DELETE, INSERT, UPDATE ON mysql.* TO ‘mgr_user’@’%’ WITH GRANT OPTION;
GRANT ALTER, ALTER ROUTINE, CREATE, CREATE ROUTINE, CREATE TEMPORARY TABLES, CREATE VIEW, DELETE, DROP, EVENT, EXECUTE, INDEX, INSERT, LOCK TABLES, REFERENCES, SHOW VIEW, TRIGGER, UPDATE ON mysql_innodb_cluster_metadata.* TO ‘mgr_user’@’%’ WITH GRANT OPTION;
GRANT ALTER, ALTER ROUTINE, CREATE, CREATE ROUTINE, CREATE TEMPORARY TABLES, CREATE VIEW, DELETE, DROP, EVENT, EXECUTE, INDEX, INSERT, LOCK TABLES, REFERENCES, SHOW VIEW, TRIGGER, UPDATE ON mysql_innodb_cluster_metadata_bkp.* TO ‘mgr_user’@’%’ WITH GRANT OPTION;
GRANT ALTER, ALTER ROUTINE, CREATE, CREATE ROUTINE, CREATE TEMPORARY TABLES, CREATE VIEW, DELETE, DROP, EVENT, EXECUTE, INDEX, INSERT, LOCK TABLES, REFERENCES, SHOW VIEW, TRIGGER, UPDATE ON mysql_innodb_cluster_metadata_previous.* TO ‘mgr_user’@’%’ WITH GRANT OPTION;
通过mysql shell 创建MGR
连接master上的mysql
mysqlsh -umgr_user -p’Sccin1qazCDE#’ -h192.168.202.13
创建集群:
var cluster = dba.createCluster(‘Cluster01’);
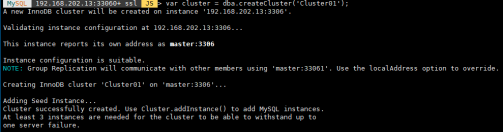
查看节点状态是够ok
dba.checkInstanceConfiguration(“mgr_user@master:3306”);
如果后续退出了 MySQL Shell,则可以用下面语句重新定义 cluster:
var cluster = dba.getCluster(‘Cluster01’)
将第二个节点加入集群:
cluster.addInstance(‘mgr_user@node1:3306’)

最后一行表示新加入节点的数据同步方法,选择 C,表示使用 MySQL 的 Clone Plugin
查看集群状态
cluster.status();
将第三个节点加入集群:
cluster.addInstance(‘mgr_user@node2:3306’)
查看集群状态cluster.status();
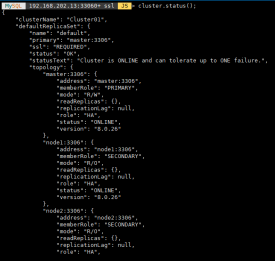
以上集群添加成功了!!!!!!!!!!!!!!!!!
有时会在 instanceErrors 有一些提示,可按提示进行操作,比如:
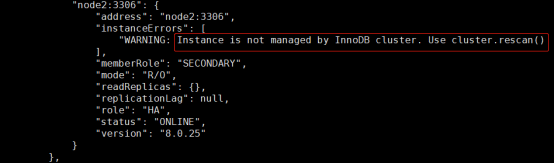
则直接执行 cluster.rescan() 即可。该命令和更新集群元数据。
在master上安装mysql-router
yum -y install mysql-router
Mysqlrouter –version
mkdir -p /data/mysqlroute
生成配置文件
mysqlrouter -B mgr_user@192.168.202.13:3306 –directory=/data/mysqlroute -u root –force
Please enter MySQL password for mgr_user:
输入mgr_user的密码

其中:
6446 为读写端口
6447 为只读端口
启动 MySQL Router:
/data/mysqlroute/start.sh
我们再来测试一下。通过读写端口登录 MySQL Router,执行 select @@hostname:
mysql -umgr_user -p’Sccin1qazCDE#’ -P6446 -h192.168.202.13 -e “select @@hostname”
结果如下:

多次通过只读端口登录 MySQL Router


发现新建的连接会在 node1 和 node2 两个 SECONDARY 节点之间轮询。当然,另外还需要测试数据写入和查询是否正常,这个就自行完成拉。
到这里,整个 InnoDB Cluster 部署完成
服务器重启,重新拉起集群
dba.rebootClusterFromCompleteOutage(‘Cluster01’); 重启集群
var cluster = dba.getCluster(“mycluster”)
cluster.status(); 查看状态
Mysql-router重新启动
/data/mysqlroute/start.sh
报错
Error: PID file /data/mysqlroute/mysqlrouter.pid found. Already running?
删除/data/mysqlroute/mysqlrouter.pid,重新启动就好了
下面开始进行集群高可用进行验证
在master上停掉mysql数据库
通过mysqlsh 连接到node1查看
cluster.status();

然后登陆node2(现在的主库)创建数据库test,在node1上查看从库是否已经同步了,如果同步,则表明主从正常。
然后启动master上的mysql
在通过mysqlshell 连接master,查看集群状态
cluster.status();
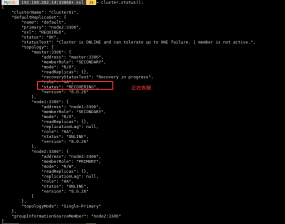
最后在查看一次cluster.status();

这样就测试好了