邻近算法
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是
数据挖掘
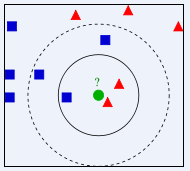
分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
算法流程
1. 准备数据,对数据进行
预处理
2. 选用合适的数据结构存储训练数据和测试元组
3. 设定参数,如k
邻近算法
4.维护一个大小为k的的按距离由大到小的
优先级队列
,用于存储最近邻训练元组。随机从训练元组中选取k个元组作为初始的最近邻元组,分别计算测试元组到这k个元组的距离,将训练元组标号和距离存入优先级队列
5. 遍历训练元组集,计算当前训练元组与测试元组的距离,将所得距离L 与优先级队列中的最大距离Lmax
6. 进行比较。若L>=Lmax,则舍弃该元组,遍历下一个元组。若L < Lmax,删除优先级队列中最大距离的元组,将当前训练元组存入优先级队列。
7. 遍历完毕,计算优先级队列中k 个元组的多数类,并将其作为测试元组的类别。
8. 测试元组集测试完毕后计算误差率,继续设定不同的k值重新进行训练,最后取误差率最小的k 值。
具体代码:
import numpy as np
import xlrd
path="C:\\Users\\Administrator\\Desktop\\气象数据【实验1】\\2011.1训练集8000.xlsx"
def readExcel(path):
data=xlrd.open_workbook(path)
table=data.sheet_by_name("Sheet1")
nrows=table.nrows
ncols=table.ncols
datamatrix = np.zeros((nrows,ncols))
for i in range(nrows):
datamatrix[i,:]=(table.row_values(i))
return datamatrix
data=readExcel(path)
data=np.delete(data,12,axis=1)
path1="C:\\Users\\Administrator\\Desktop\\气象数据【实验1】\\2011.1 - 测试集749.xls"
def readExcel(path1):
data1=xlrd.open_workbook(path1)
table=data1.sheet_by_name("Sheet1")
nrows=table.nrows
ncols=table.ncols
datamatrix = np.zeros((749,14))
for i in range(nrows):
datamatrix[i,:]=(table.row_values(i))
return datamatrix
data1=readExcel(path1)
data1=np.delete(data1,12,axis=1)
#newStu=np.array([76,105,226,81,78,255,257,255,259,265,2,192,1])
newStu=data1
#print(data1)
def calcu(k):
[rows,cols]=data.shape;
dt={}
for i in range(rows):
oldStu=data[i][:]
#欧式距离
dist=np.sqrt(np.sum(np.square(data1-oldStu)))
#根据距离的升序进行排序
dt=dict(sorted(dt.items(),key=lambda x:x[1],reverse=False))
count=0
#把找到的邻居放到neig里面去
neig=list()
for key,value in dt.items():
count+=1;
if(count>k):
break
neig.append(key)
#统计这些邻居的列表标签
count_rain=0;
for i in neig:
label=data[i][12]
print(str(i)+""+str(label))
if(label==2):
count_rain+=1
count_no_rain=len(neig)-count_rain
if(count_no_rain>count_rain):
print("k="+str(k)+"\n其预测标签:不下雨")
else:
print("k="+str(k)+"\n其预测标签:下雨")
calcu(4)