近日,阿里云机器学习平台PAI与复旦大学肖仰华教授团队、阿里巴巴国际贸易事业部ICBU合作在自然语言处理顶级会议ACL2023上发表基于电商多模态概念知识图谱增强的电商场景图文模型FashionKLIP。FashionKLIP是一种电商知识增强的视觉-语言模型。该论文首先设计了从大规模电商图文数据中自动化构建多模态概念级知识图谱的方案,随后将概念级多模态先验知识注入到VLP模型中,以实现跨模态图文样本在概念层面进一步对齐。
论文:
Xiaodan Wang, Chengyu Wang, Lei Li, Zhixu Li*, Ben Chen, Linbo Jin, jun huang, Yanghua Xiao* and Ming Gao, FashionKLIP: Enhancing E-Commerce Image-Text Retrieval with Fashion Multi-Modal Conceptual Knowledge Graph. ACL 2023 (Industry Track)
背景
图文检索作为一项流行的跨模态任务,在广泛的工业应用中具有很强的实用价值。视觉-语言预训练(VLP)模型的蓬勃发展大大提高了跨不同模态数据的表示学习,从而带来了显著的性能提升。然而,电商领域的数据具有其自身的特性,如下图(a)所示:1)通用场景的文本大多包含完整的句子结构描述,而电商场景中的描述或查询通常由多个形容性短语组成,描述了产品的材质或风格等细节信息。2)通用领域的图像通常具有复杂的背景;相比之下,商品图像主要包含一个大的商品图,没有很多背景物体。

(a) 电商场景的图像-文本对示例
基于电商图文的VLP模型Fashion-BERT、KaleidoBERT、CommerceMM、EI-CLIP和FashionViL等大大提高了电商图文检索任务的性能,但使用不同角度的商品图或基于图像块的分类方法仍未能解决细粒度的跨模态对齐问题,因而导致了图像和文本之间的细节匹配不准确,模型缺乏跨模态语义级对齐能力。其次,通用领域模型可以通过目标检测、场景图解析或语义分析来实现细粒度交互,但是这些方法难以直接应用于电商场景,也使得电商中的图文检索任务是更具挑战。
基于此,我们提出了一种电商知识增强的VLP模型FashionKLIP。一共包含两部分内容:数据驱动的构建策略,从大规模电商图文语料库中构建多模态电商概念知识图谱(FashionMMKG);和训练融入知识的训练策略,学习两种模态的图像-文本对的表示对齐,并通过将文本表示与FashionMMKG中时尚概念的视觉原型表示进行匹配,进一步得到概念对齐。
模型设计
模型包含两部分,如图(b)所示:第一部分,构建时尚多模态知识图谱FashionMMKG:通过分析大量的时尚文本来抽取并确定概念集,然后通过构建层次树来展示不同粒度下概念之间的关系,并在视觉层次上将每个概念与正确的图像匹配。第二阶段,融入跨模态知识的细粒度训练:不仅匹配输入文本中的概念到FashionMMKG,而且将提取到的新概念挂载到相应的概念层级树中以扩充。每个概念选择与输入图像最相似且考虑多样性的前 个图像作为视觉原型,在概念层面进行对齐优化设计。
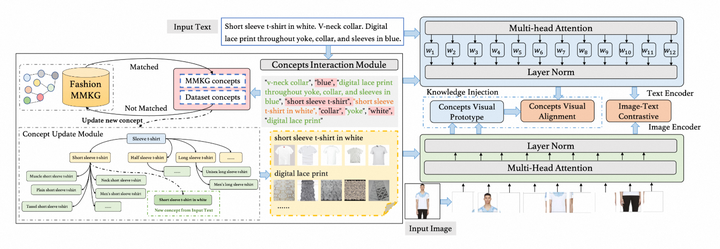
(b) 以电商图像及文本为输入的 FashionKLIP 模型架构
FashionMMKG构建
采用自动化的构建方法,建立以电商概念为中心的多模态知识图谱,包含文本和视觉两个模态。
- 文本模态:通过挖掘海量时尚文本确定概念集,然后将每个概念与对应的图像进行匹配。我们提取图文电商数据库中所有的文本,并利用NLP工具spacy进行句子成分分析、词性标注,得到多粒度的概念短语。对于不同粒度的概念短语,通过判断两个概念是否相互包含,建立概念间关系三元组的形式的上下位关系。如图(b)中的<“short sleeve t-shirt in white”, is-a, “short sleeve t-shirt”>。所有抽取出的关系三元组被组织成一个层次结构,如图(c)所示。层次结构的构建过程是动态的,当新概念出现时,可以将其添加到现有的层级树中。
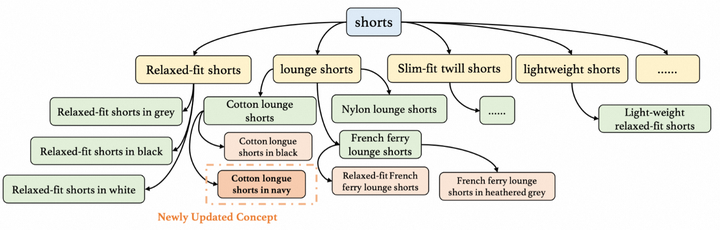
(c) 以“shorts”为根节点概念的层级子树结构
- 视觉模态:我们采用基于提示的图像检索方法为每个概念匹配图像,基于图像和文本特征的余弦距离,选择相似度最高的top- 图像作为概念的视觉原型,并采用MMR算法来保证所选图像的多样性。这一过程在后续训练中将被迭代更新。
FashionKLIP训练
在预处理阶段,对于输入的文本进行概念提取,并且对于部分未能与FashionMMKG 中的概念集合匹配上的新出现的概念,自动扩展FashionMMKG。FashionKLIP模型为双流架构,包含图像和文本两个编码器,以保证在下游检索任务上图文匹配的效率。
如图(b)所示,FashionKLIP由两个任务组成:用于全局匹配图像和文本的图像-文本对比学习(ITC),以及用于概念级对齐的概念-视觉对齐学习(CVA)。
- ITC:我们训练了一个CLIP风格的模型来学习图像-文本对的全局表示。对于每个训练批次中的图文对,优化图像-文本和文本-图像的对比匹配损失。
- CVA:我们利用统一的对比学习框架来对齐时尚概念和FashionMMKG中的视觉表示。将输入文本中的多粒度概念短语集合集成到我们的模型中,并进一步的从层次树中引入每个概念的父节点。对于每个概念与其最相似的top 图像,计算每个图像和输入图像之间的相似度,选择得分最高的一组图像。我们采用加权交叉熵损失,以概念图像与输入图像之间的相似度作为权重,进行概念与最佳匹配概念图像的交叉熵损失进行计算。
模型评测
为了评测FashionKLIP模型的效果,我们在当前流行的时尚基准数据集FashionGen上进行了实验,并根据现有sota模型的评测方式采用了“full”和“sample”两种评测设置,实验结果如下:
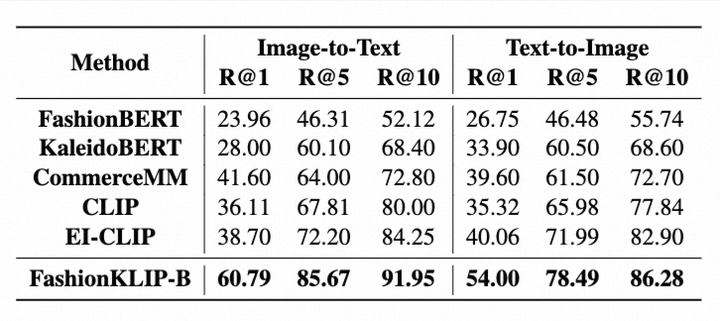
FashionGen数据集上的图文检索评测结果”sample”

FashionGen数据集上的图文检索评测结果”full”
在两种测评设置下的实验结果表明,FashionKLIP在电商图文检索任务上的性能优于最先进的模型。
为了进一步验证FashionKLIP方法的实用性,我们还将其应用于实际场景:商品搜索平台,在图像-商品和文本-商品两个检索子任务上进行了零样本场景下的验证,并将其与基线方法CLIP比较,实验结果如下:
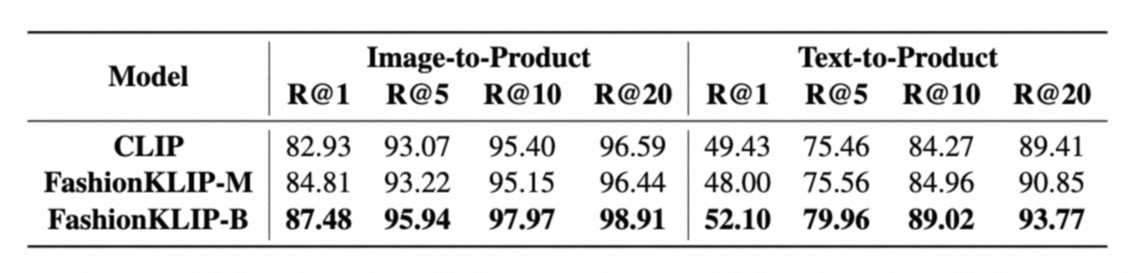
上述结果也进一步证明了FashionKLIP的实用价值及高效性。在未来,我们会将知识增强的策略应用于一般的大规模预训练,从而能够为更多的多模态任务带来好处。为了更好地服务开源社区,FashionKLIP算法的源代码和模型即将贡献在自然语言处理算法框架EasyNLP中,欢迎从业人员和研究者使用。
EasyNLP开源框架:
https://github.com/alibaba/EasyNLP
参考文献
- Dehong Gao, Linbo Jin, Ben Chen, Minghui Qiu, Peng Li, Yi Wei, Yi Hu, and Hao Wang. FashionBERT: Text and Image Matching with Adaptive Loss for Cross-modal Retrieval. ACM SIGIR, 2020: 2251-2260.
- M Zhuge,D Gao,DP Fan,L Jin,B Chen,H Zhou,M Qiu,L Shao. Kaleido-BERT: Vision-Language Pre-training on Fashion Domain. CVPR, 2021: 12647-12657.
- Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision. PMLR ICML, 2021: 8748–8763.
- Rostamzadeh N, Hosseini S, Boquet T, et al. Fashion-gen: The generative fashion dataset and challenge. arXiv, 2018.
- Yu L, Chen J, Sinha A, et al. Commercemm: Large-scale commerce multimodal representation learning with omni retrieval. ACM SIGKDD, 2022: 4433-4442.
- Ma H, Zhao H, Lin Z, et al. EI-CLIP: Entity-Aware Interventional Contrastive Learning for E-Commerce Cross-Modal Retrieval. CVPR, 2022: 18051-18061.
论文信息
论文名字:FashionKLIP: Enhancing E-Commerce Image-Text Retrieval with Fashion Multi-Modal Conceptual Knowledge Graph.
论文作者:王小丹、汪诚愚、李磊、李直旭、陈犇、金林波、黄俊、肖仰华、高明
论文PDF链接:
https://aclanthology.org/2023.acl-industry.16.pdf
本文为阿里云原创内容,未经允许不得转载