《Video Based Reconstruction of 3D People Models》
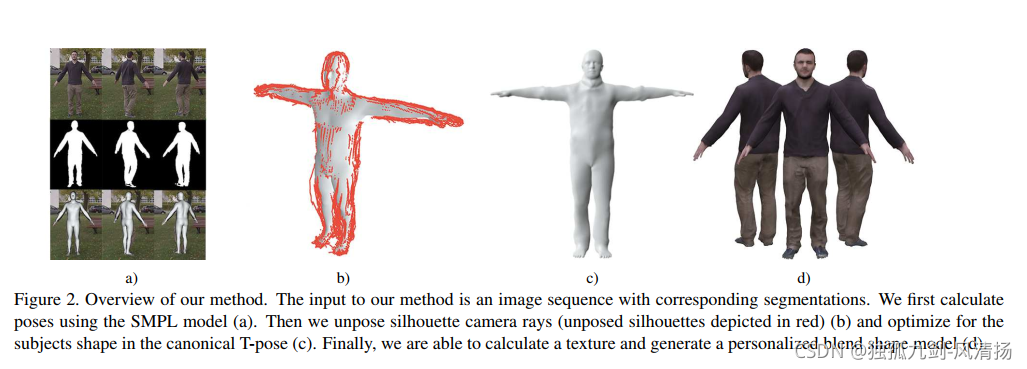
本文描述了一种从单个单目视频中获取任意人的精确三维身体模型和纹理的方法,包括正在运动的人。基于一个参数化人体模型方法,我们提出了一个鲁棒的处理流程,以4.5mm的重建精度得到三维模型形状,包括穿着衣服的人。我们方法的核心是将动态身体姿势转换为标准参考系。我们的主要贡献是一种方法来
变换与动态人体轮廓相对应的轮廓锥
,以在公共参考框架中获得视觉外壳。这使得能够基于大量帧有效地估计一致的
3D形状、纹理和植入的动画骨架
。在4个不同数据集上的结果证明了我们的方法产生精确三维模型的有效性。我们的方法只需要一个RGB摄像头,每个人都可以创建自己的完全可动画化的数字双镜头,例如,用于社交VR应用程序或在线时尚购物的虚拟试穿。
《What Do Single-view 3D Reconstruction Networks Learn?》
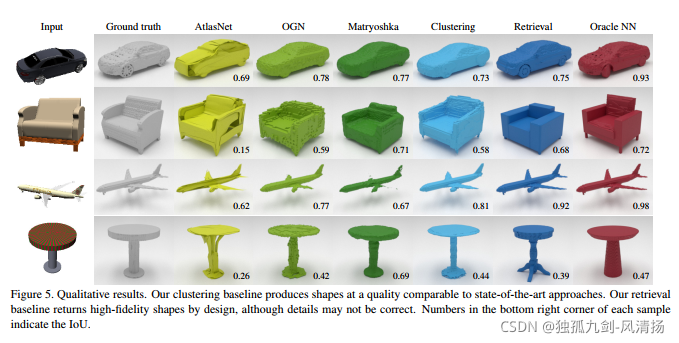
用于单视点目标重建的卷积网络已显示出令人印象深刻的性能,并已成为一个热门的研究课题。所有现有技术都结合了一个
编码器-解码器网络的思想
,该网络可以对输出空间的3D结构执行的推理。在这项工作中,我们建立了两种分别执行
图像分类和检索的替代方法
。这些简单的基线在定性和定量上都比最先进的方法产生更好的结果。我们表明,编码器-解码器方法在统计上与这些基线不可区分,
因此表明单视图对象重建的当前技术状态实际上并不执行重建,而是执行图像分类
。我们确定了引发这种行为的流行实验程序的各个方面,并讨论了改善当前研究状态的方法。
更多计算机视觉与图形学相关资料,请关注微信公众号:
计算机视觉与图形学实战

论文下载请在公众号内回复:paper
如果您认为上面的内容对您有一定的价值,可以对我们进行小小的赞助,来支持我们的工作,因为后续打算构建自己的网站,谢谢:
