动手学习深度学习——作业
1.分类任务
Fashion-mnist分类任务:针对
Fashion-MNIST
数据集,设计、搭建、训练机器学习模型,能够尽可能准确地分辨出测试数据地标签。
前言
1.1 利用VGG模型
import os
import sys
import time
import torch
from torch import nn, optim
import torch.nn.functional as F
import torchvision
import matplotlib.pyplot as plt
from torchvision import transforms
def load_data_fashion_mnist(batch_size, resize=None, root='./FashionMNIST'):
"""Download the fashion mnist dataset and then load into memory."""
trans = []
if resize:
trans.append(torchvision.transforms.Resize(size=resize))
trans.append(torchvision.transforms.ToTensor())
trans.append(torchvision.transforms.Normalize((0.1307,), (0.3081,)))
transform = torchvision.transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(root=root, train=True, download=True, transform=transform)
mnist_test = torchvision.datasets.FashionMNIST(root=root, train=False, download=True, transform=transform)
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=2)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=2)
return train_iter, test_iter
print('训练...')
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
batch_size = 64
train_iter, test_iter = load_data_fashion_mnist(batch_size)
def vgg_block(num_convs, in_channels, out_channels): #卷积层个数,输入通道数,输出通道数
blk = []
for i in range(num_convs):
if i == 0:
blk.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
else:
blk.append(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))
blk.append(nn.ReLU())
blk.append(nn.MaxPool2d(kernel_size=2, stride=2)) # 这里会使宽高减半 b*64*14*14
return nn.Sequential(*blk)
conv_arch = ((1, 1, 64), (1, 64, 128))
# 经过28/4=7
fc_features = 128 * 7 * 7 # c * w * h
fc_hidden_units = 2048 # 任意
def vgg(conv_arch, fc_features, fc_hidden_units=4096):
net = nn.Sequential()
# 卷积层部分
for i, (num_convs, in_channels, out_channels) in enumerate(conv_arch):
# 每经过一个vgg_block都会使宽高减半
net.add_module("vgg_block_" + str(i+1), vgg_block(num_convs, in_channels, out_channels))
# 全连接层部分
net.add_module("fc", nn.Sequential(nn.Flatten(),
nn.Linear(fc_features, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, 10)
))
return net
net = vgg(conv_arch, fc_features, fc_hidden_units)
print(net)
def evaluate_accuracy(data_iter, net, device=None):
if device is None and isinstance(net, torch.nn.Module):
# 如果没指定device就使用net的device
device = list(net.parameters())[0].device
net.eval()
acc_sum, n = 0.0, 0
with torch.no_grad():
for X, y in data_iter:
acc_sum += (net(X.to(device)).argmax(dim=1) == y.to(device)).float().sum().cpu().item()
n += y.shape[0]
net.train() # 改回训练模式
return acc_sum / n
def train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs):
net = net.to(device)
print("training on ", device)
loss = torch.nn.CrossEntropyLoss()
best_test_acc =0
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, batch_count, start = 0.0, 0.0, 0, 0, time.time()
for X, y in train_iter:
X = X.to(device)
y = y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
# l2= torch.tensor(0).float().cpu()
# l = loss(y_hat, y).float().cpu()
# for param in net.parameters():
# l2 += torch.norm(param, 2).float().cpu()
# l=(l+l2).cpu()
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
test_acc = evaluate_accuracy(test_iter, net,device)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec'
% (epoch + 1, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start))
if test_acc>best_test_acc:
print('find best! save at model/best.pth')
best_test_acc = test_acc
torch.save(net.state_dict(), 'model/best.pth')
lr, num_epochs = 0.001, 10
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs)
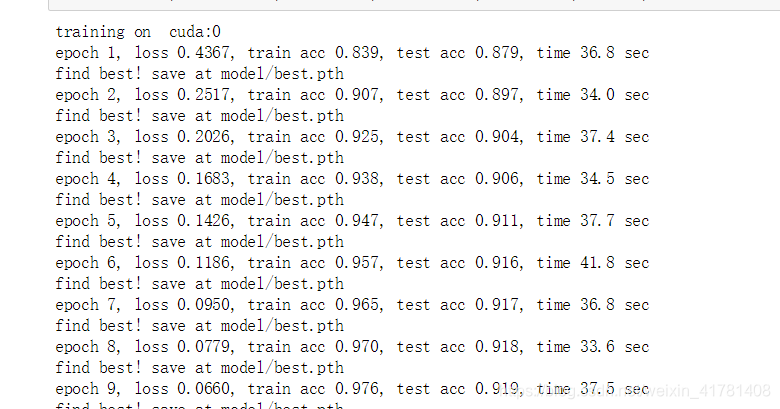
结果
利用vgg 设计的网络差不多测试结果准确率能够达到0.92。
1.2 使用Resnet
import os
import sys
import time
import torch
from torch import nn, optim
import torch.nn.functional as F
import torchvision
import matplotlib.pyplot as plt
from torchvision import transforms
def load_data_fashion_mnist(batch_size, resize=None, root='./FashionMNIST'):
"""Download the fashion mnist dataset and then load into memory."""
trans = []
if resize:
trans.append(torchvision.transforms.Resize(size=resize))
trans.append(torchvision.transforms.ToTensor())
trans.append(torchvision.transforms.Normalize((0.1307,), (0.3081,)))
transform = torchvision.transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(root=root, train=True, download=True, transform=transform)
mnist_test = torchvision.datasets.FashionMNIST(root=root, train=False, download=True, transform=transform)
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=2)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=2)
return train_iter, test_iter
print('训练...')
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
batch_size = 64
train_iter, test_iter = load_data_fashion_mnist(batch_size)
class Residual(nn.Module): # 本类已保存在d2lzh_pytorch包中方便以后使用
#可以设定输出通道数、是否使用额外的1x1卷积层来修改通道数以及卷积层的步幅。
def __init__(self, in_channels, out_channels, use_1x1conv=False, stride=1):
super(Residual, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, stride=stride)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
return F.relu(Y + X)
def resnet_block(in_channels, out_channels, num_residuals, first_block=False):
if first_block:
assert in_channels == out_channels # 第一个模块的通道数同输入通道数一致
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(in_channels, out_channels, use_1x1conv=True, stride=2))
else:
blk.append(Residual(out_channels, out_channels))
return nn.Sequential(*blk)
net = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
net.add_module("resnet_block1", resnet_block(32, 32, 2, first_block=True))
net.add_module("resnet_block2", resnet_block(32, 64, 2))
net.add_module("resnet_block3", resnet_block(64, 128, 2))
net.add_module("resnet_block4", resnet_block(128, 256, 2))
class GlobalAvgPool2d(nn.Module):
# 全局平均池化层可通过将池化窗口形状设置成输入的高和宽实现
def __init__(self):
super(GlobalAvgPool2d, self).__init__()
def forward(self, x):
return F.avg_pool2d(x, kernel_size=x.size()[2:])
class FlattenLayer(torch.nn.Module):
def __init__(self):
super(FlattenLayer, self).__init__()
def forward(self, x): # x shape: (batch, *, *, ...)
return x.view(x.shape[0], -1)
net.add_module("global_avg_pool", GlobalAvgPool2d()) # GlobalAvgPool2d的输出: (Batch, 512, 1, 1)
net.add_module("fc", nn.Sequential(FlattenLayer(), nn.Linear(256, 10)))
def train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs):
net = net.to(device)
print("training on ", device)
loss = torch.nn.CrossEntropyLoss()
best_test_acc =0
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, batch_count, start = 0.0, 0.0, 0, 0, time.time()
for X, y in train_iter:
X = X.to(device)
y = y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
test_acc = evaluate_accuracy(test_iter, net,device)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec'
% (epoch + 1, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start))
if test_acc>best_test_acc:
print('find best! save at model/best.pth')
best_test_acc = test_acc
torch.save(net.state_dict(), 'model/best2.pth')
lr, num_epochs = 0.001, 10
optimizer = torch.optim.Adm(net.parameters(), lr=lr)
train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs)
结果显示
训练10轮差不多能达到0.925.

参考:https://github.com/monkeyDemon/Learn_Dive-into-DL-PyTorch
版权声明:本文为weixin_41781408原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。