
是什么:
apriori算法是第一个关联规则挖掘算法,利用逐层搜索的迭代方法找出数据库中的项集(项的集合)的关系,以形成规则,其过程由连接(类矩阵运算)与剪枝(去掉没必要的中间结果)组成。是一种挖掘关联规则的频繁项集算法,一种最有影响的挖掘布尔关联规则频繁项集的算法。核心思想是通过候选集生成和情节的向下封闭检测两个阶段来挖掘频繁项集。
关联规则挖掘,在最早提出时,是为了发现交易数据库中不同商品之间的联系规则。刻画顾客购买行为模型,指导商家科学地进行进货,库存以及货架设计等。
改进的算法有:并行关联规则挖掘Parallel Association Rule Mining,以及数量关联规则挖掘Quantitive Association Rule Mining。提高挖掘规则算法的效率,适应性,可用性以及应用推荐。
频繁项集的评估标准:支持度,置信度,提升度三个方面。
应用领域:在商业,网络安全广泛使用。通过对数据的关联性进行了分析和挖掘,挖掘出的这些信息在决策制定过程中具有重要的参考价值。
在消费市场价格分析中,能够很快求出各种产品之间的价格关系和它们之间的影响,可以瞄准目标客户,采用个人股票行市,最新细心,特殊的市场推广活动或其他的一些特殊信息手段,减少广告预算和增加收入。预测客户的消费习惯。
相关概念:
支持度:a和b同时出现的概率,或者是几个关联的数据在数据集中出现的次数占总数据集的比重。
置信度:a和b同时出现的概率占a出现概率的比值,或者是一个数据出现后,另一个数据出现的概率,或者说数据的条件概率。
提升度:表示含有y的条件下, 同时含有x的概率,与x总体发生的概率之比。提升度体现了x和y之间的关联关系,提升度大于1则xy是有效的强关联规则,小于等于1则是无效的强关联规则。
频繁项集:频繁项集挖掘可以告诉我们在数据集中经常一起出现的变量,为可能的决策提供一些支持。频繁项集挖掘是关联规则,相关性分析,因果分析,序列项集,局部周期性等许多数据挖掘任务的基础。应用在购物车分析,网页预取,交叉购物,个性化网站等。
强关联规则:满足最小支持度和最小置信度的关联规则。
相类似的算法:
PrefixSpan
CBA
FP-Tree
GSP
FP-growth 算法
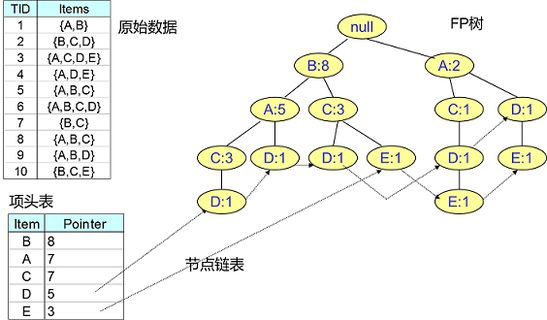
属于关联分析算法,采取的分治策略如下:将提供频繁项集的数据库压缩到一颗频繁模式树FP-Tree ,保留项集关联信息。在算法中使用了一种称为频繁模式树的数据结构,fp-tree是一种特殊的前缀树,有频繁项头表和项前缀树构成。用于改善Apriori算法,加快整个挖掘过程。
相关概念:
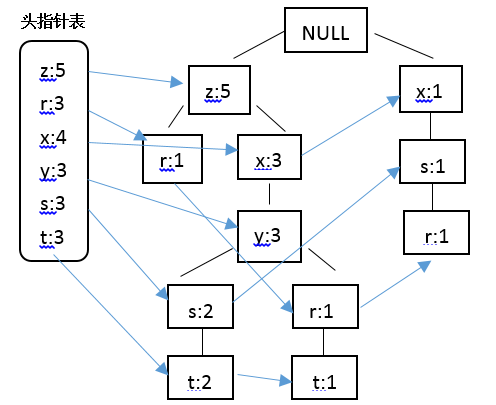
FP-Tree :将事务数据表中的各个事务数据项按照支持度排序后,把每个事务中的数据项按降序一次插入到一颗以null为根节点的树中,同时在每个节点处记录该节点出现的支持度。
条件模式基:包含FP-Tree中与后缀模式一起出现的前缀路径的集合。
条件树:将条件模式基按照FP-Tree的构造原则形成的一个新的FP-Tree。
基本思路:不断的迭代FP-Tree的构造和投影过程。
算法描述:
- 对于每个频繁项,构造ta 的条件投影数据库和投影FP-Tree
- 对每个新构建的FP-Tree重复这个过程,知道构造新的FP-Tree为空,或者只包含一条路径。
- 当构造的FP-Tree为空时,其前缀即为频繁模式,当只包含一条路径时,通过枚举所以可能组合并与此树的前缀连接即可得到频繁模式。
该算法的流程为:首先构造FP树,然后利用ta来挖掘频繁项集。在构造fp树时,需要对数据集扫描两次,一次为用来统计频率(频次和频率),第二次扫描至考虑频繁项集。
缺点:
- 对数据库扫描数次过多
- apriori会产生大量的中间项集
- 采用唯一支持度
- 算法的适应面窄
参考:
https://bainingchao.github.io/2018/09/27/%E4%B8%80%E6%AD%A5%E6%AD%A5%E6%95%99%E4%BD%A0%E8%BD%BB%E6%9D%BE%E5%AD%A6%E5%85%B3%E8%81%94%E8%A7%84%E5%88%99Apriori%E7%AE%97%E6%B3%95/bainingchao.github.io
数据挖掘十大算法–Apriori算法_小硒—代码无疆-CSDN博客blog.csdn.net

Suranyi:Apriori 算法简介及 python3实现zhuanlan.zhihu.com

机器学习(九)-FP-growth算法 – Yabea – 博客园www.cnblogs.com
FP Tree算法原理总结 – 刘建平Pinard – 博客园www.cnblogs.com
FP-growth算法–原理_jmhIcoding-CSDN博客blog.csdn.net
Superman:FP-Growth算法简介zhuanlan.zhihu.com
