
随着近年来公有云技术及云基础设施的发展,越来越多的企业转为使用公有云来托管自己的服务。云数据库因为数据可靠性、资源弹性、运维便捷行,云上数据库服务也正成为企业数据管理的较好的选择。
本文以叮咚买菜自建MongoDB数据库整体迁移上腾讯云MongoDB为背景,分享叮咚买菜上云过程中的遇到的疑难问题及对应的性能优化解决方法等,主要包括以下分享内容
:
-
云上MongoDB版本选型
-
安全上云及切换方案
-
叮咚买菜业务侧性能优化
-
上云遇到的疑难问题及解决方法
-
自建上云收益
1.叮咚买菜自建MongoDB上云背景

叮咚买菜业务以生鲜即时配送为核心,兼备新零售电商和生鲜供应链的特点,对高并发和数据一致性有硬性要求。在快速扩张的过程中,很多服务技术选型以MongoDB作为其主要数据存储。相比其他非即时业务场景,叮咚买菜对数据库访问时延、稳定性、数据一致性、数据安全性也有更苛刻的要求。
借助腾讯云MongoDB产品完善的自动化运维、数据安全备份回档、云弹性等能力,可以快速补齐叮咚买菜的核心MongoDB数据库基础技术能力,确保数据团队可以游刃有余的支撑业务开发。
叮咚数据团队基于自建成本、物理资源不足等原因,经过综合评估,决定把MongoDB数据迁移到腾讯云MongoDB上。
2.云上版本推荐及切换方案
业务正式开始迁移前,结合叮咚DBA和业务同学了解具体场景、MongoDB集群部署方式、业务MongoDB用法、内核版本、客户端版本、客户端driver类型等。提前了解到用户第一手信息:
-
自建MongoDB版本较低
-
客户端driver主要包括java和PHP
-
集群部署都带tag
-
集群存在较频繁的抖动问题
2.1. 腾讯云MongoDB内核版本推荐
叮咚自建MongoDB因历史原因一致保持在官方MongoDB-3.2版本,在一些场景存在性能瓶颈,例如用户主从读写分离时候会遇到读超时等问题。考虑到用户对性能要求较高,同时结合以下技术点,最终推荐用户使用腾讯云MongoDB-4.0版本,主要原因如下:
-
非阻塞从节点读(叮咚买菜遇到的低版本主要问题)
MongoDB-4.x开始,引入了非阻塞的从节点读(Non-Blocking Secondary Reads),彻底解决了3.x版本从节点批量重放oplog时候加全局ParallelBatchWriterMode类型MODE_X锁引起的读从节点读阻塞问题。
-
存储引擎优化(低版本的主要问题)
相比3.2版本,4.0对存储引擎做了很多优化,例如cache脏数据淘汰、锁粒度、更全的引擎参数调整支持等,极大的解决了低版本后台加索引、大流量读写等引起的客户端访问阻塞问题。
-
更好的写性能
相比3.2版本,除了上面提到的非阻塞从节点读引起的读性能提升外,在写性能方面4.0也更有优势。
-
更多有用新功能
经过几个大版本迭代,4.0版本相比3.2新增了非常多有用功能,例如Retryable Writes(可重试写)、Change Streams(变更流操作)、Tunable Consistency(更强的可调一致性)、Schema Validation(模式检查)、安全功能增强、事务支持、更丰富的操作类型等。
-
分片模式集群扩容balance效率更高
4.0版本相比3.2版本,增加分片扩容后的数据迁移采用更好的并发迁移策略,扩容数据迁移速率更高。
-
为何不选择更高的MongoDB版本
MongoDB版本越高功能越多,例如更高版本支持分布式事务、多字段hash片建支持等。由于叮咚主要是副本集集群,并且对这些新功能需求不强烈,同时综合集群稳定性考虑,最终选择4.0版本。
-
客户端driver版本兼容性,减少用户客户端改造成本
由于内核版本较低,如果升级到高版本,首先需要考虑对应客户端driver版本是否兼容低版本driver。如果客户端版本和内核不兼容,则需要进行driver升级甚至代码改造,因此客户端driver兼容性也是MongoDB内核版本选择的一个关键指标。叮咚技术团队经过验证,确认客户端版本完全兼容4.0内核,代码无需任何改造。
常用客户端driver与MongoDB内核版本兼容性详见:
|
Driver类型 |
官方兼容性说明 |
|
Java |
|
|
golang |
|
|
php |
|
|
其他 |
2.2. 安全上云迁移方案
叮咚自建MongoDB集群包含部分重要数据,务必保证迁移的数据一致性。常用通用迁移方案如下:
-
通用迁移方案
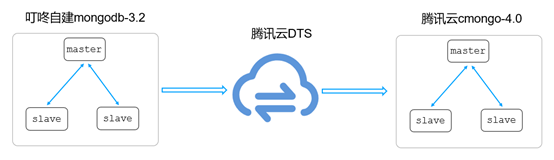
上面的迁移方案步骤如下:
步骤1
:腾讯云DTS for MongoDB全量+增量方式实时同步自建数据到云上MongoDB
步骤2
:选择凌晨业务低峰期判断DTS延迟进度,延迟追上后,业务停写
步骤3
:确保源集群最后一条oplog同步到目标集群,客户端IP地址切到目标集群
通过上面的操作步骤,最终完成不同版本的MongoDB上云。但是,该上云方案有个风险,假设业务切换到目标新集群后部分读写有问题,这时候就需要回滚到源自建集群。由于切换到新集群过程后,可能部分写流量到了目标集群,这时候目标集群相比源集群就会有更多的数据。这时候,切回到源集群后,也存在数据不一致的情况,即使把目标集群增量oplog回写到源集群,也可能存在乱序写入引起的数据混乱问题。
-
优化方案
为了解决极端情况下回滚引起的数据丢失、数据混乱、数据不一致等问题,叮咚业务集群采用如下更加安全可回滚切割方案:
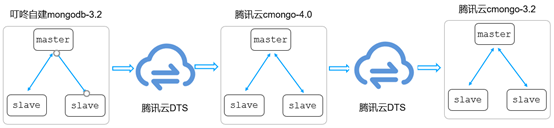
当业务流量从源叮咚自建MongoDB-3.2集群切换到腾讯云MongoDB-4.0后,如果存在版本兼容、业务访问异常等问题,则可直接回滚到腾讯云MongoDB-3.2版本,由于回滚集群和源自建集群版本一致,并且通过DTS实时同步,因此,可以一定程度保证回滚流程数据不混乱、不冲突、不丢失,也可保证切割出问题时候的快速回滚。
由于叮咚业务MongoDB存储了部分重要数据,不允许数据丢失及混乱,对数据一致性要求极高。当前方案在切换过程中,仍存在向前回滚时数据延迟、连接串更换后应用写错等风险。因此为了确保实时同步及回滚数据一致性万无一失,除了DTS的回滚方案,
叮咚在业务侧增加了几层保护
:通过订阅和扫描,针对核心库的数据进行校验;通过流量检测进行业务反查;如果出现业务数据不一致,可以通过工具进行可灰度、可控速的方式进行补齐。
3.叮咚自建MongoDB上云遇到的问题及优化解决方法
叮咚不同业务从3.2版本上云升级到4.0版本过程中,遇到了一些性能瓶颈问题,主要包括以下问题:
-
腾讯云MongoDB短链接性能优化
-
叮咚业务侧短链接优化
-
Session定期刷新引起的集群抖动问题
3.1.短链接性能优化解决方法
以叮咚集群其中某业务为例,该业务部分接口使用PHP driver,因此会涉及到大量的MongoDB短链接访问,以下分别说明叮咚自建集群短链接瓶颈优化及腾讯云MongoDB短链接优化过程。
3.1.1. PHP业务短链接瓶颈原因
PHP一次请求访问,需要如下交互过程日志如下:
2021-11-04T12:45:36.621+0800 I NETWORK [conn6] received client metadata from …2021-11-04T12:45:36.621+0800 I COMMAND [conn6] command admin.$cmd command: isMaster …2021-11-04T12:45:36.622+0800 I COMMAND [conn6] command adminxx.users command: saslStart …2021-11-04T12:45:36.626+0800 I COMMAND [conn6] command admin.$cmd command: saslContinue …2021-11-04T12:45:36.627+0800 I ACCESS [conn6] Successfully authenticated as principal …2021-11-04T12:45:36.627+0800 I COMMAND [conn6] command adminxx.users command: saslContinue2021-11-04T12:45:36.627+0800 I COMMAND [conn6] command admin.$cmd command: ping…2021-11-04T12:45:36.627+0800 I COMMAND [conn6] command x.test command: find { find: "test"2021-11-04T12:45:37.636+0800 I NETWORK [conn6] end connection …
从上面的简化日志可以看出,一次find请求预计需要下面多个操作步骤,并且多次才能完成,主要流程如下:
-
TCP三次握手链接
-
客户端发送isMaster命令给服务端获取所连节点的一些状态信息、协议兼容信息等
-
进行sasl多次认证交互
-
Ping探测获取往返时延
-
真正的业务访问,例如这里的find查询请求
-
四次挥手关闭本次链接对应请求
上面的流程体现出一次访问,不仅仅建链、断链开销、还有多次认证交互以及其他额外交互开销,最终有效访问只占用极少一部分开销,无效访问浪费了系统大部分开销。此外,PHP业务单次访问的总时延增加,单次访问总时延如下:
PHP单次访问时延=建链时间+isMaster()交互时间+认证时间+ping时间+数据访问时间
3.1.2.叮咚自建MongoDB集群短链接部署优化
该用户集群虽然数据量不是很大,但是流量较高,读写总流量数万/秒,如果直接采用普通副本集模式集群,则存在MongoDB存储节点因为短链接流量高引起的负载问题。叮咚自建MongoDB为了解决短链接访问引起的瓶颈问题,采用如下架构:
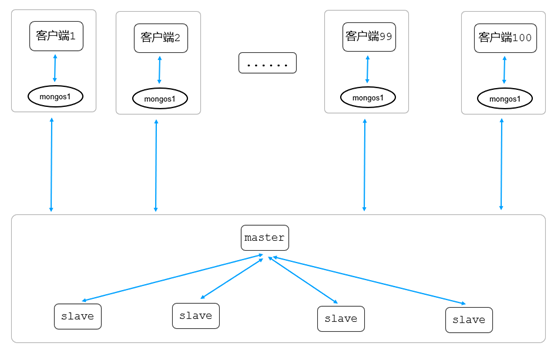
上图为某业务集群,业务读写流量较高,总流量数万/S,其中有一部分PHP业务。考虑到PHP业务短链接每次访问需要多次认证交互,会增加mongo内核压力,因此用户采用分片架构集群部署,单个分片。客户端程序和mongos部署在同一台服务器,每个客户端通过本地mongodb:///var/run/mongodb-order.sock/访问,通过该架构来解决短链接带来的性能瓶颈。
3.1.3.腾讯云MongoDB部署架构及优化过程
-
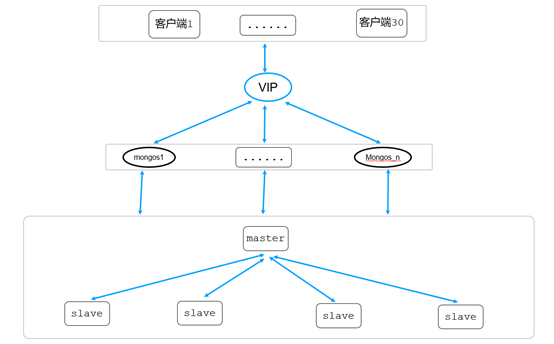
MongoDB部署架构
腾讯云MongoDB采用叮咚类似架构,唯一区别是mongos代理叮咚部署在客户端机器本地部署,MongoDB则是独立部署,云上MongoDB部署架构如下:
-
MongoDB短链接优化
在业务正式上线前,MongoDB团队对PHP短链接进行了提前的摸底测试(后端分片无瓶颈,压一个mongos),测试结果存在如下现象:
-
服务器CPU空闲
-
listener线程CPU消耗较高
-
短链接并发越高链接报错比例越高。
-
后端分片MongoDB无瓶颈
通过分析,netstat查看发现大量的SYN_RECV 、FIN_WAIT状态的链接,同时客户端大量链接报错,说明mongos代理处理链接不及时,这和MongoDB内核网络线程模型有较大的关系,MongoDB所有客户端请求由listener线程进行accept处理,accept获取到一个新链接,则创建一个线程,该线程负责该链接以后的所有数据读写。
一个mongos进程只有一个listener线程,当客户端链接并发较高的时候,很容易造成链接排队,最终造成客户端链接超时。不过,该瓶颈可以通过部署多个mongos来解决,多个mongos就会有多个listener线程,accept处理能力就会增强。
最终,综合成本及性能考虑,选择多个最低规格(2PU/4G)的mongos来解决短链接瓶颈。
除了多mongos部署外,还对MongoDB内核listen backlog队列长度进行了适当的调整,缓解队列满引起的客户端链接异常问题。
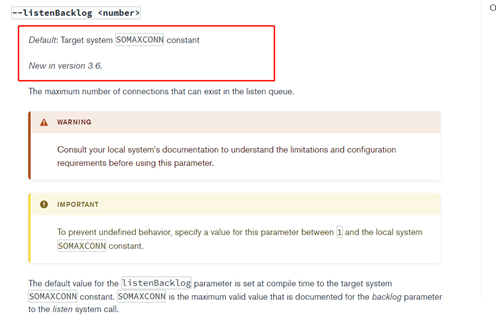
net.listenBacklog配置在3.6版本开始支持,调研了常用服务端中间件nginx、redis,这类中间件都支持listen backlog配置,默认取值分别如下:
Nginx默认取值:511
Redis默认取值:511
MongoDB默认取值:SOMAXCONN
SOMAXCONN也就是操作系统/proc/sys/net/core/somaxcon文件中的值,线上默认取值128。修改somaxcon为10240,配置net.listenBacklog为511,保持和nginx、redis推荐默认值511 一致。通过测试,net.listenBacklog调整后,4C规格测试,短链接异常超时现象会有较大缓解。
|
listenBacklog配置 |
测试结果 |
|
128 |
2000并发约10%左右请求链接报错 |
|
511 |
2000并发无任何链接报错 |
3.2.Session定期刷新业务抖动优化解决过程
3.2升级到4.0版本上云过程中,除了用户短链接PHP瓶颈外,另外一个就是session会话定期刷新引起的业务抖动问题。
3.2.1.业务抖动现象
用户从3.2版本升级到腾讯云4.0版本后,腾讯云MongoDB集群流量监控图如下:
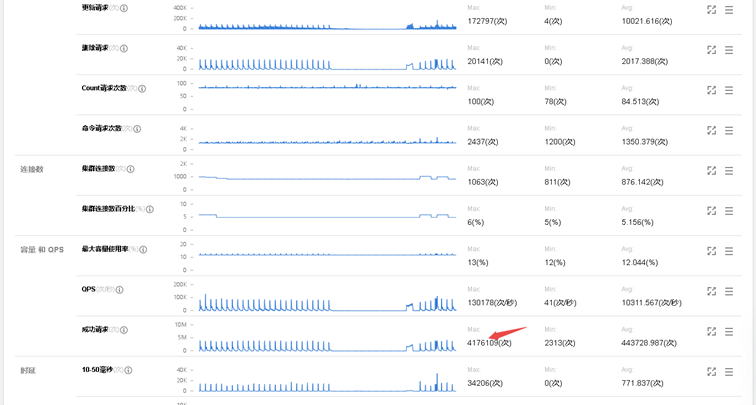
如上图所示,整个现象如下:
-
update周期性流量尖刺,尖刺周期5分钟
-
delete周期性流量尖刺,尖刺周期30分钟
-
流量尖刺过程中,时延也对应增加,周期性抖动
-
CPU周期性消耗
3.2.2.线下模拟测试
当客户端众多,连接数过高的情况下,副本集主节点有瞬间大量update甚至delete操作,mongostat和mongotop监控如下(测试条件:500并发短链+500并发长链接,进行insert持续性写入测试):
-
mongostat监控发现大量未知update操作,甚至远超过正常insert流量
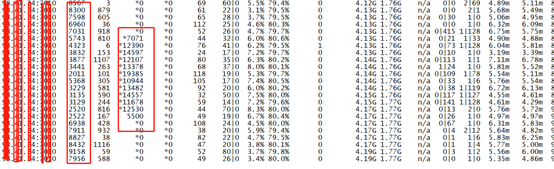
从上面可以看出,存在大量update更新操作,同时该操作类型统计甚至超过正常的insert写入。
-
mongotop确定流量来自于哪一个表
500并发短链接及500并发长链接同时进行持续性insert写入测试,发现mongostat监控中存在大量的update更新操作,而我们的测试中没有进行update更新操作,于是通过mongotop获取update操作来源,监控结果入下图所示:
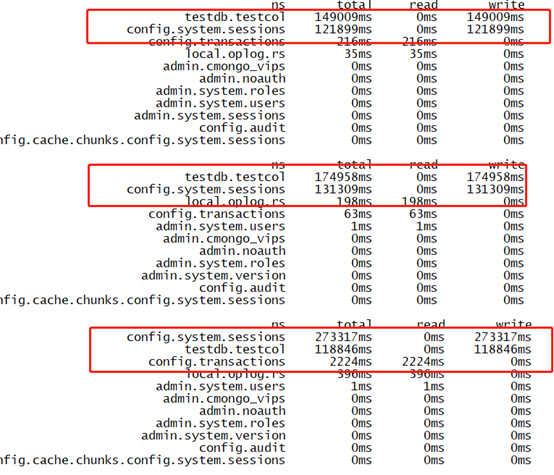
从上图可以看出,大量的update操作来自于config库的system.sessions表,这是一个潜在隐患。
-
其他潜在隐患(system.sessions表集中过期)
system.sessions表默认30分钟过期,由于session会话数据都是集中刷新到system.sessions表,因此该表还存在集中过期的情况,集中过期将让update定期更新和过期操作叠加,进一步加重集群抖动。
3.2.3.session模块内核实现
从MongoDB-3.6版本开始,MongoDB开始逐步支持单文档事务,从而开始引入session逻辑会话模块。不论是副本集mongod还是分片集群的mongos,都会启动一个定时器刷新cache中缓存的session信息到config库的system.session表中。
通过走读MongoDB内核代码,确定该问题是对system.sessions表做更新引起,内核对应主要代码实现由LogicalSessionCache模块负责session会话管理操作。下面通过一次完整的客户端访问为例,分析session模块核心原理及主要代码实现:
-
步骤1
:客户端发送isMaster命令到服务端,服务端通知客户端是否支持session管理

客户端通过发送isMaster命令给服务端,如果服务端支持session会话管理模块,则返回session会话超时时间信息给客户端。
-
步骤2
:客户端请求携带”lsid”信息发送给服务端

服务端收到客户端”lsid”信息后,检查本地cache是否有该session 信息,如果本地cache没有该session信息则添加到本地。一个”lsid”代表一个session会话信息。
如果业务没有创建session信息,则默认对一个链接创建一个会话信息,链接和session一一对应。
-
步骤3
:启动定时器,定期把cache中的session信息system.sessions表中
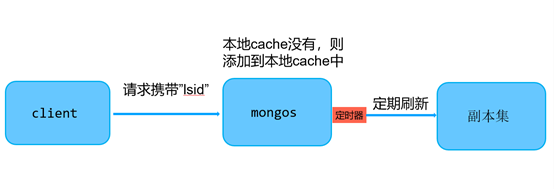
mongos和mongod实例都会启动一个后台线程,定期把cache中的所有sessions信息同步到config库的system.sessions表中。同步的session会话信息可以分为以下两类。
1.activeSessions活跃session
activeSessions会话信息主要包括一个定时器周期活跃的session信息(一个定时器周期该session对应的客户端有访问MongoDB)和新创建的session会话信息。
mongos或者mongod会定期把activeSessions信息一条一条一次性update到副本集对应system.sessions表中。
2.endSessions会话信息
endsessions会话信息主要包括客户端显示通过endSession命令结束的会话信息和空闲时间超过system.sessions表对应TTL过期时间的会话信息。
客户端主动触发endSession的session会话信息,mongos也是在同一个定时器中通过remove操作system.sessions表,从而实现cache和system.sessions表的一致性。Remove操作和活跃session的update操作在同一个定时器完成,update更新完毕后,立马进行remove操作。
如果是短链接,并且关闭链接前主动进行了endSession结束会话操作,副本集可能还存在system.sessions表大量remove的操作。
如果session长时间空闲,则通过system.sessions表的TTL索引来触发本地cache的清理工作。
-
定时器相关
定时器默认定时时间5分钟,可以通过logicalSessionRefreshMillis配置。
-
System.sessions表TTL过期时间
默认30分钟过期。
-
会话统计信息
会话统计信息通过“db.serverStatus().logicalSessionRecordCache”命令获取,如下图所示:
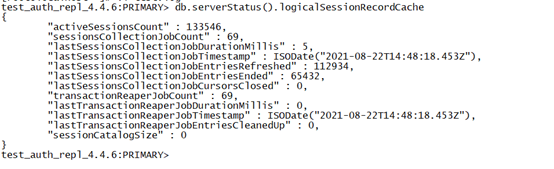
logicalSessionRecordCache统计中,可以分为两类:session类统计和transaction事务类统计,核心统计项功能说明如下:
|
统计类型 |
统计项 |
统计内容说明 |
|
Session统计 |
activeSessionsCount |
当前活跃会话数 |
|
lastSessionsCollectionJobEntriesRefreshed |
上一个周期刷新到system.session表的活跃会话数 |
|
|
lastSessionsCollectionJobEntriesEnded |
上一个周期刷新到system.session表的endSessions会话数 |
|
|
lastSessionsCollectionJobCursorsClosed |
上一个周期内清理的 |
|
|
Transaction统计 |
lastTransactionReaperJobEntriesCleanedUp |
本周期内清理的transactions表数据条数 |
3.2.4. Session问题MongoDB内核优化解决
从上面的原理可以看出,业务抖动主要因为cache中的session定期集中式刷新,以分片MongoDB集群为例,内核层面可以通过以下方式优化缓解、也可以通过增加内核配置开关规避。
-
无MongoDB内核开发能力:参数调优、部署优化
如果没有MongoDB内核开发能力,可以通过以下方法进行session内核参数调优和部署方式调整来缓解问题:
方法一:mongos及副本集mongod部署时间打散,避免所有节点定时器同时生效
当前集群默认启动后,所有代理和mongod几乎都是同时启动的,代理启动时差较小,session定时器可能同一时间触发,可以手动打散到不同时间点重启,包括所有mongos和副本集mongod。
方法二:短链接业务考虑定时刷新周期适当调短
短链接默认每次请求会生成一个session会话,访问完毕后不会主动通知MongoDB内核释放session,因此,session在定时周期内会大量挤压,可以考虑缩短定时时间来规避大量短连接session的定期刷新操作。例如logicalSessionRefreshMillis从默认5分钟调整为30秒,则集中式的session刷新会散列到多个不同时间点。
方法三:长链接业务适当调大定时刷新周期
实际测试验证中,默认官方driver长链接(包括golang、java、c客户端测试验证)都是一个链接对应一个session会话id,也就是同一个请求客户端携带的”lsid”保持不变。MongoDB内核实现中,只要每一个链接对应的定时周期内有一次以上活跃请求访问,则会再次缓存该session id,session id刷新到config.sessions表中后,cache中会清除。
从上面的长链接session cache流程可以看出,一般长链接用户都是连接池配置,总连接数越高session也会越高。因此长链接可以通过以下调整减少session定期刷新的影响:
-
控制连接池最大连接数,减少cache中的session总量
-
适当调大logicalSessionRefreshMillis刷新周期,减少频繁刷新的影响
-
内核增加禁用session会话功能开关
在3.6以下版本,MongoDB是没有session会话管理模块的,为了支持事务和可重试写功能而引入。
分析了MongoDB-c-driver客户端,发现客户端第一次报文交互是否携带“lsid”给服务端是根据isMaster的返回内容中是否携带由” logicalSessionTimeoutMinutes”来决定的,如下:
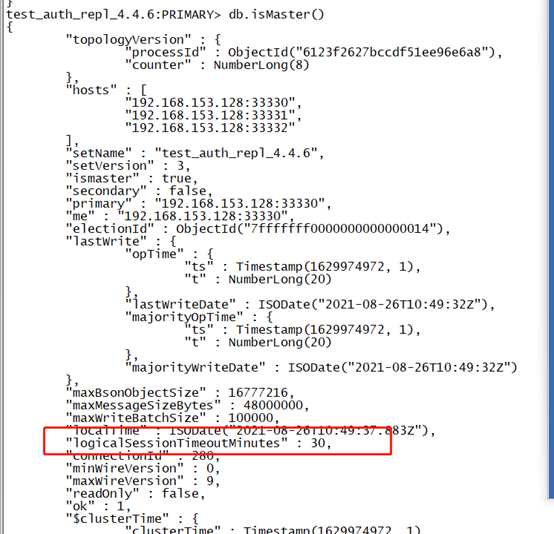
实际上用户从MongoDB-3.2版本升级到4.0,用户也不需要事务、可重试写功能,客户端完全没必要默认走session id生成流程。如果客户端不触发session id(也就是报文交互中的”lsid”),则就不会触发Mongo服务端内核启用session定期刷新功能模块。因此,可以考虑在MongoDB内核代码实现中,客户端isMaster获取相关信息的时候,不返回“logicalSessionTimeoutMinutes”信息,这样客户端就不会生成”lsid”信息发送给服务端。

4.0官方代码默认写死,MongoDB内核实现增加session模块支持开关,如果业务没有事务等需求,内核不应答“logicalSessionTimeoutMinutes”信息给客户端,这样客户端认为服务端不支持该功能,就不会主动生成session id交互。
说明
:session会话模块功能开关支持,当前已验证c driver、java、php,测试验证session问题彻底解决,使用该功能切记对客户端进行提前验证,可能不同客户端对logicalSessionTimeoutMinutes处理逻辑不一致,特别是使用spring+MongoDB整合的客户端。
3.2.5.叮咚长链接session问题用户侧优化
叮咚用户某长链接通过腾讯云MongoDB提供的节点地址自己对集群也做了详细的流量监控,监控曲线如下图所示:
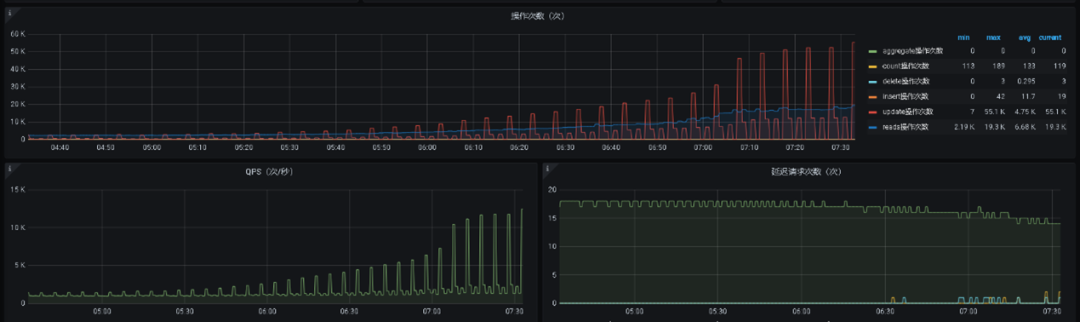
在对该长链接用户进行MongoDB内核优化前,可以看出流量周期性尖刺,并且发现一个归类:随着该java长链接流量qps越高,定期的sessionupdate尖刺越严重。
利用线上MongoDB进行复现,使用MongoDB官方java driver测试结果和之前的长链接分析一致,也就是一个链接一个session会话,也就是java服务定期最大的session update不会超过总连接数。但是叮咚用户的java服务通过MongoDB内核日志,看到如下现象:
Thu Sep 2 18:07:19.833 I COMMAND [conn48527] command xx.xxx command: insert { insert: "xx", ordered: true, $db: "xx", $clusterTime: { clusterTime: Timestamp(1630577239, 387), signature: { hash: BinData(0, B37C8600CE543BEE2D8085730AADD91CB13C14AF), keyId: 7002593870005403649 } }, lsid: { id: UUID("3ce872be-5a8d-4a1b-b656-8ba33b3cb15d") } } ninserted:1 keysInserted:2 numYields:0 reslen:230 locks:{ Global: { acquireCount: { r: 2, w: 2 } }, Database: { acquireCount: { w: 2 } }, Collection: { acquireCount: { w: 1 } }, oplog: { acquireCount: { w: 1 } } } protocol:op_msg 0msThu Sep 2 18:07:19.921 D COMMAND [conn48527] run command xx.$cmd { insert: "xxxx", ordered: true, $db: "xxx", $clusterTime: { clusterTime: Timestamp(1630577239, 429), signature: { hash: BinData(0, B37C8600CE543BEE2D8085730AADD91CB13C14AF), keyId: 7002593870005403649 } }, lsid: { id: UUID("ab3e1cb8-1ba1-4e03-bf48-c388f5fc49d1") } }Thu Sep 2 18:07:19.922 I COMMAND [conn48527] command xxx.xxx command: insert { insert: "oxxx", ordered: true, $db: "maicai", $clusterTime: { clusterTime: Timestamp(1630577239, 429), signature: { hash: BinData(0, B37C8600CE543BEE2D8085730AADD91CB13C14AF), keyId: 7002593870005403649 } }, lsid: { id: UUID("ab3e1cb8-1ba1-4e03-bf48-c388f5fc49d1") } } ninserted:1 keysInserted:2 numYields:0 reslen:230 locks:{ Global: { acquireCount: { r: 2, w: 2 } }, Database: { acquireCount: { w: 2 } }, Collection: { acquireCount: { w: 1 } }, oplog: { acquireCount: { w: 1 } } } protocol:op_msg 0msThu Sep 2 18:07:19.765 I COMMAND [conn48527] command xxx.xxx command: find { find: "xxx", filter: { status: { $in: [ 1, 2, 4, 5, 9, 11, 13, 3, 7, 15 ] }, order_number: "xxxxxxxxxxxxxxxxxxx", is_del: false }, sort: { _id: -1 }, $db: "xxx", $clusterTime: { clusterTime: Timestamp(1630577239, 375), signature: { hash: BinData(0, B37C8600CE543BEE2D8085730AADD91CB13C14AF), keyId: 7002593870005403649 } }, lsid: { id: UUID("ed1f0fd8-c09c-420a-8a96-10dfe8ddb454") } } planSummary: IXSCAN { order_number: 1 } keysExamined:8 docsExamined:8 hasSortStage:1 cursorExhausted:1 numYields:0 nreturned:4 reslen:812 locks:{ Global: { acquireCount: { r: 1 } }, Database: { acquireCount: { r: 1 } }, Collection: { acquireCount: { r: 1 } } } protocol:op_msg 0ms

从上面的日志可以看出,即使是同一个长链接上面的多次会话,客户端也会携带多个不同的”lsid”发送给MongoDB服务端,因此需要解决为何java服务同一个链接多次访问会生成多个session id,即”lsid”。
通过排查客户端,最终定位问题是客户端的埋点监控在升级到MongoDB-4.0后,触发每次请求生成一个新的”lsid”。
4.叮咚买菜自建上云收益总结
自建MongoDB迁移腾讯云MongoDB后,带来了如下收益:
-
通过梳理拆分,把一些核心的复杂的MongoDB集群,垂直拆分为多个集群,耦合性降低,稳定性提高
-
集群稳定性提高,上云前业务遇到的各种MongoDB访问毛刺和抖动问题得到了彻底解决
-
腾讯云MongoDB相比自建MongoDB性能更好,并能够充分利用云的弹性扩容能力,不用预留过多的硬件资源,从而节省了较大成本
-
腾讯云MongoDB完善的监控告警、数据备份回档、跨地域容灾、实时巡检、7×24小时在线服务等,使得可运维性、数据安全、故障预发现等能力得以增强
-
迁移到腾讯云,也可以利用腾讯云技术团队的技术优势,帮助分析定位解决一些MongoDB深层次的疑难技术问题
关于作者
叮咚买菜技术团队
:
叮咚买菜基础技术,支撑叮咚买菜核心业务的资源、数据、基础架构,是一支技术背景深厚、充满激情与理想、坚持同目标共进退,打胜仗的团队。尤其重视技术人才培养和发展成长,很多技术骨干都是内部成长发展起来的。
腾讯云MongoDB团队
:
腾讯云MongoDB当前服务于游戏、电商、社交、教育、新闻资讯、金融、物联网、软件服务等多个行业;MongoDB团队(简称CMongo)致力于对开源MongoDB内核进行深度研究及持续性优化(如百万库表、物理备份、免密、审计等),为用户提供高性能、低成本、高可用性的安全数据库存储服务。后续持续分享MongoDB在腾讯内部及外部的典型应用场景、踩坑案例、性能优化、内核模块化分析。