剑指 Offer 30. 包含min函数的栈
定义栈的数据结构,请在该类型中实现一个能够得到栈的最小元素的 min 函数在该栈中,调用 min、push 及 pop 的
时间复杂度都是 O(1)
。
示例:
MinStack minStack = new MinStack();
minStack.push(-2);
minStack.push(0);
minStack.push(-3);
minStack.min(); --> 返回 -3.
minStack.pop();
minStack.top(); --> 返回 0.
minStack.min(); --> 返回 -2.
提示:
各函数的调用总次数不超过 20000 次
[注意] 要求min操作的时间复杂度为 O(1).
解题思路:
普通栈的
push()
和
pop()
函数的复杂度为
O(1)
;而获取栈最小值
min()
函数需要遍历整个栈,复杂度为
O(N)
。
本题难点: 将
min()
函数复杂度降为
O(1)
,可通过建立辅助栈实现;
数据栈
A
: 栈
A
用于存储所有元素,保证入栈
push()
函数、出栈
pop()
函数、获取栈顶
top()
函数的正常逻辑。
辅助栈
B
: 栈
B
中存储栈
A
中所有
非严格降序
的元素,则栈
A
中的
最小元素始
终对应栈
B
的
栈顶
元素,即
min()
函数只需返回栈
B
的栈顶元素即可。
因此,只需设法维护好 栈
B
的元素,使其保持非严格降序,即可实现
min()
函数的
O(1)
复杂度。
即,s_min里面存的都是最小值
例如: s1 = { -2, 0, 3, -5, 6},
则: s_min = { -2, -2, -2, -5, -5}
class MinStack {
private:
stack<int> s1, s_min;
public:
/** initialize your data structure here. */
MinStack() {
while(!this->s1.empty()) this->s1.pop();
while(!this->s_min.empty()) this->s_min.pop();
s_min.push(INT_MAX);
}
void push(int x) {
this->s1.push(x);
this->s_min.push(std::min(x, s_min.top()));
}
void pop() {
this->s1.pop();
this->s_min.pop();
}
int top() {
return this->s1.top();
}
int _min() {
return this->s_min.top();
}
};
剑指 Offer 06. 从尾到头打印链表
输入一个链表的头节点,从尾到头反过来返回每个节点的值(用数组返回)。
示例 1:
输入:head = [1,3,2]
输出:[2,3,1]
限制:
0 <= 链表长度 <= 10000
我的思路:栈
class Solution {
public:
vector<int> reversePrint(ListNode* head) {
stack<int> stk;
vector<int> ans;
while(head!=nullptr)
{
stk.push(head->val);
head = head->next;
}
while(!stk.empty())
{
ans.push_back(stk.top());
stk.pop();
}
return ans;
}
};
注意,递归 等价于 栈
class Solution {
public:
vector<int> reversePrint(ListNode* head) {
if(!head)
return {};
vector<int> a=reversePrint(head->next);
a.push_back(head->val);
return a;
}
};
复杂性分析
- 时间复杂度:O(n)。正向遍历一遍链表,然后从栈弹出全部节点,等于又反向遍历一遍链表。
- 空间复杂度:O(n)。额外使用一个栈存储链表中的每个节点。
方法二:链表反转
class Solution {
public:
vector<int> reversePrint(ListNode* head) {
vector<int> ans;
if (head==nullptr) return ans;
// 反转链表
ListNode* cur = head; // 当前结点
head = nullptr; // 前一个结点
/* 每次循环将 head,cur同时向后移动一次, 且👀需要一个temp变量来记录剩余链表 */
while (cur!=nullptr) // 当cur结点移动到最后的nullptr时,反转结束; head恰好指向尾结点。
{
ListNode* temp = cur->next; // 用来记录链表断开后的 剩余链表
cur->next = head; // 断开当前结点,并将其指向前一个结点
head = cur; // head向后移动
cur = temp; // cur向后移动
}
while (head)
{
ans.push_back(head->val);
head = head->next;
}
return ans;
}
};
时间复杂度:O(n),
空间复杂度:O(1) 不需要额外的stack开支
方法三:反转vector
class Solution {
public:
vector<int> reversePrint(ListNode* head) {
vector<int> result;
while (head) {
result.push_back(head->val);
head = head->next;
}
int len = result.size();
for (int i = 0; i < len / 2; i++) {
swap(result[i], result[len-i-1]);
}
return result;
}
};
剑指 Offer 35. 复杂链表的复制
请实现 copyRandomList 函数,复制一个复杂链表。在复杂链表中,每个节点除了有一个 next 指针指向下一个节点,还有一个 random 指针指向链表中的任意节点或者 null。
示例 1:
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
示例 2:
输入:head = [[1,1],[2,1]]
输出:[[1,1],[2,1]]
示例 3:
输入:head = [[3,null],[3,0],[3,null]]
输出:[[3,null],[3,0],[3,null]]
示例 4:
输入:head = []
输出:[]
解释:给定的链表为空(空指针),因此返回 null。
提示:
-10000 <= Node.val <= 10000
Node.random 为空(null)或指向链表中的节点。
节点数目不超过 1000 。
方法一:回溯 + 哈希表
本题要求我们对一个特殊的链表进行深拷贝。如果是普通链表,我们可以直接按照遍历的顺序创建链表节点。而本题中因为随机指针的存在,当我们拷贝节点时,
「当前节点的随机指针指向的节点」可能还没创建
,因此我们需要变换思路。
一个可行方案是,我们
利用回溯的方式,让每个节点的拷贝操作相互独立
。对于当前节点,我们首先要进行拷贝,然后我们进行「当前节点的后继节点」和「当前节点的随机指针指向的节点」拷贝,拷贝完成后将创建的新节点的指针返回,即可完成当前节点的两指针的赋值。
具体地,我们用
哈希表
记录每一个节点对应新节点的创建情况。
-
遍历该链表的过程中,我们
检查「
当前节点的
后继节点
」和「当前节点的
随机指针
指向的节点
」的创建情况
。 - 如果这两个节点中的任何一个节点的新节点没有被创建,我们都立刻递归地进行创建。
当我们拷贝完成,回溯到当前层时,我们即可完成当前节点的指针赋值。注意一个节点可能被多个其他节点指向,因此我们可能递归地多次尝试拷贝某个节点,为了防止重复拷贝,我们需要首先检查当前节点是否被拷贝过,如果已经拷贝过,我们可以直接从哈希表中取出拷贝后的节点的指针并返回即可。
在实际代码中,我们需要特别判断给定节点为空节点的情况。
class Solution {
public:
unordered_map<Node*, Node*> cachedNode;
Node* copyRandomList(Node* head) {
if (head == nullptr) {
return nullptr;
}
if (cachedNode.count(head)==0) {
Node* headNew = new Node(head->val);
cachedNode[head] = headNew;
headNew->next = copyRandomList(head->next);
headNew->random = copyRandomList(head->random);
}
return cachedNode[head];
}
};
复杂度分析
- 时间复杂度:O(n),其中 n 是链表的长度。对于每个节点,我们至多访问其「后继节点」和「随机指针指向的节点」各一次,均摊每个点至多被访问两次。
- 空间复杂度:O(n),其中 n 是链表的长度。为哈希表的空间开销。
方法二:迭代 + 节点拆分
注意到方法一需要使用哈希表记录每一个节点对应新节点的创建情况,而我们可以使用一个小技巧来省去哈希表的空间。
算法流程:
-
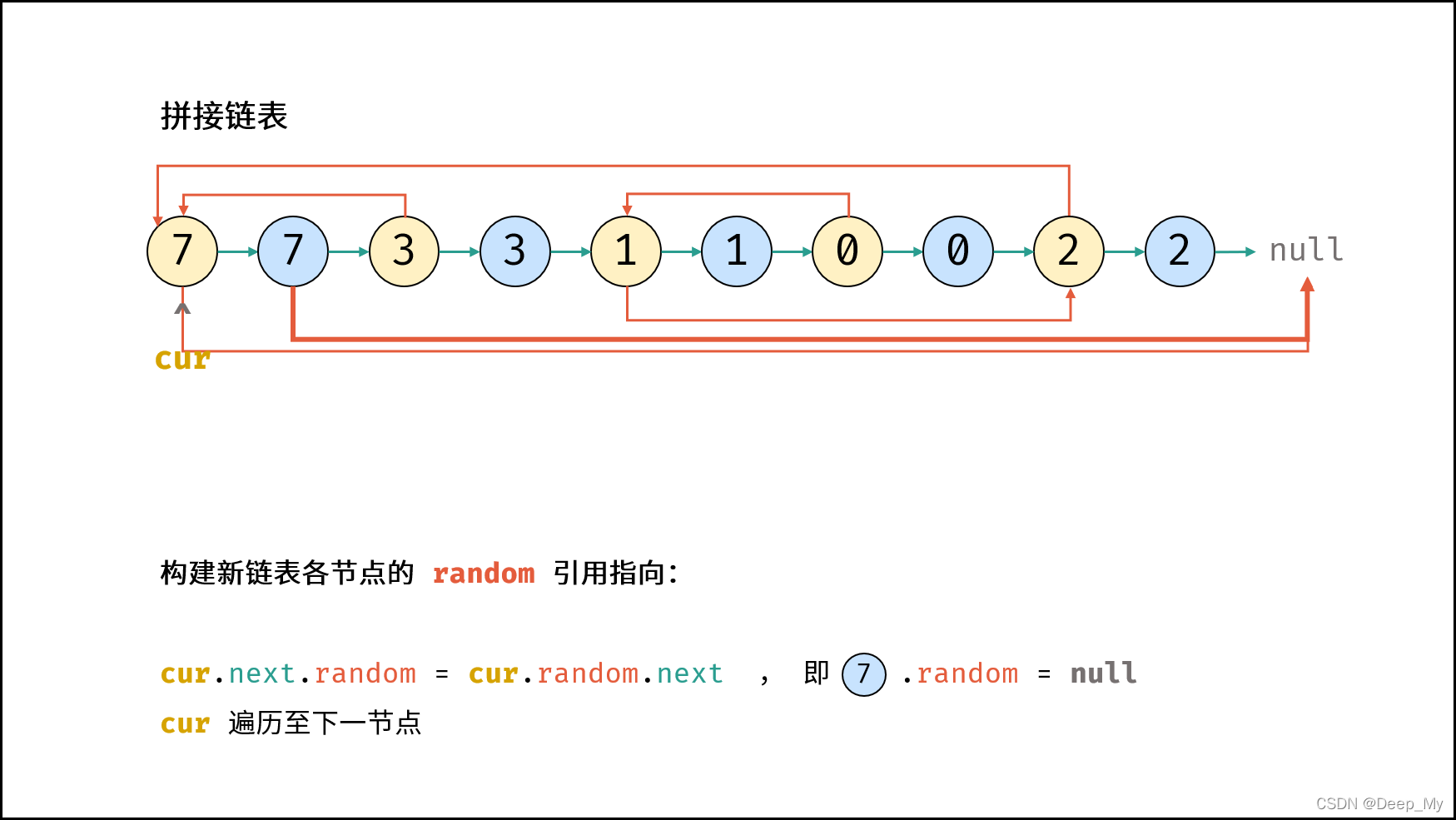
复制各节点,构建拼接链表:
· 设原链表为
no
d
e
1
→
n
o
d
e
2
→
⋯
node1 \rightarrow node2 \rightarrow \cdots
n
o
d
e
1
→
n
o
d
e
2
→
⋯
,构建的拼接链表如下所示:
no
d
e
1
→
n
o
d
e
1
n
e
w
→
n
o
d
e
2
→
n
o
d
e
2
n
e
w
→
⋯
node1 \rightarrow node1_{new} \rightarrow node2 \rightarrow node2_{new} \rightarrow \cdots
n
o
d
e
1
→
n
o
d
e
1
n
e
w
→
n
o
d
e
2
→
n
o
d
e
2
n
e
w
→
⋯
-
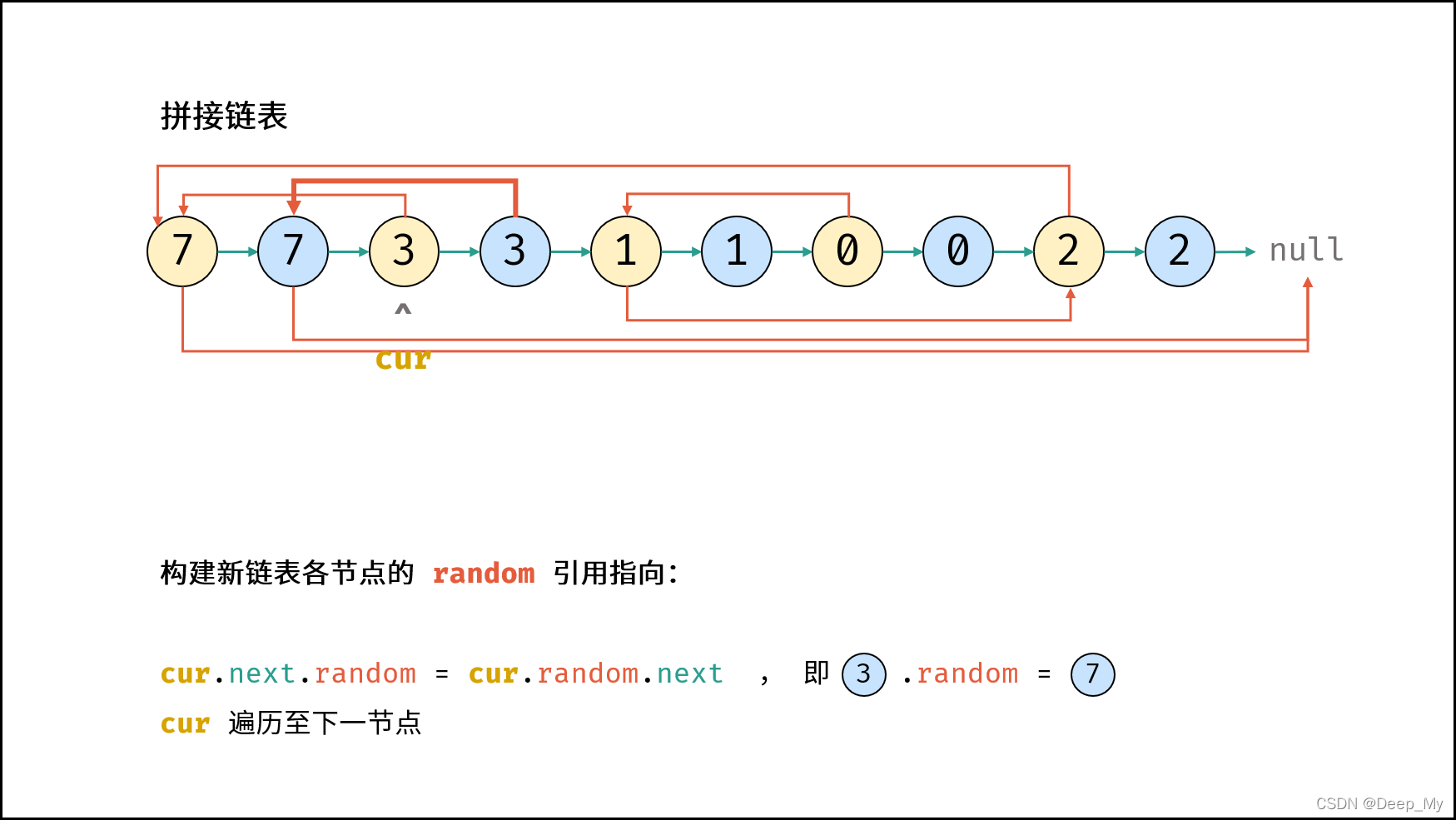
构建新链表各节点的 random 指向:
· 👀当访问原节点
cur
的随机指向节点
cur.random
时,对应新节点
cur.next
的随机指向节点为
cur.random.next
。 -
拆分原 / 新链表:
· 设置
pre / cur
分别指向原 / 新链表头节点,遍历执行
pre.next = pre.next.next
和
cur.next = cur.next.next
将两链表拆分开。 -
返回新链表的头节点
res
即可。
第二步图示👀
class Solution {
public:
Node* copyRandomList(Node* head) {
if(head == nullptr) return nullptr;
Node* cur = head;
// 1. 复制各节点,并构建拼接链表
while(cur != nullptr) {
Node* newNode = new Node(cur->val);
newNode->next = cur->next;
cur->next = newNode;
cur = newNode->next;
}
// 2. 构建各新节点的 random 指向 👀
cur = head;
while(cur != nullptr) {
if(cur->random != nullptr) // random存在才操作 👀
cur->next->random = cur->random->next;
cur = cur->next->next;
}
// 3. 拆分两链表
cur = head->next; // 👀
Node* pre = head, *ans = head->next;//👀
while(cur->next != nullptr) {
pre->next = pre->next->next; //必须先断第一个结点pre,后断第二个结点cur👀
cur->next = cur->next->next;
pre = pre->next;
cur = cur->next;
}
pre->next = nullptr; // 单独处理原链表尾节点👀
return ans; // 返回新链表头节点
}
};
复杂度分析:
- 时间复杂度 O(N) : 三轮遍历链表,使用 O(N) 时间。
- 空间复杂度 O(1) : 节点引用变量使用常数大小的额外空间。
剑指 Offer 05. 替换空格
请实现一个函数,把字符串 s 中的每个空格替换成”%20″。
示例 1:
输入:s = "We are happy."
输出:"We%20are%20happy."
限制:
0 <= s 的长度 <= 10000
我的思路:创建一个新的string,遍历添加
class Solution {
public:
string replaceSpace(string s) {
string ans;
for (int i=0; i<s.size(); ++i)
{
if (s[i]!=' ') ans += s[i];
else ans += "%20";
}
return ans;
}
};
复杂度 O(n), O(n)
方法二:原地修改 (扩容+双指针)
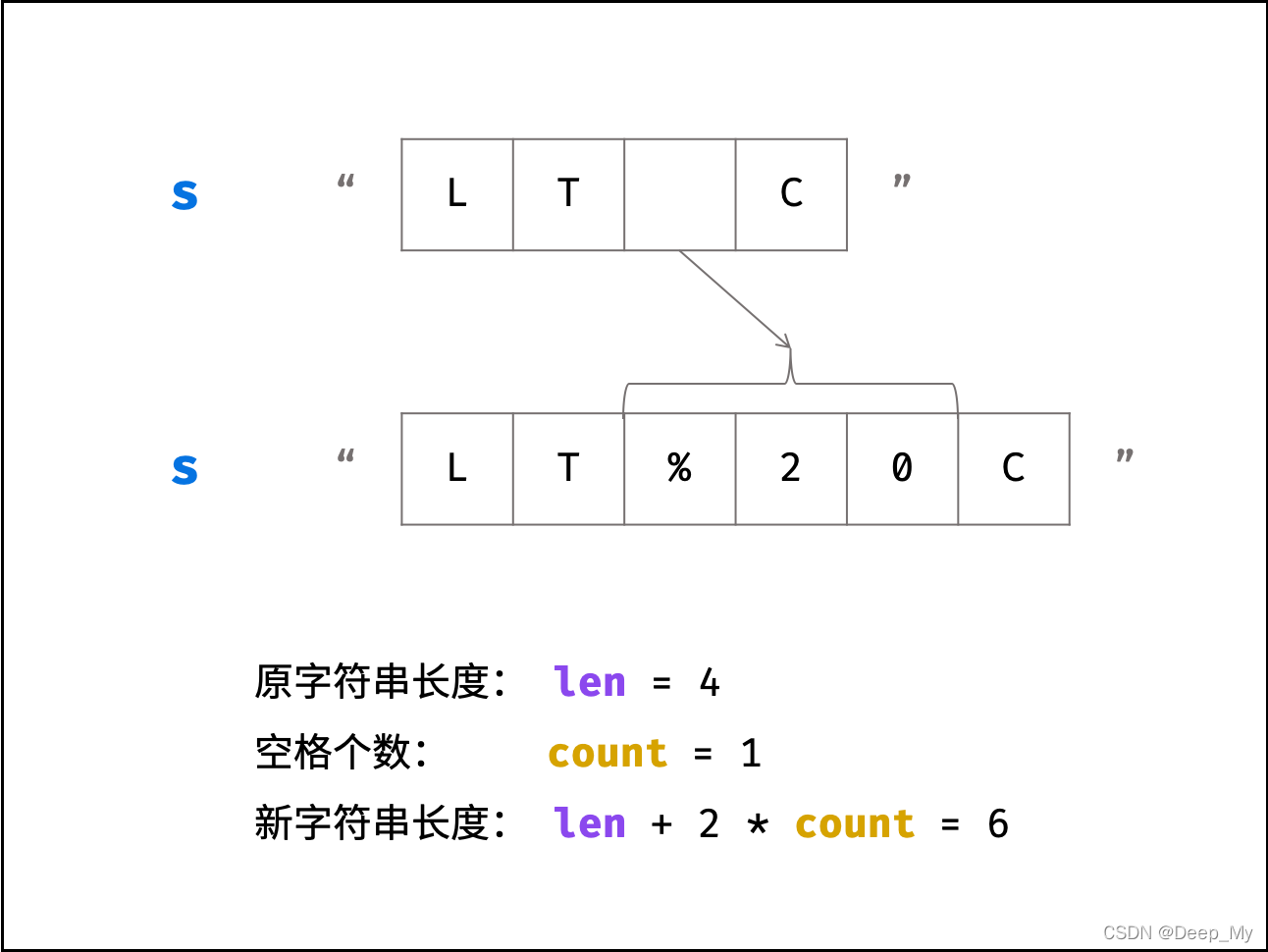
在 C++ 语言中, string 被设计成「可变」的类型(参考资料),因此可以在不新建字符串的情况下实现原地修改。
由于需要将空格替换为 “%20” ,字符串的总字符数增加,因此需要扩展原字符串 s 的长度,计算公式为:
新字符串长度 = 原字符串长度 + 2 * 空格个数
,示例如下图所示。
- 算法流程:
-
初始化:空格数量
count
,字符串 s 的长度
len
; -
统计空格数量:遍历 s ,遇空格则
count++
; -
修改 s 长度:添加完 “%20” 后的字符串长度应为
len + 2 * count
; -
倒序遍历修改
:
i
指向原字符串尾部元素,
j
指向新字符串尾部元素;当 i = j 时跳出(代表左方已没有空格,无需继续遍历);
4.1 当 s[i] 不为空格时:执行 s[j] = s[i] ;
4.2 当 s[i] 为空格时:将字符串闭区间 [j-2, j] 的元素修改为 “%20” ;由于修改了 3 个元素,因此需要 j -= 2 ; - 返回值:已修改的字符串 s ;
class Solution {
public:
string replaceSpace(string s) {
int count = 0, len = s.size();
// 统计空格数量
for (char c : s) {
if (c == ' ') count++;
}
// 修改 s 长度
s.resize(len + 2 * count);
// 倒序遍历修改
for(int i = len - 1, j = s.size() - 1; i < j; i--, j--) {
if (s[i] != ' ')
s[j] = s[i];
else {
s[j - 2] = '%';
s[j - 1] = '2';
s[j] = '0';
j -= 2;
}
}
return s;
}
};
复杂度分析:
时间复杂度 O(N) : 遍历统计、遍历修改皆使用 O(N) 时间。
空间复杂度 O(1) : 由于是原地扩展 s 长度,因此使用 O(1) 额外空间。
剑指 Offer 58 – II. 左旋转字符串
字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。请定义一个函数实现字符串左旋转操作的功能。比如,输入字符串”abcdefg”和数字2,该函数将返回左旋转两位得到的结果”cdefgab”。
示例 1:
输入: s = "abcdefg", k = 2
输出: "cdefgab"
示例 2:
输入: s = "lrloseumgh", k = 6
输出: "umghlrlose"
限制:
1 <= k < s.length <= 10000
我的方法,遍历
class Solution {
public:
string reverseLeftWords(string s, int n) {
string ans;
int len = s.size();
for (int i=0; i<len; ++i)
{
ans+=s[(i+n)%len];
}
return ans;
}
};
方法二:尾部添加,前面删除
class Solution {
public:
string reverseLeftWords(string s, int n) {
for (int i=0; i<n; ++i) s+=s[i];
s.erase(0, n);
return s;
}
};
方法三:截取代码块,切片
class Solution {
public:
string reverseLeftWords(string s, int n) {
s += s.substr(0,n);
return s.substr(n,s.size()-n);
}
};
方法四:三次翻转
此方法空间复杂度最低
class Solution {
public:
void reverse_string(string& s, int start, int end) {
for (int i = start; i <= (start + end) / 2; i++) {
char temp = s[i];
s[i] = s[start+end-i];
s[start+end-i] = temp;
}
return ;
}
string reverseLeftWords(string s, int n) {
int len = s.length();
reverse_string(s, 0, len-1); // 整体翻转
reverse_string(s, 0, len-n-1);// 前部翻转
reverse_string(s, len-n, len-1);// 后翻转
return s;
}
};
查找算法
剑指 Offer 03. 数组中重复的数字
找出数组中重复的数字。
在一个长度为 n 的数组 nums 里的所有数字都在 0~n-1 的范围内。数组中某些数字是重复的,但不知道有几个数字重复了,也不知道每个数字重复了几次。请找出数组中任意一个重复的数字。
示例 1:
输入:
[2, 3, 1, 0, 2, 5, 3]
输出:2 或 3
限制:
2 <= n <= 100000
我的方法:哈希表
class Solution {
public:
int findRepeatNumber(vector<int>& nums) {
unordered_map<int, int> m;
for (auto &i: nums)
{
++m[i];
if (m[i] > 1) return i;
}
return 0;
}
};
复杂度:O(N), O(N)
方法二:判断环
注意题目: 数组
nums
里的所有数字都在
0~n-1
的范围内
故可以将数组 按值 跟换 位置,如果出现相同值,则同一位置会出现多次赋值
class Solution {
public:
int findRepeatNumber(vector<int>& nums) {
for (int i = 0; i < nums.size(); i++) {
// 在正确位置跳过
if (i == nums[i]) {
continue;
}
// 不在正确位置交换,如果要交换的地方也是这个数字就找到了
if (nums[i] == nums[nums[i]]) {
return nums[i];
} else {
int tmp = nums[i];
nums[i] = nums[nums[i]];
nums[tmp] = tmp; // nums[i]变了,这里要用tmp👀
}
}
return nums[0];
}
};
复杂度:O(N), O(1)
剑指 Offer 53 – I. 在排序数组中查找数字 I
统计一个数字在排序数组中出现的次数。
示例 1:
输入: nums = [5,7,7,8,8,10], target = 8
输出: 2
示例 2:
输入: nums = [5,7,7,8,8,10], target = 6
输出: 0
提示:
0 <= nums.length <= 105
-109 <= nums[i] <= 109
nums 是一个非递减数组
-109 <= target <= 109
我的思路:闭区间二分查找
当二分法找到时,从左右两侧进行遍历查找,注意越界问题。
class Solution {
public:
int search(vector<int>& nums, int target) {
int left=0, right=nums.size()-1;
int count=0;
while (left <= right)
{
int mid = left + (right - left) / 2;
if (target == nums[mid]) // 👀
{
left = mid;
while (left >= 0 && nums[left] == target) // 越界问题
{
++count;
--left;
}
right = mid + 1;
while (right <= nums.size() - 1 && nums[right] == target)// 越界问题
{
++count;
++right;
}
return count;
}else if (target > nums[mid])
{
left = mid+1;
}else if (target < nums[mid])
{
right = mid-1;
}
}
return count;
}
};
复杂度: O(n) 数组数全都一样, O(1)
方法二:两次二分查找
两次二分查找x,一次找到x元素最左边位置,一次找到x元素最右边的位置,最终返回的是
右边的位置-左边的位置 + 1
。当数组大小为零时候特殊处理,返回0。
class Solution {
public:
int l_search(vector<int>& nums, int target)
{
int left = 0, right = nums.size();
while (left < right)
{
int mid = left + (right - left) / 2;
if (nums[mid] == target) right = mid;
else if (nums[mid] > target)
{
right = mid;
}
else if (nums[mid] < target)
{
left = mid + 1;
}
}
return left;
}
int r_search(vector<int>& nums, int target)
{
int left = 0, right = nums.size();
while (left < right)
{
int mid = left + (right - left) / 2;
if (nums[mid] == target) left = mid + 1;
else if (nums[mid] > target)
{
right = mid;
}
else if (nums[mid] < target)
{
left = mid + 1;
}
}
return right - 1;
}
int search(vector<int>& nums, int target) {
if (nums.size()==0) return 0;
int left= l_search(nums, target), right=r_search(nums, target);
return right-left+1;
}
};
复杂度:O(logn), O(1)
-
nums[4],nums[ target], nums[5]。 此时mid=4
target找不到的时候,l_search返回的是left=mid+1=5; r_search返回的是left-1=mid+1-1=4
最终结果返回 4-5+1=0 -
注意,此处l_search与r_search的返回值不能改为-1,即如下:
因为当target找不到的时候,返回的都是-1,
最终结果返回-1-(-1)+1=1,则不正确
int l_search(vector<int>& nums, int target)
{
int left = 0, right = nums.size();
while (left < right)
{
...
}
if (left == nums.size()) return -1; // 越界
return nums[left]==target ? left : -1;
}
int r_search(vector<int>& nums, int target)
{
int left = 0, right = nums.size();
while (left < right)
{
...
}
if (left-1==-1) return -1; //越界
return nums[left - 1]==target? left - 1: -1;
}
剑指 Offer 53 – II. 0~n-1中缺失的数字
一个长度为n-1的递增排序数组中的所有数字都是唯一的,并且每个数字都在范围0~n-1之内。在范围0~n-1内的n个数字中有且只有一个数字不在该数组中,请找出这个数字。
示例 1:
输入: [0,1,3]
输出: 2
示例 2:
输入: [0,1,2,3,4,5,6,7,9]
输出: 8
我的思路:右边界 二分法
当找到
nums[mid] == mid
的结点时,提升下界(left)
注意 我们返回的是
left
而不是
left+1
,因为我们要找的是第一个
不同的数
class Solution {
public:
int missingNumber(vector<int>& nums) {
int left = 0, right = nums.size();
while (left < right)
{
int mid = left + (right - left) / 2;
if (nums[mid] == mid) left = mid + 1;
else if (nums[mid] > mid)
{
right = mid;
}
}
return left;
}
};
复杂度:O(logn), O(1)
剑指 Offer 04. 二维数组中的查找
在一个 n * m 的二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个高效的函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。
示例:
现有矩阵 matrix 如下:
[
[1, 4, 7, 11, 15],
[2, 5, 8, 12, 19],
[3, 6, 9, 16, 22],
[10, 13, 14, 17, 24],
[18, 21, 23, 26, 30]
]
给定 target = 5,返回 true。
给定 target = 20,返回 false。
限制:
0 <= n <= 1000
0 <= m <= 1000
我的方法:遍历+左边界 二分
bool findNumberIn2DArray(vector<vector<int>>& matrix, int target) {
int n=matrix.size();
for (int i=0; i<n; ++i)
{
int row_l=0, row_r=matrix[i].size();
while(row_l<row_r) // left search
{
int row_m = row_l+(row_r-row_l)/2;
if (matrix[i][row_m]==target) return true;
else if(matrix[i][row_m]>target)
{
row_r = row_m;
}else if(matrix[i][row_m]<target)
{
row_l = row_m+1;
}
}
}
return false;
}
复杂度: O(nlogm), O(1)
方法二:线性查找
由于给定的二维数组具备每行从左到右递增以及每列从上到下递增的特点,当访问到一个元素时,可以排除数组中的部分元素。
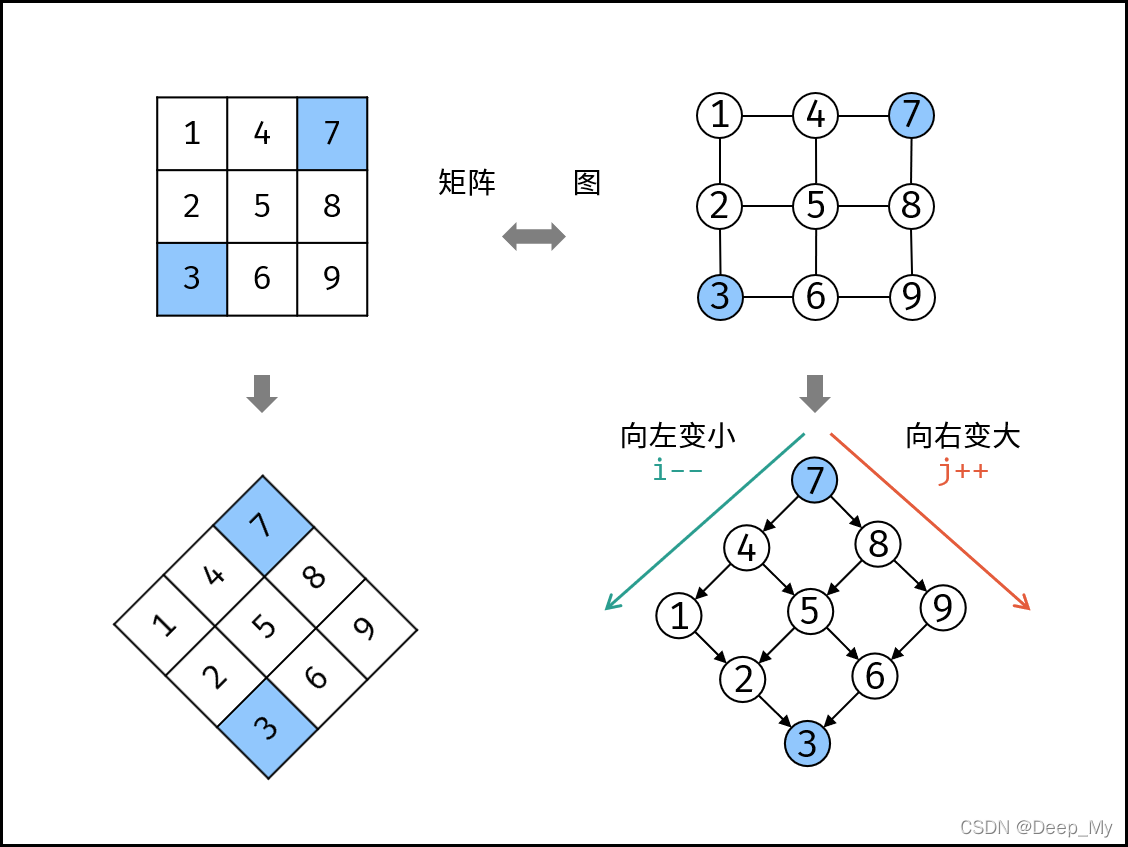
从二维数组的右上角开始查找。如果当前元素等于目标值,则返回 true。如果当前元素大于目标值,则移到左边一列。如果当前元素小于目标值,则移到下边一行。
如下图所示,我们将矩阵逆时针旋转 45° ,并将其转化为图形式,发现其类似于 二叉搜索树 ,即对于每个元素,其左分支元素更小、右分支元素更大。因此,通过从 “根节点” 开始搜索,遇到比 target 大的元素就向左,反之向右,即可找到目标值 target 。

class Solution {
public:
bool findNumberIn2DArray(vector<vector<int>>& matrix, int target) {
if (matrix.size()==0) return false;
int col=matrix.size()-1, row=matrix[0].size()-1;
int i=0, j=row;
while (i<=col && j>=0)
{
if (matrix[i][j]==target) return true;
else if (matrix[i][j]>target) --j;
else if (matrix[i][j]<target) ++i;
}
return false;
}
};
复杂度分析:
- 时间复杂度 O(M+N):其中,N 和 M 分别为矩阵行数和列数,此算法最多循环 M+N 次。
- 空间复杂度 O(1): i, j 指针使用常数大小额外空间。
剑指 Offer 11. 旋转数组的最小数字
把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。
给你一个可能存在 重复 元素值的数组 numbers ,它原来是一个升序排列的数组,并按上述情形进行了一次旋转。请返回旋转数组的最小元素。例如,数组 [3,4,5,1,2] 为 [1,2,3,4,5] 的一次旋转,该数组的最小值为1。
示例 1:
输入:[3,4,5,1,2]
输出:1
示例 2:
输入:[2,2,2,0,1]
输出:0
官解:二分法
一个包含重复元素的升序数组在经过旋转之后,可以得到下面可视化的折线图:
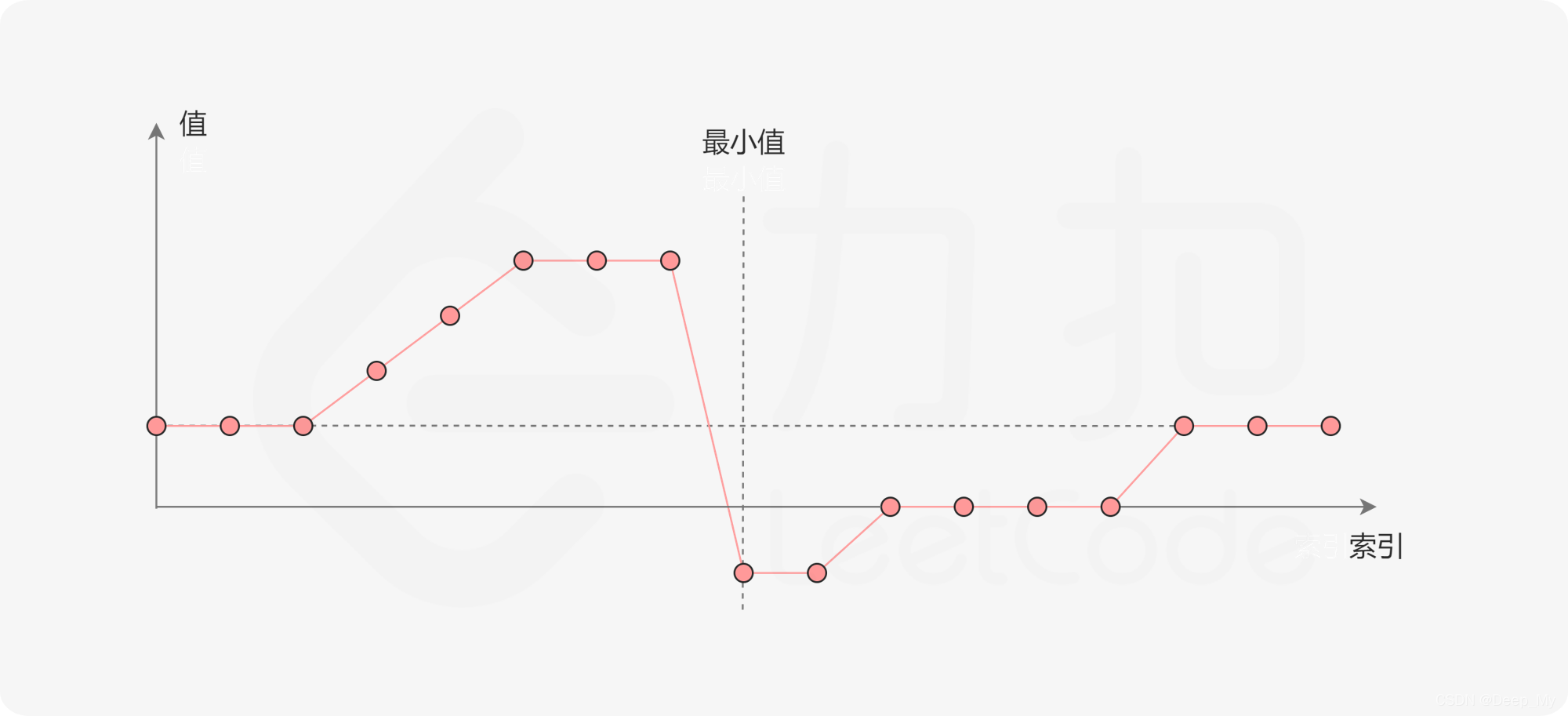
其中横轴表示数组元素的下标,纵轴表示数组元素的值。图中标出了最小值的位置,是我们需要查找的目标。
我们
考虑数组中的最后一个元素
x=nums[-1]
:在最小值右侧的元素,它们的值一定都小于等于
x
;而在最小值左侧的元素,它们的值一定都大于等于
x
。因此,我们可以根据这一条性质,通过二分查找的方法找出最小值。
在二分查找的每一步中,左边界为
l
o
w
\it low
low
,右边界为
h
i
g
h
\it high
high
,区间的中点为
p
i
v
o
t
\it pivot
pivot
,最小值就在该区间内。我们将中轴元素
numbers
[
pivot
]
\textit{numbers}[\textit{pivot}]
numbers
[
pivot
]
与右边界元素
numbers
[
high
]
\textit{numbers}[\textit{high}]
numbers
[
high
]
进行比较,可能会有以下的三种情况:
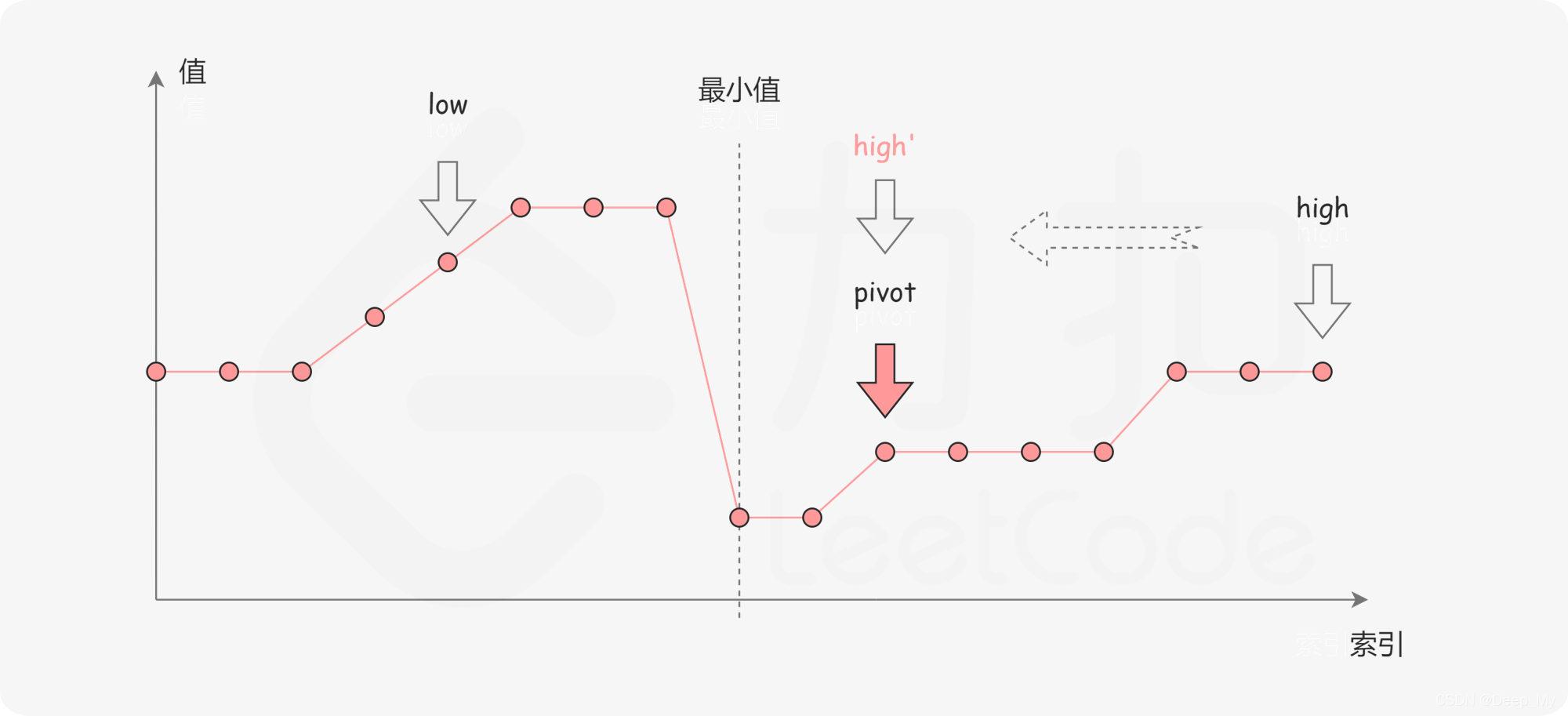
-
第一种情况是
numbers[
pivot
]
<
numbers
[
high
]
\textit{numbers}[\textit{pivot}] < \textit{numbers}[\textit{high}]
numbers
[
pivot
]
<
numbers
[
high
]
。如下图所示,这说明
numbers[
pivot
]
\textit{numbers}[\textit{pivot}]
numbers
[
pivot
]
是最小值右侧的元素,因此我们可以忽略二分查找区间的右半部分。
-
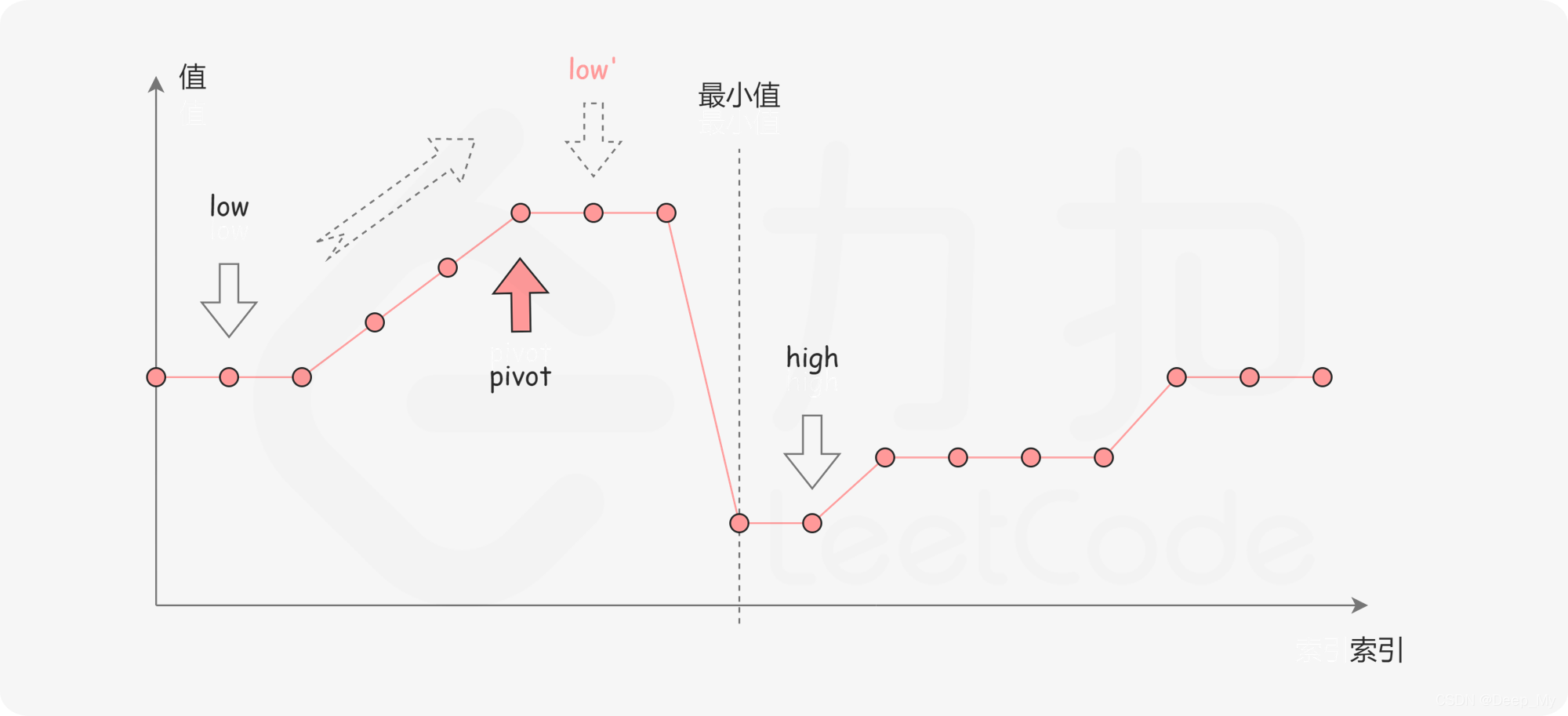
第二种情况是
numbers[
pivot
]
>
numbers
[
high
]
\textit{numbers}[\textit{pivot}] > \textit{numbers}[\textit{high}]
numbers
[
pivot
]
>
numbers
[
high
]
。如下图所示,这说明
numbers[
pivot
]
\textit{numbers}[\textit{pivot}]
numbers
[
pivot
]
是最小值左侧的元素,因此我们可以忽略二分查找区间的左半部分。
-
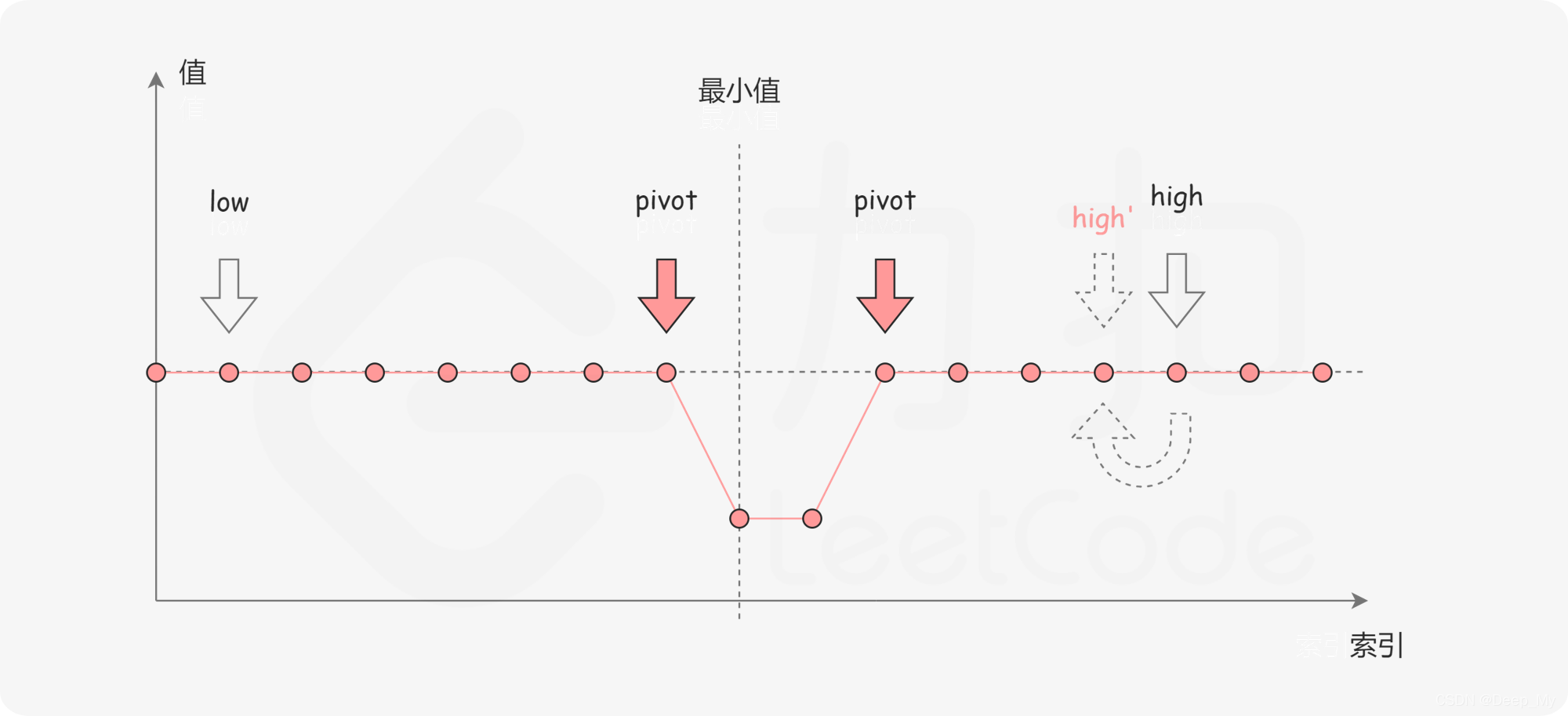
第三种情况是
numbers[
pivot
]
=
=
numbers
[
high
]
\textit{numbers}[\textit{pivot}] == \textit{numbers}[\textit{high}]
numbers
[
pivot
]
==
numbers
[
high
]
。如下图所示,由于重复元素的存在,我们并不能确定
numbers[
pivot
]
\textit{numbers}[\textit{pivot}]
numbers
[
pivot
]
究竟在最小值的左侧还是右侧,因此我们不能莽撞地忽略某一部分的元素。我们唯一可以知道的是,由于它们的值相同,所以无论
numbers[
high
]
\textit{numbers}[\textit{high}]
numbers
[
high
]
是不是最小值,都有一个它的「替代品」
numbers[
pivot
]
\textit{numbers}[\textit{pivot}]
numbers
[
pivot
]
,因此我们可以忽略二分查找区间的右端点。
class Solution {
public:
int minArray(vector<int>& numbers) {
int low = 0;
int high = numbers.size() - 1;
while (low < high) {
int pivot = low + (high - low) / 2;
if (numbers[pivot] < numbers[high]) {
high = pivot;
}
else if (numbers[pivot] > numbers[high]) {
low = pivot + 1;
}
else {
high -= 1;
}
}
return numbers[low];
}
};
复杂度分析
时间复杂度:平均时间复杂度为
O
(
log
n
)
O(\log n)
O
(
lo
g
n
)
,其中 n 是数组
n
u
m
b
e
r
s
\it numbers
numbers
的长度。如果数组是随机生成的,那么数组中包含相同元素的概率很低,在二分查找的过程中,大部分情况都会忽略一半的区间。而在最坏情况下,如果数组中的元素完全相同,那么
while
\texttt{while}
while
循环就需要执行
n
n
n
次,每次忽略区间的右端点,时间复杂度为
O
(
n
)
O(n)
O
(
n
)
。
空间复杂度:O(1)。
回溯与搜索
剑指 Offer 27. 二叉树的镜像
请完成一个函数,输入一个二叉树,该函数输出它的镜像。
例如输入:
4
/ \
2 7
/ \ / \
1 3 6 9
镜像输出:
4
/ \
7 2
/ \ / \
9 6 3 1
示例 1:
输入:root = [4,2,7,1,3,6,9]
输出:[4,7,2,9,6,3,1]
限制:
0 <= 节点个数 <= 1000
我的思路:递归
class Solution {
public:
void reverse(TreeNode* A)
{
TreeNode* tmp = A->left;
A->left = A->right;
A->right = tmp;
if (A->left) reverse(A->left);
if (A->right) reverse(A->right);
}
TreeNode* mirrorTree(TreeNode* root) {
if (!root) return root;
reverse(root);
return root;
}
};
复杂度:O(n), O(n)
(同手同脚)剑指 Offer 26. 树的子结构
输入两棵二叉树A和B,判断B是不是A的子结构。(约定空树不是任意一个树的子结构)
B是A的子结构, 即 A中有出现和B相同的结构和节点值。
例如:
给定的树 A:
3
/ \
4 5
/ \
1 2
给定的树 B:
4
/
1
返回 true,因为 B 与 A 的一个子树拥有相同的结构和节点值。
示例 1:
输入:A = [1,2,3], B = [3,1]
输出:false
示例 2:
输入:A = [3,4,5,1,2], B = [4,1]
输出:true
限制:
0 <= 节点个数 <= 10000
我的思路:DFS,同手同脚
dfs函数遍历树,如果遇到与目标树根节点相同的值,
则进入search递归函数:同手同脚移动 a树,b树
class Solution:
def isSubStructure(self, A: TreeNode, B: TreeNode) -> bool:
if not A or not B: return False
def search(a: TreeNode, b: TreeNode)-> bool:
if not a and not b: return True
elif not a: return False
elif not b: return True
if a.val!=b.val: return False
return search(a.left, b.left) and search(a.right, b.right)
def dfs(root: TreeNode, target: TreeNode)->bool:
if not root: return False
flag = False
if root.val == target.val:
flag = search(root, target)
return flag or dfs(root.left, target) or dfs(root.right, target) #👀同手同脚
return dfs(A, B)
我的思路2:dfs遍历,stack
先遍历A树,当找到
node->val == B->val
的结点时,进入
helper函数
判断是否子树。注意helper不能直接return,而是返回一个flag,当遍历完A树都未找到符合条件的子树时,
return false(flag默认值)
当flag为true时,直接return,减低复杂度
class Solution {
public:
bool dfs(TreeNode* A, TreeNode* B)
{
if (!A || !B) return false;
stack<TreeNode*> stk;
TreeNode* node = A;
bool flag = false;
stk.push(node);
while (node || !stk.empty())
{
while (node)
{
if (node->val==B->val) flag = flag || helper(node, B); //👀
if (flag) return flag; // 👀 当发现flag为true时,直接return。降低复杂度的关键
stk.push(node);
node = node->left;
}
node = stk.top(); stk.pop();
node = node->right;
}
return flag;
}
bool helper(TreeNode* A, TreeNode* B) // 👀
{
bool flag = true;
if (!A) return false; // 进入helper的条件是B存在,若A不存在,则直接return false
if (A->val!=B->val) return false; //当前结点val不相等,直接return false
if (B->left) flag = flag && helper(A->left, B->left); // 需要继续判断right
if (B->right) flag = flag && helper(A->right, B->right);
return flag;
}
bool isSubStructure(TreeNode* A, TreeNode* B) {
return dfs(A, B);
}
};
复杂度:O(n), O(n)
(手脚交替)剑指 Offer 28. 对称的二叉树
请实现一个函数,用来判断一棵二叉树是不是对称的。如果一棵二叉树和它的镜像一样,那么它是对称的。
例如,二叉树 [1,2,2,3,4,4,3] 是对称的。
1
/ \
2 2
/ \ / \
3 4 4 3
但是下面这个 [1,2,2,null,3,null,3] 则不是镜像对称的:
1
/ \
2 2
\ \
3 3
示例 1:
输入:root = [1,2,2,3,4,4,3]
输出:true
示例 2:
输入:root = [1,2,2,null,3,null,3]
输出:false
限制:
0 <= 节点个数 <= 1000
我的思路:DFS,手脚交替法
search 函数:手脚交替法搜索
class Solution:
def isSymmetric(self, root: TreeNode) -> bool:
if not root: return True
def search(r: TreeNode, l: TreeNode):
if not r and not l: return True
elif not r: return False
elif not l: return False
if r.val!=l.val:
return False
return dfs(r.right, l.left) and dfs(r.left, l.right) # 👀手脚交替
return dfs(root.right, root.left)
我的思路:递归
class Solution {
public:
bool equal(TreeNode* p, TreeNode* q)
{
bool flag = true;
if (!p && !q) return true;
if ((!p && q) || (p && !q)) return false;
if (p->val!=q->val) return false;
if (p->left || q->right) flag = flag && equal(p->left, q->right);
if (p->right || q->left) flag = flag && equal(p->right, q->left);
return flag;
}
bool isSymmetric(TreeNode* root) {
if (!root) return true;
return equal(root->left, root->right);
}
};
复杂度:O(n), O(n)
动态规划
剑指 Offer 10- II. 青蛙跳台阶问题
一只青蛙一次可以跳上1级台阶,也可以跳上2级台阶。求该青蛙跳上一个 n 级的台阶总共有多少种跳法。
答案需要取模 1e9+7(1000000007),如计算初始结果为:1000000008,请返回 1。
示例 1:
输入:n = 2
输出:2
示例 2:
输入:n = 7
输出:21
示例 3:
输入:n = 0
输出:1
提示:
0 <= n <= 100
我的方法:带备忘录的递归
直接看不明确,我们用递归法。
明确dfs返回的是什么:可跳跃的次数
class Solution {
public:
// int dfs(int n, int& count, vector<int> & memo, int MOD)
// {
// if (n<=1) return 1;
// if (memo[n]!=0) return memo[n];
// int tmp = count%MOD;
// memo[n] = (dfs(n-1, tmp, memo, MOD)+dfs(n-2, tmp, memo, MOD))%MOD;
// return count%MOD;
// }
// int numWays(int n) {
// if (n<2) return 1;
// int MOD = 1000000007;
// vector<int> memo(n+1, 0);
// memo[0] = 1; memo[1] = 1;memo[2] = 2;
// int count=1;
// return dfs(n, count, memo, MOD);
// }
// 优化后如下
int dfs(int n, vector<int> & memo, int MOD)
{
if (memo[n]!=0) return memo[n];
memo[n] = (dfs(n-1, memo, MOD)+dfs(n-2, memo, MOD))%MOD; // 👀
return memo[n];
}
int numWays(int n) {
int MOD = 1000000007;
vector<int> memo(n+1, 0);
memo[0] = 1; memo[1] = 1;memo[2] = 2;
return dfs(n, memo, MOD);
}
};
此时,注意👀处,动态转移方程已经出来了;故可明确,本题类似于 斐波那契数列
故方程可改为从下往上的动态规划方法
class Solution {
public:
int numWays(int n) {
if (n<2) return 1;
int MOD = 1000000007;
int df0=0, df1=1, df2=1;
for (int i=2; i<=n; ++i)
{
df0 = df1;
df1 = df2;
df2 = (df1 + df0)%MOD;
}
return df2;
}
};
剑指 Offer 47. 礼物的最大价值 (二维动态规划)
在一个 m*n 的棋盘的每一格都放有一个礼物,每个礼物都有一定的价值(价值大于 0)。你可以从棋盘的左上角开始拿格子里的礼物,并每次向右或者向下移动一格、直到到达棋盘的右下角。给定一个棋盘及其上面的礼物的价值,请计算你最多能拿到多少价值的礼物?
示例 1:
输入:
[
[1,3,1],
[1,5,1],
[4,2,1]
]
输出: 12
解释: 路径 1→3→5→2→1 可以拿到最多价值的礼物
提示:
0 < grid.length <= 200
0 < grid[0].length <= 200
首先定义一个二维的 dp 数组,其中
dp[i][j]
表示从左上角开始到
(i, j)
位置的最优路径的数字和。因为每次只能向下或者向右移动,我们可以很容易得到状态转移方程
d
p
[
i
]
[
j
]
=
m
i
n
(
d
p
[
i
+
1
]
[
j
]
,
d
p
[
i
]
[
j
+
1
]
)
+
g
r
i
d
[
i
]
[
j
]
dp[i][j]= min(dp[i+1][j], dp[i][j+1])+ grid[i][j]
d
p
[
i
]
[
j
]
=
min
(
d
p
[
i
+
1
]
[
j
]
,
d
p
[
i
]
[
j
+
1
])
+
g
r
i
d
[
i
]
[
j
]
其中 grid 表示原数组。
class Solution {
public:
int maxValue(vector<vector<int>>& grid) {
int m=grid.size(), n=grid[0].size();
vector<vector<int>>dp(m+1, vector<int>(n+1));
dp[0][0]=grid[0][0];
for(int i=1; i<m; ++i) dp[i][0]=grid[i][0]+dp[i-1][0]; //竖列
for(int i=1; i<n; ++i) dp[0][i]=grid[0][i]+dp[0][i-1]; //横列
for(int i=1; i<m; ++i)
{
for(int j=1; j<n; ++j)
{
dp[i][j]= max(dp[i-1][j], dp[i][j-1])+ grid[i][j];
}
}
return dp[m-1][n-1];
}
};
复杂度:O(MN), O(MN)
剑指 Offer 46. 把数字翻译成字符串
给定一个数字,我们按照如下规则把它翻译为字符串:0 翻译成 “a” ,1 翻译成 “b”,……,11 翻译成 “l”,……,25 翻译成 “z”。一个数字可能有多个翻译。请编程实现一个函数,用来计算一个数字有多少种不同的翻译方法。
示例 1:
输入: 12258
输出: 5
解释: 12258有5种不同的翻译,分别是"bccfi", "bwfi", "bczi", "mcfi"和"mzi"
提示:
0 <= num < 231
我的思路:将数字切分为不同的斐波那契块
当num仅由
”1“
”2“
组成时,该题目等价于计算斐波那契数列(fb块)
例如
num=1212112
,则
return f(7)
故此,我们可将num拆分成不同的fb块
最后返回所有fb块的乘积
class Solution {
public:
int fb(int n)
{
if (n<=2) return n;
int dp0=0, dp1=1, dp2=2;
for (int i=3; i<=n; ++i)
{
dp0 = dp1;
dp1 = dp2;
dp2 = dp0+dp1;
}
return dp2;
}
int translateNum(int num) {
int len=num;
vector<int> v;
while(len!=0) // 将num按位存入vector中
{
v.push_back(len%10);
len = len/10;
}
reverse(v.begin(), v.end());
int count=0, res=1;
for (int i=0; i<v.size(); ++i)
{
if (v[i]==1 || v[i]==2)
{
++count; // 块长度加1
if (i==v.size()-1)
{
res = fb(count)*res;
count = 0;
}
continue; // 判断下一个
}else if (v[i]<=5) // 判断是否为fb块的尾部,当前vi={0, 3, 4, 5}
{
if (i>0&&(v[i-1]==1 || v[i-1]==2)) // v[i-1]非末尾,当前vi={0, 3, 4, 5},判断为末位
{
++count;
res = fb(count)*res;
count = 0;
}
continue;
}
/*以下均为vi>5的情况*/
if (i>0&&(v[i-1]==1)) // v[i-1]=1非末尾,判断为末位
{
++count;
res = fb(count)*res;
count = 0;
continue;
}
if (count!=0) //当v[i-1]!=1时,同时还存有count未清理,判断为末位,不加1,计算fb
{
res = fb(count)*res;
count = 0;
}
}
return res;
}
};
复杂度:最糟糕的情况O(n), O(n)
方法一:动态规划
首先我们来通过一个例子理解一下这里「翻译」的过程:我们来尝试翻译「14021402」。
分成两种情况:
-
首先我们可以把每一位单独翻译,即
[1, 4, 0, 2]
,翻译的结果是 beac -
然后我们考虑组合某些连续的两位:
[14, 0, 2]
,翻译的结果是 oac。
[1, 40, 2]
,这种情况是不合法的,因为 4040 不能翻译成任何字母。
[1, 4, 02]
,这种情况也是不合法的,含有前导零的两位数不在题目规定的翻译规则中,那么
[14, 02]
显然也是不合法的。
那么我们可以归纳出翻译的规则,字符串的第 i 位置:
- 可以单独作为一位来翻译
-
如果第
i−1
位和第
i
位组成的数字在
10
到
25
之间,可以把这两位连起来翻译
到这里,我们发现它和「198. 打家劫舍」非常相似。我们可以用
f(i)
表示以第
i
位结尾的前缀串翻译的方案数,考虑第
i
位单独翻译和与前一位连接起来再翻译对
f(i)
的贡献。单独翻译对
f(i)
的贡献为
f(i - 1)
;如果第
i - 1
位存在,并且第
i - 1
位和第
i
位形成的数字
x
满足
10
≤
x
≤
25
10 \leq x \leq 25
10
≤
x
≤
25
,那么就可以把第
i - 1
位和第
i
位连起来一起翻译,对
f(i)
的贡献为
f(i - 2)
,否则为
0
。我们可以列出这样的动态规划转移方程:
{
f
(
i
)
=
f
(
i
−
1
)
+
f
(
i
−
2
)
,
i
−
1
≥
0
&
&
10
≤
x
≤
25
f
(
n
−
1
)
+
f
(
n
−
2
)
,
o
t
h
e
r
\begin{cases} f(i) = f(i – 1) + f(i – 2), i – 1 \geq 0\ \&\&\ 10 \leq x \leq 25 \\ f(n – 1) + f(n – 2), other \end{cases}
{
f
(
i
)
=
f
(
i
−
1
)
+
f
(
i
−
2
)
,
i
−
1
≥
0
&&
10
≤
x
≤
25
f
(
n
−
1
)
+
f
(
n
−
2
)
,
o
t
h
er
f
(
i
)
=
f
(
i
−
1
)
+
f
(
i
−
2
)
[
i
−
1
≥
0
,
10
≤
x
≤
25
]
f(i) = f(i – 1) + f(i – 2)[i – 1 \geq 0, 10 \leq x \leq 25]
f
(
i
)
=
f
(
i
−
1
)
+
f
(
i
−
2
)
[
i
−
1
≥
0
,
10
≤
x
≤
25
]
边界条件是
f(-1) = 0
,
f(0) = 1
。方程中
[c]
的意思是
c 为真的时候 [c] = 1 ,否则 [c] = 0
。
有了这个方程我们不难给出一个时间复杂度为 O(n),空间复杂度为 O(n) 的实现。考虑优化空间复杂度:这里的 f(i) 只和它的前两项 f(i – 1) 和 f(i−2) 相关,我们可以运用「滚动数组」思想把 f 数组压缩成三个变量,这样空间复杂度就变成了 O(1)。
class Solution {
public:
int translateNum(int num) {
string src = to_string(num);
int p = 0, q = 0, r = 1;
for (int i = 0; i < src.size(); ++i) {
p = q;
q = r;
r = 0;
r += q;
if (i == 0) {
continue;
}
auto pre = src.substr(i - 1, 2);
if (pre <= "25" && pre >= "10") {
r += p;
}
}
return r;
}
};
复杂度分析
记
n
u
m
=
n
{\rm num} = n
num
=
n
。
时间复杂度:循环的次数是 n 的位数,故渐进时间复杂度为
O
(
log
n
)
O(\log n)
O
(
lo
g
n
)
。
空间复杂度:虽然这里用了滚动数组,动态规划部分的空间代价是 O(1) 的,但是这里用了一个临时变量把数字转化成了字符串,故渐进空间复杂度也是
O
(
log
n
)
O(\log n)
O
(
lo
g
n
)
。
方法三:直接用num做
class Solution {
public:
int translateNum(int num) {
if (num == 0) return 1;
return f(num);
}
int f(int num) {
if (num < 10) {
return 1;
}
if (num % 100 < 26 && num % 100 > 9) { // 10≤x≤25
return f(num / 10) + f(num / 100);
} else { // num % 100 < 10 or num % 100 > 25
return f(num / 10);
}
}
};
双指针
剑指 Offer 52. 两个链表的第一个公共节点
输入两个链表,找出它们的第一个公共节点。
如下面的两个链表:
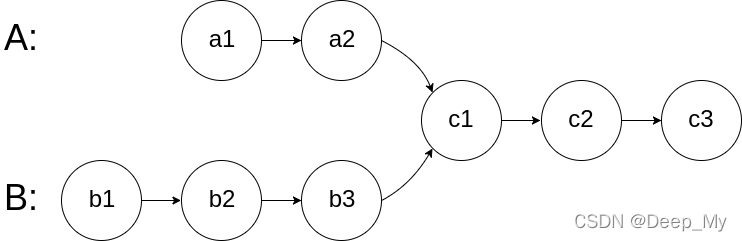
在节点 c1 开始相交。
示例 1:
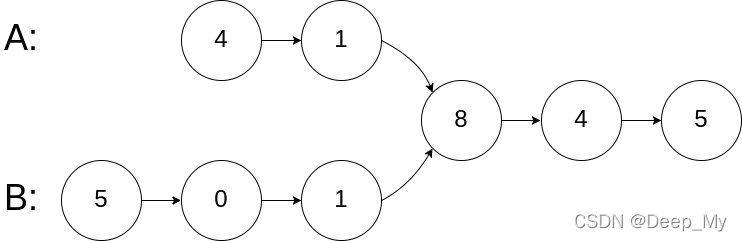
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3
输出:Reference of the node with value = 8
输入解释:相交节点的值为 8 (注意,如果两个列表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
示例 3:
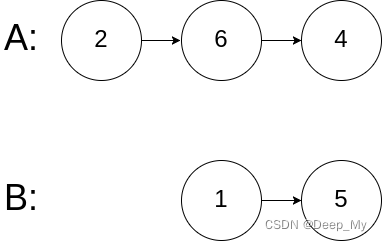
输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
输出:null
输入解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
解释:这两个链表不相交,因此返回 null。
注意:
如果两个链表没有交点,返回 null.
在返回结果后,两个链表仍须保持原有的结构。
可假定整个链表结构中没有循环。
程序尽量满足 O(n) 时间复杂度,且仅用 O(1) 内存。
我的解法:双指针
将两个指针分别指向A,B的头节点,同步移动,
得到A与B的长度差length;
然后再将长的链表前进length步,得到相同长度的l1,l2
class Solution {
public:
int get_len(ListNode* l1, ListNode* l2)
{
int length = 0;
while (l1 && l2)
{
l1 = l1->next;
l2 = l2->next;
}
while (l1)
{
l1 = l1->next;
++length;
}
while (l2)
{
l2 = l2->next;
--length;
}
return length;
}
ListNode* getIntersectionNode(ListNode* headA, ListNode* headB) {
ListNode* l1 = headA, * l2 = headB;
int length = get_len(l1, l2);
while (length > 0)
{
l1 = l1->next;
--length;
}
while (length < 0)
{
l2 = l2->next;
++length;
}
while (l1)
{
if (l1==l2) return l1;
l1 = l1->next;
l2 = l2->next;
}
return nullptr;
}
};
复杂度:
O(n) n为较长的链表长度
O(1)
官解,双指针
只有当链表
headA
\textit{headA}
headA
和
headB
\textit{headB}
headB
都不为空时,两个链表才可能相交。因此首先判断链表
headA
\textit{headA}
headA
和
headB
\textit{headB}
headB
是否为空,如果其中至少有一个链表为空,则两个链表一定不相交,返回
null
\text{null}
null
。
当链表
headA
\textit{headA}
headA
和
headB
\textit{headB}
headB
都不为空时,创建两个指针 \textit{pA}pA 和 \textit{pB}pB,初始时分别指向两个链表的头节点
headA
\textit{headA}
headA
和
headB
\textit{headB}
headB
,然后将两个指针依次遍历两个链表的每个节点。具体做法如下:
-
每步操作需要同时更新指针
pA\textit{pA}
pA
和
pB\textit{pB}
pB
。 -
如果指针
pA\textit{pA}
pA
不为空,则将指针
pA\textit{pA}
pA
移到下一个节点;如果指针
pB\textit{pB}
pB
不为空,则将指针
pB\textit{pB}
pB
移到下一个节点。 -
如果指针
pA\textit{pA}
pA
为空,则将指针
pA\textit{pA}
pA
移到链表
headB\textit{headB}
headB
的头节点;如果指针
pB\textit{pB}
pB
为空,则将指针
pB\textit{pB}
pB
移到链表
headA\textit{headA}
headA
的头节点。 -
当指针
pA\textit{pA}
pA
和
pB\textit{pB}
pB
指向同一个节点或者都为空时,返回它们指向的节点或者
null\text{null}
null
。

class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
if (headA == nullptr || headB == nullptr) {
return nullptr;
}
ListNode *pA = headA, *pB = headB;
while (pA != pB) {
pA = (pA == nullptr) ? headB : pA->next;
pB = (pB == nullptr) ? headA : pB->next;
}
return pA;
}
};
复杂度分析
-
时间复杂度:O(m+n),其中 m 和 n 是分别是链表
headA\textit{headA}
headA
和
headB\textit{headB}
headB
的长度。两个指针同时遍历两个链表,每个指针遍历两个链表各一次。 - 空间复杂度:O(1)。
剑指 Offer 21. 调整数组顺序使奇数位于偶数前面
输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有奇数在数组的前半部分,所有偶数在数组的后半部分。
示例:
输入:nums = [1,2,3,4]
输出:[1,3,2,4]
注:[3,1,2,4] 也是正确的答案之一。
提示:
0 <= nums.length <= 50000
0 <= nums[i] <= 10000
我的思路:前后指针
class Solution {
public:
void _swap(vector<int>& nums, int i, int j)
{
int tmp=nums[i];
nums[i] = nums[j];
nums[j] = tmp;
return ;
}
vector<int> exchange(vector<int>& nums) {
int i=0, j=nums.size()-1;
while (i < j)
{
if (nums[i]%2==0 && nums[j]%2==1) _swap(nums, i++, j--);
if (nums[i]%2==1) ++i;
if (nums[j]%2==0) --j;
}
return nums;
}
};
复杂度分析:O(n), O(1)
快慢双指针
-
定义快慢双指针
fast
和
low
,
fast
在前,
low
在后 . -
fast
的作用是向前搜索奇数位置,
low
的作用是指向下一个奇数应当存放的位置 -
fast
向前移动,当它搜索到奇数时,将它和
nu
m
s
[
l
o
w
]
nums[low]
n
u
m
s
[
l
o
w
]
交换,此时
low
向前移动一个位置 . -
重复上述操作,直到
fast
指向数组末尾 .
class Solution {
public:
vector<int> exchange(vector<int>& nums) {
int low = 0, fast = 0;
while (fast < nums.size()) {
if (nums[fast] & 1) {
swap(nums[low], nums[fast]);
low ++;
}
fast ++;
}
return nums;
}
};
复杂度分析:O(n), O(1)
剑指 Offer 58 – I. 翻转单词顺序
输入一个英文句子,翻转句子中单词的顺序,但单词内字符的顺序不变。为简单起见,标点符号和普通字母一样处理。例如输入字符串”I am a student. “,则输出”student. a am I”。
示例 1:
输入: "the sky is blue"
输出: "blue is sky the"
示例 2:
输入: " hello world! "
输出: "world! hello"
解释: 输入字符串可以在前面或者后面包含多余的空格,但是反转后的字符不能包括。
示例 3:
输入: "a good example"
输出: "example good a"
解释: 如果两个单词间有多余的空格,将反转后单词间的空格减少到只含一个。
说明:
无空格字符构成一个单词。
输入字符串可以在前面或者后面包含多余的空格,但是反转后的字符不能包括。
如果两个单词间有多余的空格,将反转后单词间的空格减少到只含一个。
我的解法; 多次翻转
class Solution {
public:
void _swap(string& s, int i, int j)
{
char tmp=s[i];
s[i] = s[j];
s[j] = tmp;
}
string reverseWords(string s) {
if (s.size()==0) return s;
int i=0, j=s.size()-1;
while (i<j) _swap(s, i++, j--); // 整体翻转
i = j = 0;
while (j<=s.size()-1) // 局部翻转
{
if (s[j]==' ')
{
int left=i, right=j-1;
while (right>left) _swap(s, left++, right--);
i = j;
}
if (s[i]==' ') ++i;
if (j==s.size()-1) // 针对最一位
{
while (i<j) _swap(s, i++, j--);
break;
}
++j;
}
int len = s.size();
// 用于除去多余空格
for (int i=0; i<s.size(); ++i)
{
if (s[i] == ' ' && i==0)
{
s.erase(i--, 1);
--len;
continue;
}
if (i!=0 && s[i-1]==' ' && s[i]==' ')
{
s.erase(i--, 1);
--len;
}
if (i == len-1)
{
if (s[i]==' ') s.erase(i, 1);
break;
}
}
return s;
}
};
方法二:双指针
熟练运用string的方法
class Solution {
public:
string reverseWords(string s) {
string res;
int n = s.size();
if(n == 0) return res;
int right = n - 1;
while(right >= 0){
//从后往前寻找第一字符
while(right >= 0 && s[right] == ' ') right--;
if(right < 0) break;
//从后往前寻找第一个空格
int left = right;
while( left >= 0 && s[left] != ' ' ) left--;
//添加单词到结果
res += s.substr(left + 1, right - left);
res += ' ';
//继续往前分割单词
right = left;
}
//去除最后一个字符空格
if (!res.empty()) res.pop_back();
return res;
}
};
复杂度分析:
时间复杂度 O(N): 其中 N 为字符串 s 的长度,线性遍历字符串。
空间复杂度 O(N):