上一节我们深入探讨了,Hopfield神经网络的性质,介绍了吸引子和其他的一些性质,而且引出了伪吸引子,因为伪吸引子的存在导致Hopfield神经网络正确率下降,因此本节致力于解决伪吸引子的存在。在讲解方法之前我们需要再次理解一些什么是伪吸引子,他到底是如何产生的?
简单来说说就是网络动态转移过程,状态掉进了局部最优解里了,就是能量函数没有达到最低,只是掉进了局部能量最低的状态,这和我们梯度容易获得局部最优解差不多,大家这样理解就好,想要深入理解的建议自己多参考文献。为了解决伪吸引子的问题,人们提出了模拟退火算法和玻尔兹曼机彻底解决了伪吸引子的问题,但是带来的另外一个问题就是计算量很大,这些我们会一步步的讲解。好,我们知道了问题,也知道了方法,现在是看看到底如何解决的,但是前提我们需要搞明白什么是模拟退火算法。
模拟退火算法:
为了解决局部最优解问题, 1983年,Kirkpatrick等提出了模拟退火算法(SA)能有效的解决局部最优解问题。我们知道在分子和原子的世界中,能量越大,意味着分子和原子越不稳定,当能量越低时,原子越稳定。‘退火’是物理学术语,指对物体加温在冷却的过程。模拟退火算法来源于晶体冷却的过程,如果固体不处于最低能量状态,给固体加热再冷却,随着温度缓慢下降,固体中的原子按照一定形状排列,形成高密度、低能量的有规则晶体,对应于算法中的全局最优解。而如果温度下降过快,可能导致原子缺少足够的时间排列成晶体的结构,结果产生了具有较高能量的非晶体,这就是局部最优解。因此就可以根据退火的过程,给其在增加一点能量,然后在冷却,如果增加能量,跳出了局部最优解,这本次退火就是成功的,下面我们就详细讲讲他是如何在局部最优解跳出来到全局最优解的:
模拟退火算法包含两个部分即Metropolis算法和退火过程。Metropolis算法就是如何在局部最优解的情况下让其跳出来,是退火的基础。1953年Metropolis提出重要性采样方法,即以概率来接受新状态,而不是使用完全确定的规则,称为Metropolis准则,计算量较低。下面先形象的说一下,然后在因此数学公式:
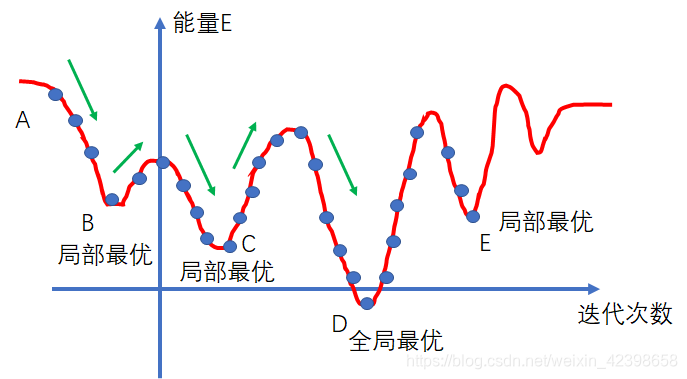
假设开始状态在A,随着迭代次数更新到B的局部最优解,这时发现更新到B时,能力比A要低,则说明接近最优解了,因此百分百转移,状态到达B后,发现下一步能量上升了,如果是梯度下降则是不允许继续向前的,而这里会以一定的概率跳出这个坑,这各概率和当前的状态、能量等都有关系,下面会详细说,如果B最终跳出来了到达C,又会继续以一定的概率跳出来,可能有人会迷惑会不会跳回之前的B呢?下面会解释,直到到达D后,就会稳定下来。所以说这个概率的设计是很重要的,下面从数学方面进行解释。
假设前一个状态为
,系统根据某一指标(梯度下降,上节的能量),状态变为
,相应的,系统的能量由
变为
,定义系统由
变为
的接受概率P为:
从上式我们可以看到,如果能量减小了,那么这种转移就被接受(概率为1),如果能量增大了,就说明系统偏离全局最优值位置更远了,此时算法不会立刻将其抛弃,而是进行概率操作:首先在区间【0,1】产生一个均匀分布的随机数
,如果
P,则此种转移接受,否则拒绝转移,进入下一步,往复循环。其中P以能量的变化量和T进行决定概率P的大小,所以这个值是动态的。
退火算法的参数控制
Metropolis算法是模拟退火算法的基础,但是直接使用Metropolis算法 可能会导致寻优速度太慢,以至于无法实际使用,为了确保在有限的时间收敛,必须设定控制算法收敛的参数,在上面的公式中,可以调节的参数就是T,T如果过大,就会导致退火太快,达到局部最优值就会结束迭代,如果取值较小,则计算时间会增加,实际应用中采用退火温度表,在退火初期采用较大的T值,随着退火的进行,逐步降低,具体如下:
(1)初始的温度T(0)应选的足够高,使的所有转移状态都被接受。初始温度越高,获得高质量的解的概率越大,耗费的时间越长。
(2) 退火速率。 最简单的下降方式是指数式下降:
其中
是小于1的正数,一般取值为0.8到0.99之间。使的对每一温度,有足够的转移尝试,指数式下降的收敛速度比较慢,其他下降方式如下:
(3)终止温度
如果在若干次迭代的情况下每有可以更新的新状态或者达到用户设定的阈值,则退火完成。
模拟退火的步骤:
1.模拟退火算法可以分解为解空间、目标函数和初始解三部分。
2.模拟退火的基本思想:
(1) 初始化:初始温度T(充分大),初始解状态S(是算法迭代的起点),每个T值的迭代次数L
(2) 对k=1, …, L做第(3)至第6步:
(3) 产生新解S′
(4) 计算增量ΔT=C(S′)-C(S),其中C(S)为代价函数
(5) 若ΔT<0则接受S′作为新的当前解,否则以概率exp(-ΔT/T)接受S′作为新的当前解.
(6) 如果满足终止条件则输出当前解作为最优解,结束程序。
终止条件通常取为连续若干个新解都没有被接受时终止算法。
(7) T逐渐减少,且T->0,然后转第2步。
模拟退火算法新解的产生和接受可分为如下四个步骤:
第一步是由一个产生函数从当前解产生一个位于解空间的新解;为便于后续的计算和接受,减少算法耗时,通常选择由当前新解经过简单地变换即可产生新解的方法,如对构成新解的全部或部分元素进行置换、互换等,注意到产生新解的变换方法决定了当前新解的邻域结构,因而对冷却进度表的选取有一定的影响。
第二步是计算与新解所对应的目标函数差。因为目标函数差仅由变换部分产生,所以目标函数差的计算最好按增量计算。事实表明,对大多数应用而言,这是计算目标函数差的最快方法。
第三步是判断新解是否被接受,判断的依据是一个接受准则,最常用的接受准则是Metropolis准则: 若ΔT<0则接受S′作为新的当前解S,否则以概率exp(-ΔT/T)接受S′作为新的当前解S。
第四步是当新解被确定接受时,用新解代替当前解,这只需将当前解中对应于产生新解时的变换部分予以实现,同时修正目标函数值即可。此时,当前解实现了一次迭代。可在此基础上开始下一轮试验。而当新解被判定为舍弃时,则在原当前解的基础上继续下一轮试验。
模拟退火算法与初始值无关,算法求得的解与初始解状态S(是算法迭代的起点)无关;模拟退火算法具有渐近收敛性,已在理论上被证明是一种以概率l 收敛于全局最优解的全局优化算法;模拟退火算法具有并行性。
退火算法程序流程图;

上面就是模拟退火算法的全部内容了,本节讲的仅仅是可以应用在任何出现局部最优解的的算法上,还没和 Hopfield神经网络结合在一起解决伪吸引子的问题,把退火算法和Hopfield神经网络结合在一起就是玻尔兹曼机了,下一节在详细探讨,本节到此结束。