1.定义
精确度(precision)/查准率:TP/(TP+FP)=TP/P 预测为真中,实际为正样本的概率
召回率(recall)/查全率:TP/(TP+FN) 正样本中,被识别为真的概率
假阳率(False positive rate):FPR = FP/(FP+TN) 负样本中,被识别为真的概率
真阳率(True positive rate):TPR = TP/(TP+FN) 正样本中,能被识别为真的概率
准确率(accuracy):ACC =(TP+TN)/(P+N) 所有样本中,能被正确识别的概率
宏查X率:先计算查X率,后计算平均
微查X率:先计算TP等平均,后计算查X率
丢失率(missrate )/漏警率:MA = 1-recall=FN/(TP+FN)
虚警率(FalseAlarm ):FA=FP/(FP+TP)
ground truch:TP+FN
model result:TP+FP
P:precision,预测正确的个数/测试总个数
AP:average precision,每一类别P值的平均值
MAP:mean average precision,对所有类别的AP取均值
2.评价指标
2.1P-R曲线/查准率-查全率曲线/精确度-召回率曲线
纵轴为精确度P,横轴为召回率R,单调减少。好的模型应该是在recall增长的同时保持precision的值在一个很高的水平,而性能较差的模型要损失很多precision才能换来recall值的提高。
评价指标一:BEP平衡点(Break-Even Point)
可用平衡点(P=R时的取值)度量,平衡点取值高的学习器更优。
评价指标二:Fβ度量
Fβ=(1+β^2)*P*R/[(β^2*P)+R]
F1=2*P*R/(P+R)
其中β(>0)用来衡量查全率和查准率之间的相对重要性,β>1时查全率R更重要,β<1时查准率P更重要
评价指标三:mAP
mAP,mean average precision,其中的AP就是这个曲线下的面积,average是对recall取平均,mean是对所有类别取平均(每一个类当做一次二分类任务)
2.2ROC曲线
纵轴为真阳率TPR,横轴为假阳率FPR,单调增加,越抖越好,由于样本数有限一般是锯齿状的。按照计算值排序后把样本一个一个当做正例预测。
评价指标:AUC
ROC下的面积,计算公式可简记为,多个矩形面积之和 。
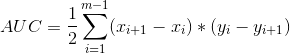
2.3 代价敏感错误率,代价曲线
不同的错误导致非均等代价


2.4FPPW(False Positive Per Window)
给定一定数量的负样本,计算:
FPPW=FP/图片集大小N
这里的FP是对于图的概念,比如在识别猫时,把负样本狗识别为猫
2.5FPPI(False Positive Per Image)
FPPI=FP/图片集大小N
这里的FP是对于bounding box的概念,比如在行人识别时,一张图会出现多个人,根据识别结果和gt的iou判断TP还是FP,统计FP总次数
2.6 fppi-missrate曲线
横轴为fppi,纵轴为missrate,根据fppi下的missrate 的MR = np.exp(np.log(score).mean())
参考网址:
https://blog.csdn.net/lydia2012924/article/details/78088336/
https://blog.csdn.net/u014380165/article/details/77493978
扩充阅读:
https://en.wikipedia.org/wiki/Sensitivity_and_specificity