最近由于实验需要,收集整理了关系抽取方向的数据集,主要包括SemEval、Wiki80、NYT10。目前来说全监督的关系抽取任务一般在SemEval上做,远程监督的关系抽取任务一般在NYT10上做。
SemEval
数据集来源
SemEval数据集来自于2010年的国际语义评测大会中Task 8:” Multi-Way Classification of Semantic Relations Between Pairs of Nominals “
数据集介绍
任务:对于给定了的句子和两个做了标注的名词,从给定的关系清单中选出最合适的关系。
数据集中一共包含9+1个关系,各类数据的占比如下图所示:
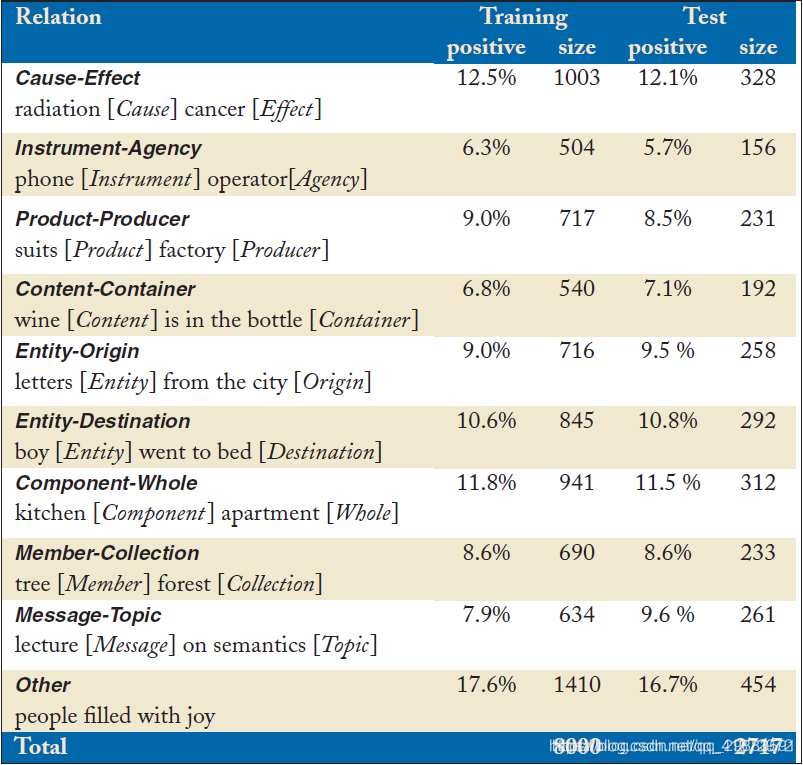
实际下载到的数据集来源自:https://github.com/thunlp/OpenNRE/tree/master/benchmark,格式均为json
SemEval 文件夹中包含四个文件:
semeval_rel2id.json:各类关系及其索引的对照标,这里面同一种关系由于两个实体e1、e2的前后位置不同分成了两个关系(例如“Product-Producer(e2,e1)&Product-Producer(e1,e2))所以算上关系”Other”一共是(0-18)19种关系.
semeval_train.txt & semeval_val.txt:原始的SemEval-Task-8数据集中一共有8000个样本作为train,但是这里得到的数据集是将原始的train分割成了train(6507个样本)以及val(1493个样本)均为json格式,且同一关系的样本分布在一起。
semeval_test.txt:与train以及val中的样本格式一致,包含2717个样本
样本格式:
例子:{“token”: [“trees”, “grow”, “seeds”, “.”], “h”: {“name”: “trees”, “pos”: [0, 1]}, “t”: {“name”: “seeds”, “pos”: [2, 3]}, “relation”: “Product-Producer(e2,e1)”}
其中包含四个键:
“token”:标记处理后的句子
“h”:样本中的头实体的名字以及位置
“t”:样本中的尾实体的名字以及位置
“relation”:样本中两个实体的关系,例子中关系是Product-Producer(e2,e1),表示实体1(头实体)是Producer,实体2(尾实体)是Product.
semeval数据集采用人工精标,不包含噪声
参考
数据官网:http://semeval2.fbk.eu/semeval2.php?location=tasks#T11
数据来源:https://github.com/thunlp/OpenNRE/tree/master/benchmark
数据统计:https://blog.csdn.net/qq_29883591/article/details/88567561
Wiki80
数据集来源
根据OpenNRE上的原文(We also provide a new dataset Wiki80, which is derived from FewRel.)来看Wiki80是由清华发布的数据集FewRel上提取的。
数据集介绍
任务:对于给定了的句子和两个做了标注的名词,从给定的关系清单中选出最合适的关系。
数据集中一共包含80中关系,经统计各个关系个数均为700,合计56000个样本。
| 关系 | 个数 |
|---|---|
| place served by transport hub | 700 |
| mountain range | 700 |
| religion | 700 |
| participating team | 700 |
| contains administrative territorial entity | 700 |
| head of government | 700 |
| country of citizenship | 700 |
| original network | 700 |
| heritage designation | 700 |
| performer | 700 |
| participant of | 700 |
| position held | 700 |
| has part | 700 |
| location of formation | 700 |
| located on terrain feature | 700 |
| architect | 700 |
| country of origin | 700 |
| publisher | 700 |
| director | 700 |
| father | 700 |
| developer | 700 |
| military branch | 700 |
| mouth of the watercourse | 700 |
| nominated for | 700 |
| movement | 700 |
| successful candidate | 700 |
| followed by | 700 |
| manufacturer | 700 |
| instance of | 700 |
| after a work by | 700 |
| member of political party | 700 |
| licensed to broadcast to | 700 |
| headquarters location | 700 |
| sibling | 700 |
| instrument | 700 |
| country | 700 |
| occupation | 700 |
| residence | 700 |
| work location | 700 |
| subsidiary | 700 |
| participant | 700 |
| operator | 700 |
| characters | 700 |
| occupant | 700 |
| genre | 700 |
| operating system | 700 |
| owned by | 700 |
| platform | 700 |
| tributary | 700 |
| winner | 700 |
| said to be the same as | 700 |
| composer | 700 |
| league | 700 |
| record label | 700 |
| distributor | 700 |
| screenwriter | 700 |
| sports season of league or competition | 700 |
| taxon rank | 700 |
| location | 700 |
| field of work | 700 |
| language of work or name | 700 |
| applies to jurisdiction | 700 |
| notable work | 700 |
| located in the administrative territorial entity | 700 |
| crosses | 700 |
| original language of film or TV show | 700 |
| competition class | 700 |
| part of | 700 |
| sport | 700 |
| constellation | 700 |
| position played on team / speciality | 700 |
| located in or next to body of water | 700 |
| voice type | 700 |
| follows | 700 |
| spouse | 700 |
| military rank | 700 |
| mother | 700 |
| member of | 700 |
| child | 700 |
| main subject | 700 |
| 合计 | 56000 |
Ps:这里56000个是val与train一起统计的
Wiki80 文件夹中共包含3个文件:
Wiki80_rel2id.json : 关系及其索引的对照表,合计80个关系,和Semeval中的不同,这里面的关系不包含实体的前后关系。
Wiki80_train.txt & wiki80_val.txt : trian(50400个样本)、val(5600个样本)合计56000个样本。
数据集中不包含测试集
样本格式:
例子:{“token”: [“Vahitahi”, “has”, “a”, “territorial”, “airport”, “.”], “h”: {“name”: “territorial airport”, “id”: “Q16897548”, “pos”: [3, 5]}, “t”: {“name”: “vahitahi”, “id”: “Q1811472”, “pos”: [0, 1]}, “relation”: “place served by transport hub”}
样本的格式同semeval中的几乎一致,但是在头实体和尾实体中加入了id这一属性。
Wiki80数据集采用人工精标,不包含噪声
参考:
数据来源:https://github.com/thunlp/OpenNRE/tree/master/benchmark
数据参考:https://opennre-docs.readthedocs.io/en/latest/get_started/benchmark
数据统计:自测
NYT10
数据集来源:
NYT10是在基于远程监督的关系抽取任务上最常用的数据集,NYT10数据集来自于10年的论文Modeling Relations and Their Mentions withoutLabeled Text,是由NYT corpus 同Freebase远程监督得到:
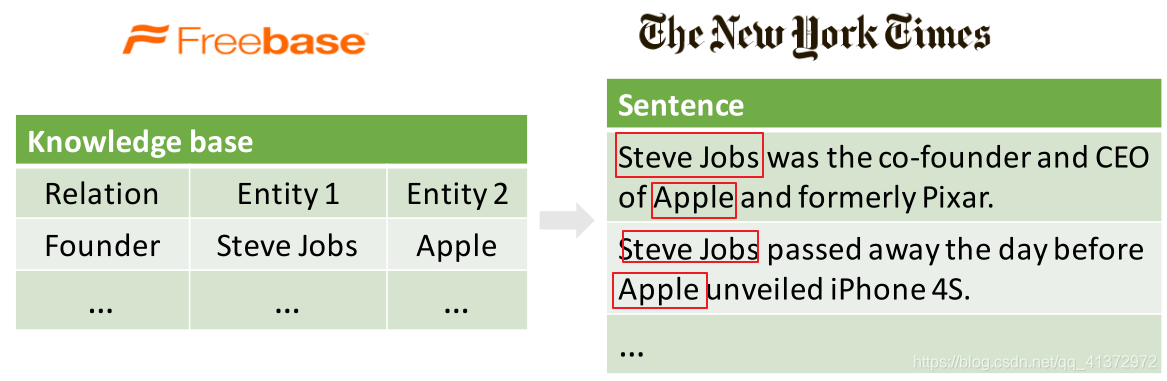
## 数据集介绍
任务:对于给定了的句子和两个做了标注的名词,从给定的关系清单中选出最合适的关系。
数据集中一共包含52+1(包括NA)个关系,各个关系在样本中的分布如下:
| relations | size_of_train | size_of_test |
|---|---|---|
| /location/fr_region/capital | 1 | 0 |
| /location/cn_province/capital | 2 | 0 |
| /location/in_state/administrative_capital | 4 | 0 |
| /base/locations/countries/states_provinces_within | 0 | 1 |
| /business/company/founders | 901 | 95 |
| /people/person/place_of_birth | 4053 | 162 |
| /people/deceased_person/place_of_death | 2422 | 68 |
| /location/it_region/capital | 22 | 0 |
| /people/family/members | 4 | 0 |
| /people/profession/people_with_this_profession | 2 | 0 |
| /location/neighborhood/neighborhood_of | 9275 | 68 |
| NA | 385664 | 166004 |
| /location/in_state/legislative_capital | 4 | 0 |
| /sports/sports_team/location | 294 | 10 |
| /people/person/religion | 202 | 6 |
| /location/in_state/judicial_capital | 3 | 0 |
| /business/company_advisor/companies_advised | 2 | 8 |
| /people/family/country | 6 | 0 |
| /time/event/locations | 4 | 4 |
| /business/company/place_founded | 648 | 20 |
| /location/administrative_division/country | 7286 | 424 |
| /people/ethnicity/included_in_group | 7 | 0 |
| /location/br_state/capital | 4 | 2 |
| /location/mx_state/capital | 1 | 0 |
| /location/province/capital | 39 | 11 |
| /people/person/nationality | 9733 | 723 |
| /business/person/company | 7336 | 302 |
| /business/shopping_center_owner/shopping_centers_owned | 1 | 0 |
| /business/company/advisors | 9 | 8 |
| /business/shopping_center/owner | 1 | 0 |
| /location/country/languages_spoken | 0 | 3 |
| /people/deceased_person/place_of_burial | 24 | 9 |
| /location/us_county/county_seat | 110 | 23 |
| /people/ethnicity/geographic_distribution | 86 | 136 |
| /people/person/place_lived | 8907 | 450 |
| /business/company/major_shareholders | 328 | 46 |
| /broadcast/producer/location | 71 | 0 |
| /location/us_state/capital | 798 | 39 |
| /broadcast/content/location | 8 | 0 |
| /business/business_location/parent_company | 19 | 0 |
| /location/jp_prefecture/capital | 2 | 0 |
| /film/film/featured_film_locations | 18 | 2 |
| /people/place_of_interment/interred_here | 24 | 9 |
| /location/de_state/capital | 7 | 0 |
| /people/person/profession | 10 | 0 |
| /business/company/locations | 19 | 0 |
| /location/country/capital | 8883 | 553 |
| /location/location/contains | 66721 | 2793 |
| /people/person/ethnicity | 148 | 13 |
| /location/country/administrative_divisions | 7286 | 424 |
| /people/person/children | 622 | 30 |
| /film/film_location/featured_in_films | 18 | 2 |
| /film/film_festival/location | 4 | 0 |
| 合计 | 522043 | 172448 |
NYT10文件夹中包含4个文件:
Nyt10_rel2id.json : 包含53个关系及其各自对应的索引
Nyt10_train.txt : 包含466876个样本
Nyt10_val.txt : 包含55167个样本
Nyt10_test.txt : 包含172448个样本
Ps:NYT10的数据集是通过远程监督得到的,所以样本的是根据包的形式分布的及含有相同实体的数据集分布在一起。
样本格式:
例子:
{“text”: “Hundreds of bridges were added to the statewide inventory after an earthquake in 1994 in Northridge , a suburb of Los Angeles .”, “relation”: “/location/neighborhood/neighborhood_of”,“h”:{“id”:”/guid/9202a8c04000641f800000000008fe6d”, “name”: “Northridge”, “pos”: [89, 99]}, “t”: {“id”: “/guid/9202a8c04000641f80000000060b2879”, “name”: “Los Angeles”, “pos”: [114, 125]}}
与Wiki80的样本格式相似,区别在于NYT10的文本没有进行标记处理。
NYT10数据集采用远程监督得到,包含噪声。
参考
数据来源:https://github.com/thunlp/OpenNRE/tree/master/benchmark
相关论文:https://link.springer.com/content/pdf/10.1007%2F978-3-642-15939-8_10.pdf
数据统计:自测
这里面所有的数据都来自于thunlp,另外比较常用的数据集:TACRED、ACE 2005官网上下载均需要LDC账号。如有大佬愿意提供,不胜感谢!