本文来自提案JVET-X0066和JVET-Y0143,在JVET-W次会议中提出了基于深度学习的环路滤波的提案,包括自适应参数选择和注意力机制的深度模型(EE1-1.2),以及残差缩放的深度模型(EE1-1.4)。此提案研究将两者结合的效果。
整个模型首先基于EE1-1.2修改,模型输入增加边界强度(BS)和QP,输入像素和经过模型滤波后的像素的残差再经过缩放因子来缩放。
网络结构
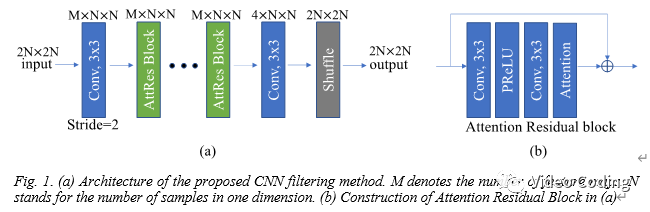
整个网络结构如Fig.1所示,其中注意力模型(attention model)的计算过程可以描述如下:
其中F_in和F_out分别是 attention model的输入输出,Rec,Pred,BS,QP分别表示重建值、预测值、边界强度和量化参数。f函数表示Fig.1.(b)中的两个卷积层和激活单元。
参数选择
每个slice或块都可以选择是否进行基于CNN的滤波,如果slice/block决定要使用基于CNN的滤波,则需要从候选列表{q,q-5,q-10}中选择条件参数,其中q是序列的QP。编码端的参数选择过程是基于RD cost的,如下:
-
滤波粒度决策和参数选择由分辨率和QP决定,对于更大的分辨率和QP决策和选择在更大的区域上进行。
-
对于不同时域层候选参数列表也不同,对于更高的时域层第三个候选q-10变为q+5。
-
对于all intra配置,禁用参数选择但仍保留标志位。
残差缩放
picture header中存有个分量的缩放因子,当对重建图像使用完基于CNN的滤波后,使用缩放因子对残差进行缩放。
推理和训练
使用PyTorch进行模型推理,具体信息如表1,

模型分别使用DIV2K和BVI-DVC数据集对I帧和B帧进行训练,对不同QP分别训练模型,具体如表2,

实验结果
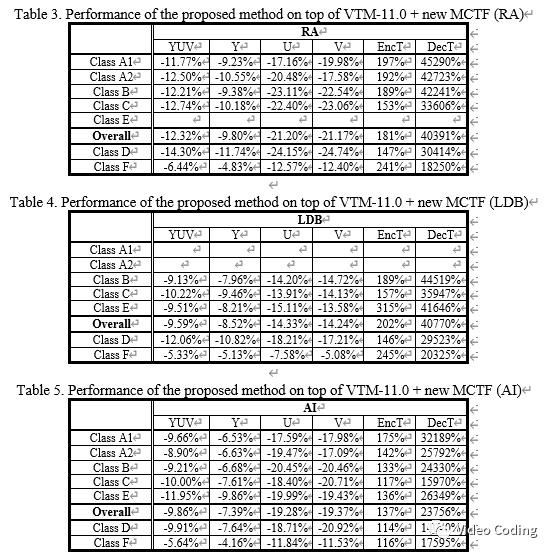
实验平台选择VTM-11.0+new MCTF,其中DF和SAO关闭,在使用CNN滤波后再使用ALF处理,实验结果如下,
实验平台选择ECM3.0,其中DF关闭,在使用CNN滤波后再使用SAO和ALF处理,实验结果如下,
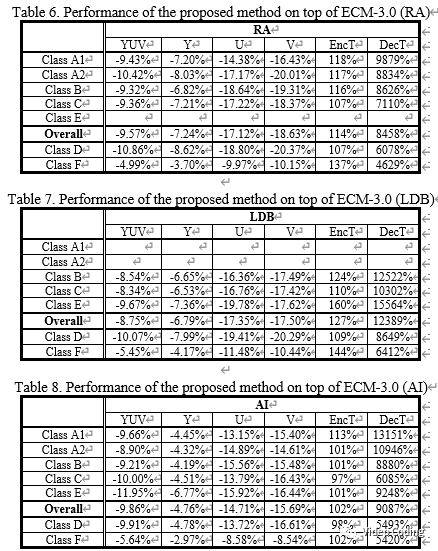
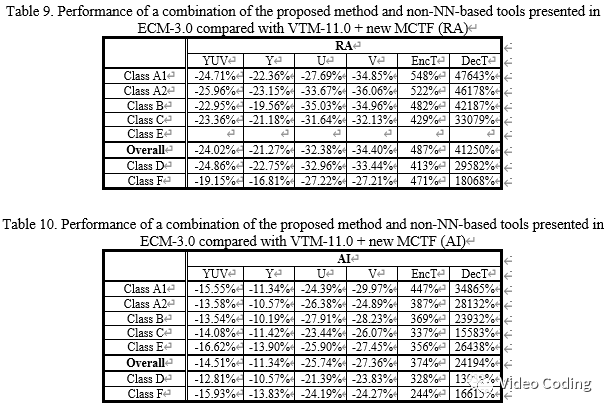
表9和10是基于NN的滤波和ECM3.0中的非NN滤波工具相结合后相对于VTM-11.0+new MCTF的结果,
感兴趣的请关注微信公众号Video Coding
