前言
- requests是同步的,效率较慢,但代码编写相对简单一些
- aiohttp是异步的,效率很高,但代码编写相对复杂一些(需要跟python自带库asyncio相结合使用)
使用requests访问100个url
import time
import requests
# 获取当前时间戳的匿名函数
now = lambda: time.time()
# 普通函数: 请求url获取响应,然后打印响应的状态码
def parse_url(url):
resp = requests.get(url)
print(resp.status_code)
# 入口函数
def run():
url = 'https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&tagAll=0&page={}'
for i in range(1, 101):
parse_url(url.format(i))
if __name__ == '__main__':
start_time = now()
run()
print(f"耗时: {now() - start_time}")
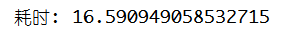
使用aiohttp访问100个url
import asyncio
import time
import aiohttp
# 获取当前时间戳的匿名函数
now = lambda: time.time()
# 协程函数: 请求url获取响应,然后打印响应的状态码
async def parse_url(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
print(resp.status)
# 入口函数
async def run():
url = 'https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&tagAll=0&page={}'
# 将多个协程任务 装进 tasks任务列表中
tasks = [parse_url(url.format(x)) for x in range(1, 101)]
await asyncio.wait(tasks)
if __name__ == '__main__':
start_time = now()
loop = asyncio.get_event_loop()
loop.run_until_complete(run())
print(f"耗时: {now() - start_time}")
# 下方代码是同步效果,即不恰当的调用方式
# start_time = now()
# loop = asyncio.get_event_loop()
# url = 'https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&tagAll=0&page={}'
# for i in range(1, 101):
# loop.run_until_complete(parse_url(url.format(i)))
# print(f"耗时: {now() - start_time}")
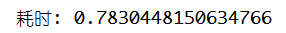
补充
两份代码的运行结果我只显示了消耗时间,响应状态码我并没有显示出来
-
从访问100个url的效率来看,很明显
aiohttp
比
requests
要快的多的多 -
如果
访问量增大
,
aiohttp
跟
requests
的访问效率之间的差异会越来越大
版权声明:本文为MarkAdc原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。