Python代码优化工具——line_profiler
一、工具介绍
line_profiler是Python的一个第三方库,其功能时基于函数的逐行代码分析工具。通过该库,可以对目标函数(允许分析多个函数)进行时间消耗分析,便于代码调优。
二、安装
使用命令
pip install line_profiler
进行安装。
三、分析结果注解
先放上这个工具的分析结果,各位朋友可以看一下是否满足自己的要求,再决定是否安装以及使用。
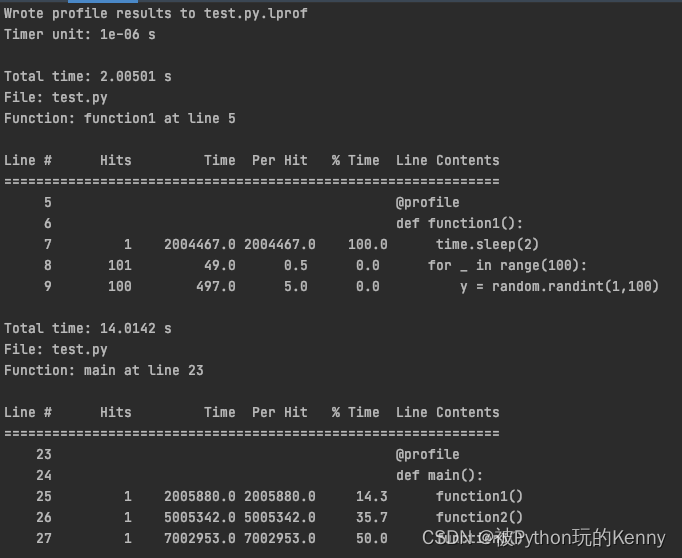
部分参数注解:
-
Timer unit:分析表中,Time和Per Hit的数值单位,时间单位固定为秒(s),默认数值单位是1e-6,合在一起便是1e-6s,即微秒。实际某一行的运行时间是Time * Timer unit的值,觉得不好理解的话,下方介绍
kernprof
命令时有一个示例供各位同学理解,这里只是简单提一下。 - Total time:当前函数的时间消耗,单位是秒。
- File:当前函数所在文件名。
- Function:当前函数的函数名以及在文件中的位置。
- Line #:代码所在行号。
- Hits:在执行过程中,该行代码执行次数,即命中数。
- Time:在执行过程中,该行代码执行的总时间,默认单位是微秒。
- Per Hit:在执行过程中,平均每次执行该行代码所耗时间,默认单位是微秒。
- % Time:执行该行代码所耗总时间占执行当前函数所耗总时间的百分比。
- Line Contents:该行代码的内容。
分析结果保存位置
待代码执行完毕后,会在
当前目录(注意,不是代码所在目录,而是执行命令的当前目录)
下生成一个后缀为
.lprof
的同名文件,该文件内存放的就是分析结果。
四、使用
line_profiler工具有三种使用姿势,各有利弊
1、使用
kernprof
命令进行分析
kernprof
(1)使用姿势
在想要分析的函数前加上装饰器
@profile
,然后在终端数据使用命令
kernprof
进行分析。
github 网址
该命令的具体参数如下:
usage: kernprof [-h] [-V] [-l] [-b] [-o OUTFILE] [-s SETUP] [-v] [-u UNIT]
[-z]
script ...
Run and profile a python script.
positional arguments:
script The python script file to run
args Optional script arguments
optional arguments:
-h, --help show this help message and exit
-V, --version show program's version number and exit
-l, --line-by-line Use the line-by-line profiler instead of cProfile.
Implies --builtin.
-b, --builtin Put 'profile' in the builtins. Use
'profile.enable()'/'.disable()', '@profile' to
decorate functions, or 'with profile:' to profile a
section of code.
-o OUTFILE, --outfile OUTFILE
Save stats to <outfile> (default: 'scriptname.lprof'
with --line-by-line, 'scriptname.prof' without)
-s SETUP, --setup SETUP
Code to execute before the code to profile
-v, --view View the results of the profile in addition to saving
it
-u UNIT, --unit UNIT Output unit (in seconds) in which the timing info is
displayed (default: 1e-6)
-z, --skip-zero Hide functions which have not been called
-
简单来说,如果想用
@profile
装饰器的方式分析代码,就需要使用
-l
参数。 -
默认分析结果会保存在
.prof
文件里,如果加了
-l
参数,则会将分析结果保存在
.lprof
文件里。 -
可以使用
python -m line_profiler <.lprof文件名>
查看分析结果,此时不会再次执行代码,只是查询分析结果。 -
如果需要在分析代码的同时打印分析结果,可以使用
-v
参数。 -
默认情况下,
@profile
装饰了几个函数,就会出现几张分析表,如果某个函数没有被执行,则其Hit、Time等值显示为空。可以使用
-z
参数隐去未执行函数的分析结果。需要注意的是,
-z
参数只是在显示时隐藏了未执行函数的分析表,但不是不分析该函数,当使用
python -m line_profiler <分析结果文件名>
时,还是可以看到未执行函数的分析表的。 -
想在分析代码之前,执行一些不加入分析的前置操作(比如配置环境变量等),可以使用
-s <前置操作的.py文件名>
,这样就会在执行分析代码所在的文件之前,先执行一遍前置操作文件。 -
想将分析结果保存到指定的文件,而不是默认的文件里,可以使用
-o [<文件路径>/]<文件名>
来指定。文件后缀不一定非要
.prof
或者
.lprof
,经测试结果保存到
.txt
文件也是可以的,使用
python -m line_profile <文件名.txt>
同样可以显示结果。 -
默认的时间数值单位,是1e-6,即微秒,我们可以通过
-u <数值>
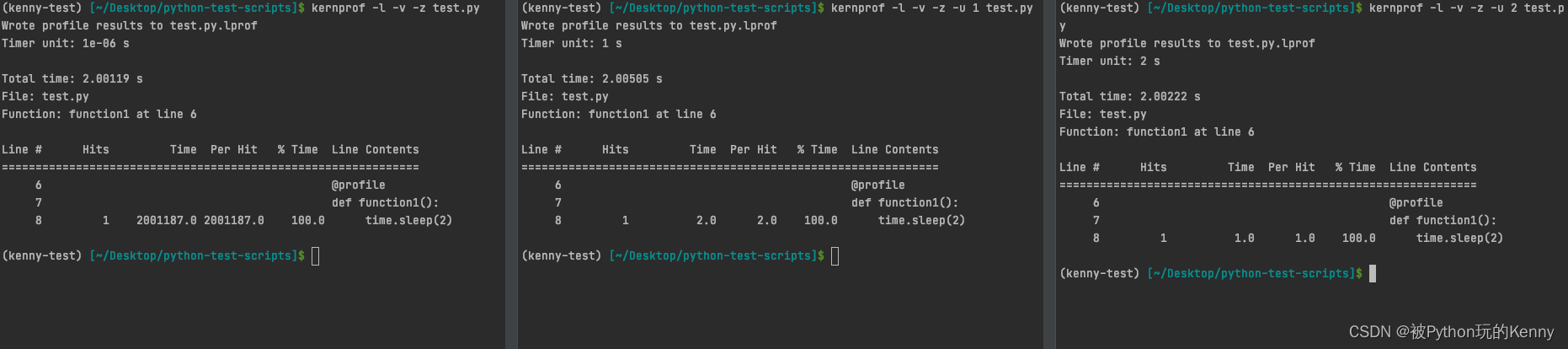
来修改。以下是示例:函数功能是睡眠2秒,但因为Timer unit的数值单位不一样,其显示的数值也不一样,但代表的含是一样的。
(2)示例:
代码如下,该示例共有三个函数,每个函数的功能都是睡眠一段时间后,构造10个随机数。
import random
import time
@profile
def function1():
time.sleep(2)
for _ in range(100):
y = random.randint(1,100)
def function2():
time.sleep(5)
for _ in range(100):
y = random.randint(1,100)
def function3():
time.sleep(7)
for _ in range(100):
y = random.randint(1,100)
@profile
def main():
function1()
function2()
function3()
if __name__ == "__main__":
main()
执行结果如下:
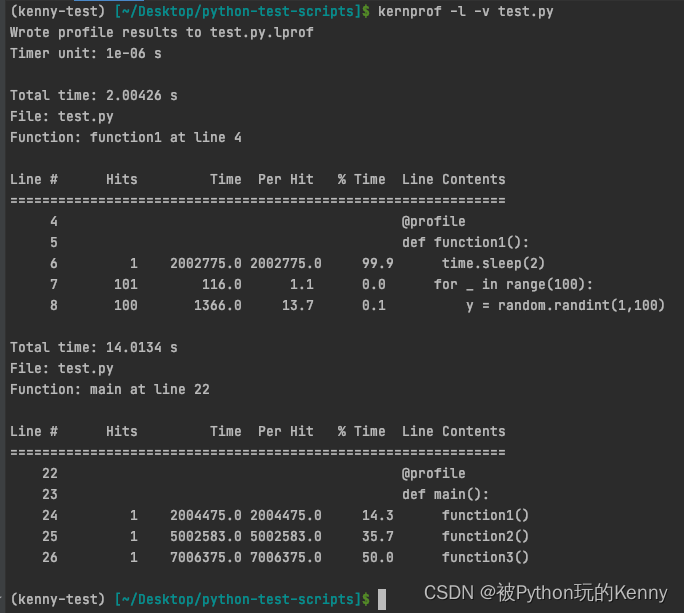
因为我只在
main
和
function1
函数加了装饰器,所以分析结果只有
main
和
function1
,实际使用时可以自行增加或减少函数。
(3)该姿势的利弊
优点
- 不用在代码里导入第三方包,也不用修改代码的实际逻辑,有利于维持原代码的整体性。
-
使用方便,只需在待分析的函数前加装饰器
@profile
即可。 - 用于分析的函数可以不在同一个文件内,方便分析较为复杂、调用方法较多的程序。
缺点
- 因为需要在所有待分析的函数前都需要加装饰器,所以添加和删除的麻烦度与待分析的函数的数量成正比。
-
因为
@profile
并不是第三方导入的,所以正常运行代码时会报错。 -
同样是因为
@profile
不是第三方导入的,在IDEA中该段代码会有代码错误的红色波浪线提示,强迫症震怒。
2、使用
python
命令进行分析
python
(1)使用姿势
需要在代码里引入第三方包
LineProfiler
,并在原代码里添加一些代码才可以实现,进行分析时就像平时执行代码一样
python <文件名>
即可。
(2)示例:
代码如下,该示例共有三个函数,每个函数的功能都是睡眠一段时间后,构造10个随机数。
import random
import time
from line_profiler import LineProfiler
def function1():
time.sleep(2)
for _ in range(100):
y = random.randint(1,100)
def function2():
time.sleep(5)
for _ in range(100):
y = random.randint(1,100)
def function3():
time.sleep(7)
for _ in range(100):
y = random.randint(1,100)
def main():
function1()
function2()
function3()
if __name__ == "__main__":
lp = LineProfiler() # 构造分析对象
"""如果想分析多个函数,可以使用add_function进行添加"""
lp.add_function(function1) # 添加第二个待分析函数
lp.add_function(function2) # 添加第三个待分析函数
test_func = lp(main) # 添加分析主函数,注意这里并不是执行函数,所以传递的是是函数名,没有括号。
test_func() # 执行主函数,如果主函数需要参数,则参数在这一步传递,例如test_func(参数1, 参数2...)
lp.print_stats() # 打印分析结果
"""
坑点:
1:test_func = lp(main)这一步,是实际分析的入口函数(即第一个被调用的函数,但不一定是main函数),所以这里封装的函数必须是测试脚本要执行的第一个函数。
2:test_func()这一步才是真正执行,如果缺少这一步,代码将不会被执行
3:lp.print_stats()这一步是打印分析结果,如果缺少这一步,将不会在终端看到分析结果。
4:分析结果只与是否加入分析队列有关,而不管该函数是否被实际执行,如果该函数加入分析但没有被执行,则Hits、Time等值为空。
"""
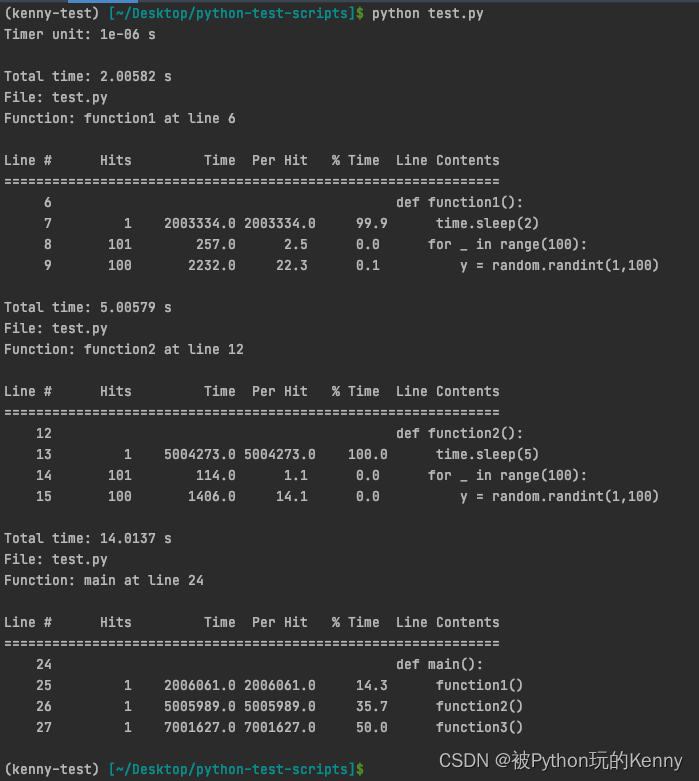
执行结果如下:
(3)该姿势的利弊
优点
- 添加/删除待分析函数方便,不用修改原代码,只需要在测试代码入口使用LineProfiler对象增加/删除待分析函数名即可。
- 测试命令与平时运行代码的相同,不用增加学习负担。
缺点
- 因为要导入第三方包以及创建LineProfiler对象,需要写一份专用于分析的测试脚本。
- 分析多个函数时,是使用add_function+函数名来实现的,所以需要显示地导入待分析函数,或者将待分析函数拷贝到当前分析脚本,对较为复杂的逻辑很不友好。
- 该姿势存在一些坑点,已在示例代码的备注中说明。
- 不会将分析结果保存到.lprof文件中。
3、在Jupyter Notebook内使用line_profile
这一种姿势在实际工作中不常用,感兴趣的可以移步这位大佬的文章:
line_profiler: Line by Line Profiling of Python Code