
前言
日常开发过程中,总是免不了要与数据库打交道。MySQL 在使用率和性价比上都是值得称道的,尤其默认引擎更新为
InnoDB
后,MySQL 迎来了一次质的飞跃。
虽然阿浪天天 CURD,但其实也有一颗想拳打 DBA 的心,教教他们为啥花儿那样红!(DBA:索引建的那么烂,还想拳打我)
1、InnoDB 简介
1.1、Who is MyISAM?
MyISAM 是 InnoDB 的前任,在 MySQL 5.1 版本以前存储引擎默认都是使用 MyISAM。其提供高速存储和检索、以及全文搜索能力。简单了解即可
1.2、InnoDB 的优势
随着业务发展,系统对并发度要求越来越高,MyISAM 的特性无法再满足日常开发,只能在特殊场景下保存着相对优势。
MyISAM 不支持事务,不具备 ACID 特性(
原子性
、
一致性
、
分离性
、
持久性
)。并且不支持行级锁只具有表级锁。且最大的缺陷就是崩溃后无法安全恢复,但是在读密集的业务场景下操作效率高。
所有的存储引擎中只有 InnoDB 是
事务性存储引擎
,也就是说只有 InnoDB 支持事务,事务管理在高并发中的重要性不言而喻。并且同时支持行级锁和表级锁,
支持 MVCC
。
2、MySQL 的逻辑架构
MySQL 从逻辑上来划分可分为
Server 层
和
存储引擎层
两部分。
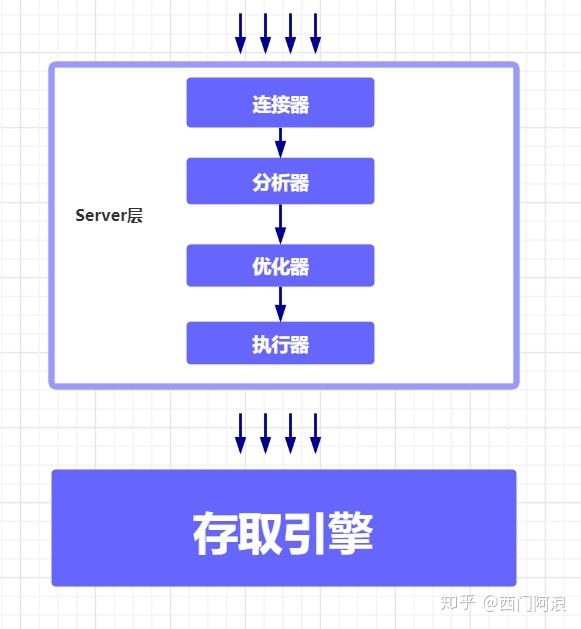
-
连接器
:负责客户端与服务端建立连接、获取权限、维持和管理连接。在完成经典的 TCP 握手后,连接器就要开始认证用户身份。连接时间由
wait_timeout 系统字段
控制的,默认值是 8 小时,如果太长时间没操作,连接器就会自动断开。 -
分析器
:首先会做
词法分析
,需要识别出 SQL 语句里面的字符串分别是什么,代表什么,解析出表和表内字段与SQL语句串内容相对应。根据词法分析的结果,
语法分析
会根据语法规则,判断输入的这个 SQL 语句是否满足 MySQL 语法,根据 select、delete 等关键字分析语句属于什么类型操作。。 -
优化器
:表里面有多个索引的时候,决定使用哪个索引;当语句有多表关联的时候,决定各个表的连接顺序。本质是为了提高执行效率和减低资源消耗。 -
执行器
:根据表的引擎定义,使用引擎提供的接口执行语句。

3、SELECT 原理
select 操作关系中与之最紧密联系的就是索引,但索引牵扯太多,为了提供最直观的执行逻辑,就先在此按下不表,后续文章讨论。
3.1、实例分析
当用户通过连接器成功建立连接后,就可以执行 SQL 语句了。
-
首先进入分析器
MySQL 首先需要知道阿浪要用这条语句做什么,因此需要对 SQL 语句做解析。
ssselect * from products pd where pd.prod_id = '001'
首先进行词法分析,把字符串products识别成表名,把prod_id与表中字段相对应。如果语句内存在不匹配的字段,将会报出一条error信息。
词法分析完成后进行语法分析,根据语句关键字解析出该SQL语句具体属于什么类型操作。但由于阿浪太过粗心把select打错了,词法分析会反馈一个error信息:
You have an error in your SQL syntax;…
,阿浪只能挠挠头,骂骂咧咧改掉它。
-
丢入优化器
经过分析器解析后,表明这是条可执行的SQL语句。但业务开发中相对较复杂的表结构和语句是如何通过优化器提高效率的呢?
CREATE TABLE utest (
id INT ( 5 ) PRIMARY KEY auto_increment,
name VARCHAR ( 20 ) NOT NULL,
age VARCHAR ( 20 ) NOT NULL,
KEY name_index (NAME),
KEY age_index (age)
) ENGINE = INNODB
优化器的主要作用在于当有多个索引时,根据具体SQL语句选择相应索引。
select u.name from utest u
根据语句可知,查询目标为name字段,而且表中name存在索引,因此无需全表扫描,优化器选择name索引进行检索。并且查询目标存在于name索引内,无需回表,属于覆盖索引。
当多表连接时会发生什么?
select * from a1 join a2 using(id) where a1.b=1 and a2.c=2;
这条语句无论是先执行a1.b=1还是先执行a2.c=2从执行和结果都是相同的。但由于a1与a2表结构不同,以及表内数据量的差异就会产生先后执行的差异,这就需要优化器来选择。
-
最后执行器
开始执行的时候,要先判断一下你对这个表T有没有执行查询的权限,如果没有,就会返回没有权限的错误。
如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。
4、UPDATE 原理
如果每一次的更新操作都需要写进磁盘,然后磁盘也要找到对应的那条记录,然后再更新,整个过程IO成本、内存成本都很高。redolog和binlog犹如
天降猛男
,在更新操作中大刀阔斧进行了一番改革。
4.1、 redo_log(重做日志)
redo_log是独属于InnoDB引擎的,使得InnoDB的更新操作相比于其它引擎更安全高效。
当有一条记录需要更新的时候,InnoDB引擎就会先把记录写到redo_log里,并更新内存,这个时候更新就算完成了。之后,InnoDB引擎会在适当的时候,将这个操作记录更新到磁盘里面,而这个更新往往是在系统比较空闲的时候做。
InnoDB的redo_log是固定大小的,比如可以配置为一组4个文件,每个文件的大小是1GB,那么总共就可以记录4GB的操作。从头开始写,写到末尾就又回到开头循环写。
writepos
是当前记录的位置,一边写一边后移。
checkpoint
是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到磁盘的数据文件。
writepos和checkpoint之间的是redo_log上还空着的部分,可以用来记录新的操作。如果writepos追上checkpoint,表示log满了,这时候不能再执行新的更新,得停下来先擦掉一些记录,把checkpoint推进一下。
4.2、binlog(归档日志)
binlog属于所有引擎,这么说并不严谨,因为binlog是Server层的操作记录,并不记录存储引擎的操作。
redo log是物理日志,记录的是“在某个数据页上做了什么修改”;binlog是逻辑日志,记录的是这个语句的原始逻辑
redo log是循环写的,空间固定会用完;binlog是可以追加写入的。“追加写”是指binlog文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
binlog的主要作用是为了解决由于误删或错误操作导致的库损伤。能够使库根据时间点恢复。
4.3、update具体流程
- 执行器从引擎读取符合条件的行数据。如果该行所在的数据页本来就在内存中,就直接返回给执行器。否则,需要先从磁盘读入内存,然后再返回。
- 执行器拿到引擎给的行数据,进行字段更新,得到新的一行数据,再调用引擎接口写入这行新数据。
-
引擎将这行新数据更新到内存中,同时将这个更新操作记录到redo_log里面,此时redo_log处于
prepare状态
。然后告知执行器执行完成了,随时可以提交事务。 - 执行器生成这个操作的binlog,并把binlog写入磁盘。
-
执行器调用引擎的提交事务接口,引擎把刚刚写入的redo_log改成提交
commit状态
,更新真正完成。
4.4、crash-safe能力
保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为crash-safe。
innodb_flush_log_at_trx_commit这个参数设置成1的时候,表示每次事务的redo_log都直接持久化到磁盘。这个参数建议设置成1,这样可以保证MySQL异常重启之后数据不丢失。
http://weixin.qq.com/r/AUxza–E9KKLrbsI9xkT (二维码自动识别)