本篇博客的算法来源的论文是
Neural Machine Translation of Rare Words with Subword Units
,感兴趣的读者可以自行在Google学术上搜索。
算法提出的问题背景
2016年左右(改论文发表于2016)Neural machine translation(NMT)中有着一个众所周知的问题——稀有词与未知词的翻译问题。一般来说,神经网络中的词表被限制在30000-50000个词汇,但是对于翻译来说,各种词汇都可能出现(比如英语中的复合词汇,网络新词等),这种限制无疑使问题解决得效果大打折扣。对于英语来说,一个单词可能有不同时态,进行时,过去时,一般现在时等,比如look, looking, looks, looked这些单词都表示的意思,但是传统处理手段就是在词表中为这些单词各开一个位置,这不仅造成了冗余,还削弱了它们之间的相关性。
基于上述问题,论文中提出将一个单词用可变长度表示,也就是关注于更小的分词单元(subword unit)似乎更加有吸引力。对于word-level的NMT模型,在遇到新词以后往往需要借助查阅字典的手段(15年左右被提出的一种方法,它假设source和target中的词汇是一 一对应的),论文作者认为这种假设在很多情况不适用,事实上也的确如此。此外,这种模型没法翻译或者生成没见过的单词。一些学者提出将未知的单词直接从source language复制到target language的翻译中,这对于名字来说确实很合理,但是在其他情况也许就不适用了。
算法希望实现的目标
创建一个subword-level的NMT模型,对于稀有词和未知词的翻译能够自己结果,能够生成在训练时没有见过的新词,能够从subword representations中学习复合词和音译词。
Byte Pair Encoding(BPE)
BPE算法最初是在1994提出的一种简单的数据压缩技术,它会迭代多次,每一次迭代的时候将出现频率最高的字节对用一个单个的,没出现过的字节替代,这样就从两个字节变成了一个字节。论文中采用了这个算法来做单词切割。只不过合并的不是字节对,而是单词中的字符或者字符序列。
首先,将每个单词用一个字符序列表示,然后在末尾增加一个单词结束符(比如look,就变成l o o k </w>),然后利用这些字符序列来统计字符对的频率。(l o o k 这个序列可以看作
l o
,
o o
,
o k
, k </w>这几个字符对)。每一轮迭代的时候将出现频率最高的字符对合并。每次合并产生一个新的symbol,它代表了一个n-gram的字符。最终新的symbol 词典的大小等于最初的词典大小加上merge操作的数量。我们可以将这个操作施加到从一个文本中统计出的词频表上。
算法实现
首先,词频表的key需要是一个字符序列,且在末尾加上一个单词结束符,字符之间有空格方便后面拆分
vocab = {
'l o w </w>':5,
'l o w e r </w>':2,
'n e w e s t </w>':6,
'w i d e s t </w>':3
}
第二步,我们需要构建自己的symbol表,也就是一个个字符对
from collections import defaultdict
#defaultdict会在查询的key missing时,给它一个默认值,比如我们下面的int类型的defaultdict
#它的默认值就是0
def get_stat(vocab_dict):
result = defaultdict(int)
for word,freq in vocab_dict.items():
symbol = word.split()
for i in range(len(symbol) - 1):
result[symbol[i],symbol[i+1]] += freq
return result

第三步,我们需要实现一个merge方法,它的作用是传入一个频率最高的字符对,我们在原始的vocab_dict中挨个检查每个sequence,如果包含这个字符对就将其合并。并增加这个字符对作为key
这块涉及到了正则表达式里面的零宽断言,详细可以查看我的另一篇博文
https://blog.csdn.net/qq_43152622/article/details/118967901?spm=1001.2014.3001.5501
re.compile('(?<!\S)' + bigram + '(?!\S)')
def Merge_vocab(pair,vocab_dict):
"""
pair:出现频率最高的字符对
vocab_dict:原始的词汇表
"""
v_out = dict()
bigram = re.escape( ' '.join(pair))#将一些特殊符号转移,返回待会正则匹配的时候出幺蛾子
p = re.compile('(?<!\S)' + bigram + '(?!\S)')
for word in vocab_dict:
w_out = p.sub(''.join(pair),word)
v_out[w_out] = vocab_dict[word]
return v_out

num_merges = 12
vocab_dict = {'l o w </w>' : 5, 'l o w e r </w>' : 2,'n e w e s t </w>':6, 'w i d e s t </w>':3,"f a s t e r </w>":5}
for i in range(num_merges):
pairs = get_stat(vocab_dict)
best =max(pairs, key=pairs.get)
vocab_dict = Merge_vocab(best, vocab_dict)
print(best)
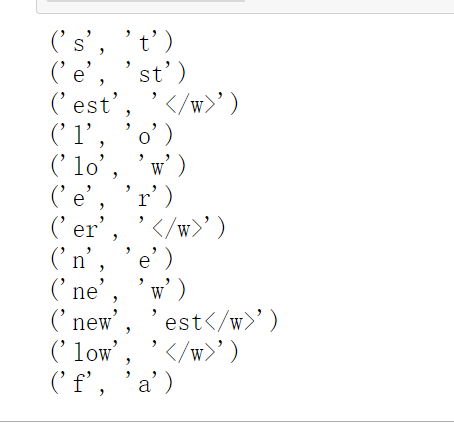

可以看到最后的结果中一些出现次数最多的subword已经被合并了。