运行环境
- windows11
- JDK 8
- anaconda3
- python 3.9
- Neo4j 3.5.32
- python jupyter库
- py2neo
- Visual Studio Code 2022
项目地址:
Gitee :
https://gitee.com/ccuni/py2neo-neo4j-actual-combat
GitHub:
https://github.com/unirithe/py2neo-neo4j-actual-combat
一、数据集说明
数据集来自 IMDB 影视网的电影、演员数据,数据并不全,仅供学习参考。
数据集参考上方的 Gitee 或 GitHub地址
-
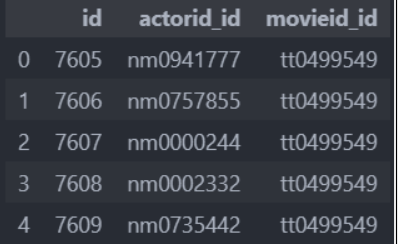
movie_act.csv 演员id到电影id的映射信息
-
-
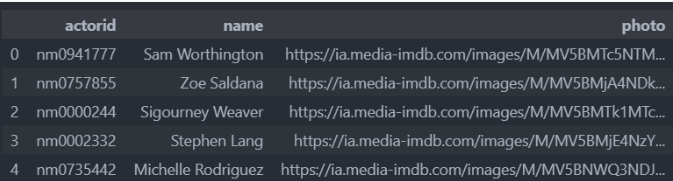
movie_actor.csv 5334个演员的信息,名称和头像
-
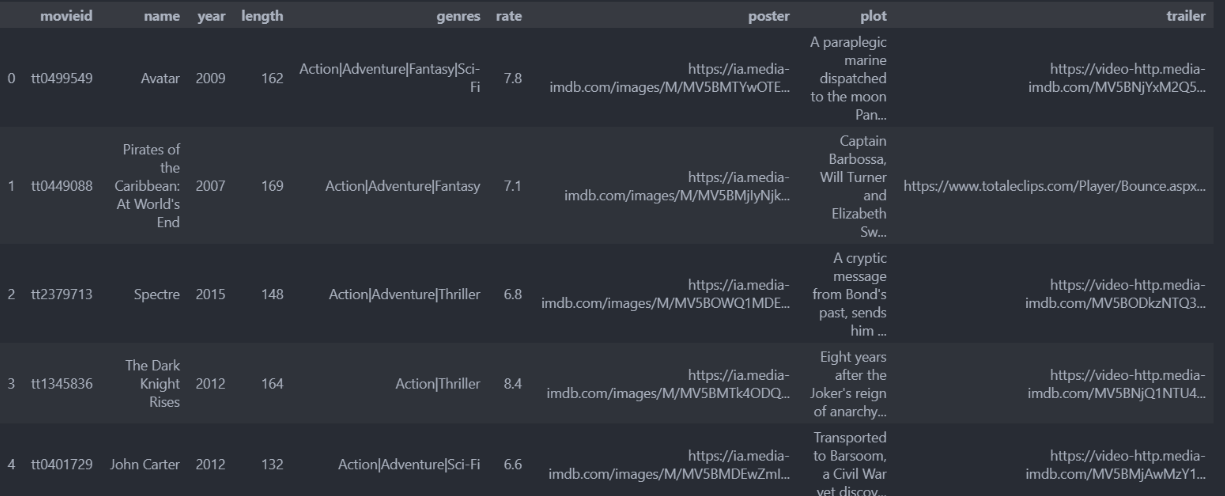
movie_moive.csv 2926部电影的详情信息
-
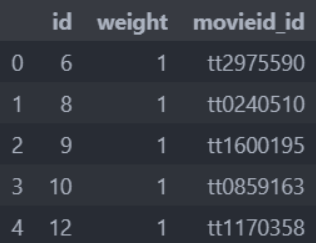
movie_popularity.csv 保留着62部受欢迎的电影信息
-
user_user.csv 不知道有啥用的id信息
二、数据预处理
这里将原先的csv数据转为 pandas的DataFrame后再转化成字典,从而能构建Node对象,插入到Neo4j中
2.1 选择受欢迎的电影
list_mid = df['popularity']['movieid_id']
# 查找受欢迎的电影信息
# Find the movies which is popularity
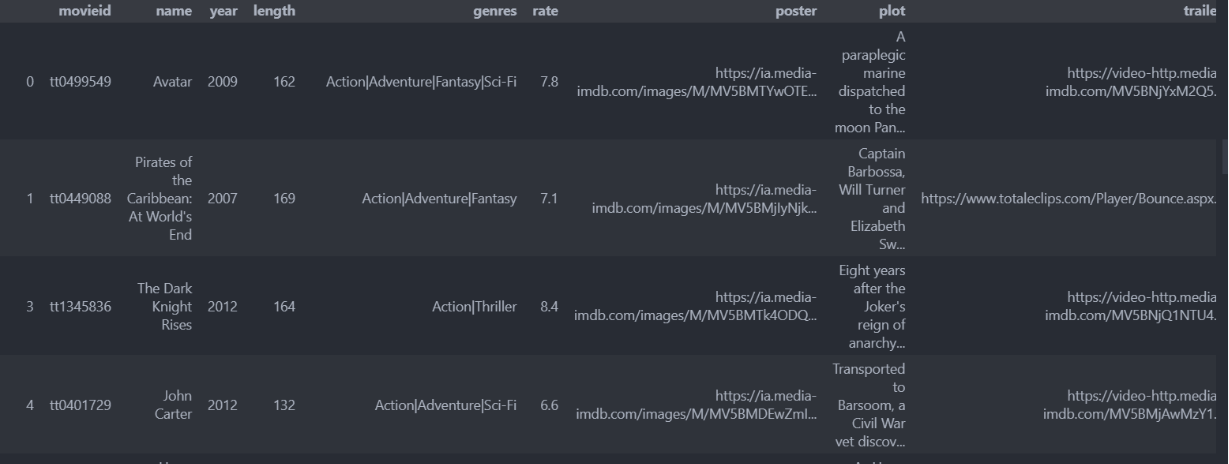
df_popularity_movie = df['movie'][df['movie']['movieid'].isin(list_mid)]
df_popularity_movie
# 将DataFrame格式转化为dict,到时候方便插入Neo4j
# make DataFrame to Dict, in order to insert neo4j
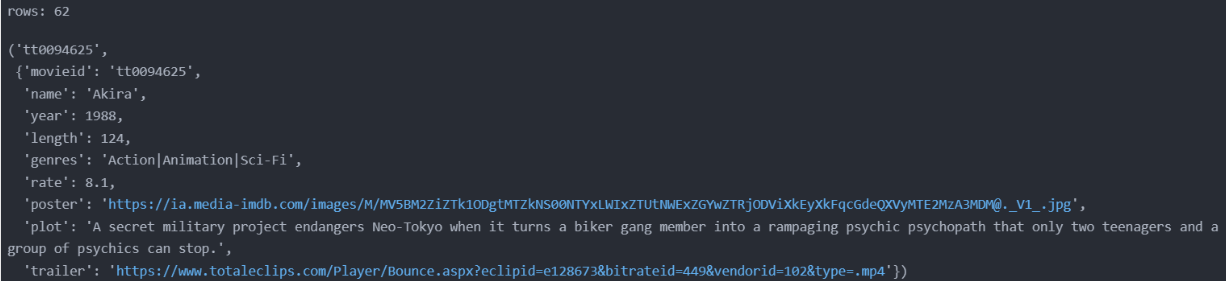
dict_movie = {}
for i in range(len(df_popularity_movie)):
row = df_popularity_movie.iloc[i]
dict_movie.update({row['movieid'] : row.to_dict()})
print('rows: ' , len(dict_movie))
2.2 查找每部受欢迎电影的所有演员
dict_actor_movie = {}
for mid in df_popularity_movie['movieid']:
flag = df['actor_movie']['movieid_id'].eq(mid)
actors = df['actor_movie'][flag]['actorid_id'].to_list()
dict_actor_movie.update({mid : actors})
print('rows: ' , len(dict_actor_movie))

2.3 查找热门电影里每个演员的信息
dict_actor = {}
actors = set()
for ac in dict_actor_movie.values():
for actor in ac:
actors.add(actor)
for aid in actors:
flag = (df['actor']['actorid'] == aid)
row = df['actor'][flag].iloc[0]
dict_actor.update({aid: row.to_dict()})
print('rows: ' , len(dict_actor_movie))

三、Py2Neo 操作
3.1 连接 Neo4j
from py2neo import Graph
url = "http://localhost:7474"
username = "neo4j"
password = "123456"
graph = Graph(url, auth=(username, password))
print("neo4j info: {}".format(str(graph)))
输出结果:neo4j info: Graph(‘http://localhost:7474’)
3.2 插入电影和演员节点
from py2neo import Graph, Node, Subgraph
import time
s_time = time.time()
node_list = []
graph.delete_all()
for mid, movie in dict_movie.items():
node_list.append(Node("movie", **movie))
for aid, actor in dict_actor.items():
node_list.append(Node("actor", **actor))
graph.create(subgraph=Subgraph(node_list))
# 查看一个节点
print(node_list[0])

输出当前Neo4j 电影和演员节点的个数
print('movie: ', graph.nodes.match("movie").count())
print('actor: ', graph.nodes.match('actor').count())
输出结果:
movie: 62
actor: 240
3.3 建立电影和演员之间的联系
from py2neo import NodeMatcher, Relationship
node_matcher = NodeMatcher(graph)
list_rel = []
for mid, actors in dict_actor_movie.items():
node_movie = node_matcher.match("movie", movieid=mid).first()
if node_movie != None:
for actor in actors:
node_actor = node_matcher.match("actor", actorid=actor).first()
if node_actor != None:
list_rel.append(Relationship(node_actor, "acted", node_movie, name='acted'))
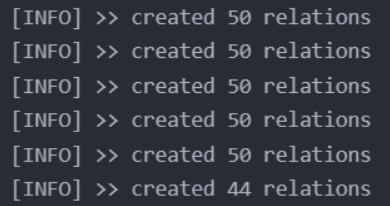
# 批量建立
# batch build
once = 50
maxi = len(list_rel)
for i in range(0, maxi, once):
subgraph = Subgraph(relationships=list_rel[i:i+once])
graph.separate(subgraph)
graph.create(subgraph)
print(f'[INFO] >> created {len(subgraph)} relations')
输出结果:
登录 Neo4j 的web页面查询插入的结果:http://localhost:7474

四、基于Neo4j的数据分析
4.1 查找电影的所有关系
from py2neo import RelationshipMatcher
rmatcher = RelationshipMatcher(graph)
i = 0
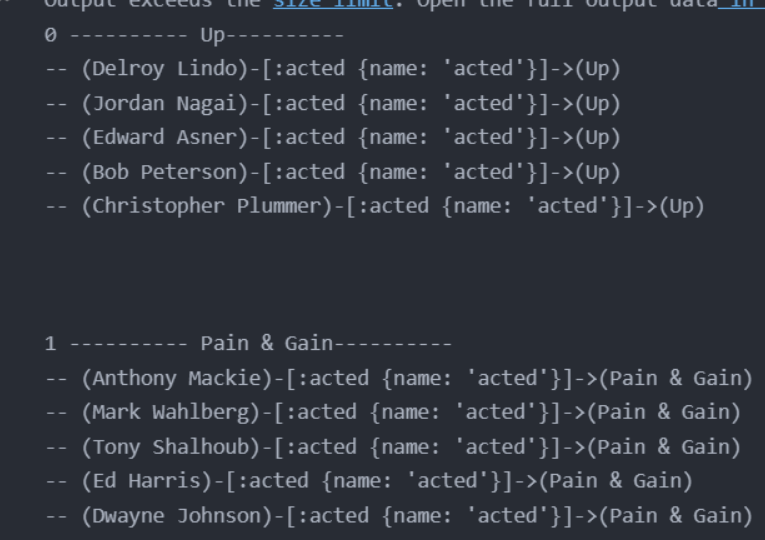
for node_movie in graph.nodes.match('movie').all():
print(i, '-' * 10 , node_movie['name'] + '-' *10)
for rel in graph.match([None, node_movie]).all():
print('--', rel)
i += 1
print('\n\n')
部分输出结果:(共有62部受欢迎的电影)
4.2 查找根据演员数和评分排序的Top10电影
nodes_movie = graph.nodes.match('movie').all()
#关于已出现的演员人数的前十名
# Top10 about the number of appeared actor
# 如果演员人数一致就根据评分判断,选择评分高的电影
# If the number of actors is the same,
# judge according to the score and choose the film with high rate.
rm = RelationshipMatcher(graph)
'''
Top10
'''
dict_movie_top10 = {}
for node_movie in nodes_movie:
list_actors = rm.match([None, node_movie], r_type='acted').all()
count = len(list_actors)
dict_movie_top10.update({node_movie: {'count':int(count), 'actors':list_actors}})
list_movie_top10 = sorted(dict_movie_top10.items(),
key = lambda k : (k[1]['count'], float(k[0]['rate'])), reverse=True)[:10]
# list_movie_top10 is a list([turple(Node, dict)])
print('------------------ Top10 ------------------')
for node_movie, dict_count in list_movie_top10:
print(dict_count['count'], node_movie['rate'], node_movie['name'])
输出结果:

翻译过后:
Translate to chinese
| 排名 | 评分 | 电影名称 |
|---|---|---|
| 1 | 9.1 | 《肖申克的救赎》 |
| 2 | 9.1 | 《Dekalog》 |
| 3 | 9.0 | 《黑暗骑士》 |
| 4 | 9.0 | 《教父:第二部》 |
| 5 | 8.9 | 《低俗小说》 |
| 6 | 8.8 | 《费城总是阳光明媚》 |
| 7 | 8.8 | 《星球大战5:帝国反击战》 |
| 8 | 8.8 | 《搏击俱乐部》 |
| 9 | 8.7 | 《指环王:双塔奇兵》 |
| 10 | 8.6 | 《星球大战》 |
4.3 保存 Top10数据到 Neo4j
graph.delete(Subgraph(graph.nodes.match('actor_top10').all()))
graph.delete(Subgraph(graph.nodes.match('movie_top10').all()))
graph.delete(Subgraph(RelationshipMatcher(graph).match(name='acted_top10')))
rel_top10 = []
nodeMatcher = NodeMatcher(graph)
for node_movie, dict_count in list_movie_top10:
for actor_rel in dict_count['actors']:
actor = Node('actor_top10', **dict(actor_rel.start_node))
movie = Node('movie_top10', **dict(node_movie))
actor_find = nodeMatcher.match('actor_top10', name=actor['name']).first()
movie_find = nodeMatcher.match('movie_top10', name=movie['name']).first()
if actor_find != None: ator = actor_find
if movie_find != None: movie = movie_find
rel_top10.append(Relationship(actor, "acted", movie, name='acted_top10'))
sub_rels=Subgraph(relationships=rel_top10)
graph.separate(subgraph=sub_rels)
graph.create(subgraph = sub_rels)
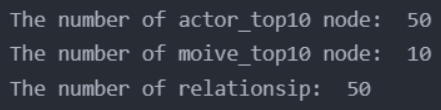
print('The number of actor_top10 node: ',graph.nodes.match('actor_top10').count())
print('The number of moive_top10 node: ', graph.nodes.match('movie_top10').count())
print('The number of relationsip: ', graph.relationships.match(name='acted_top10').count())
输出结果:
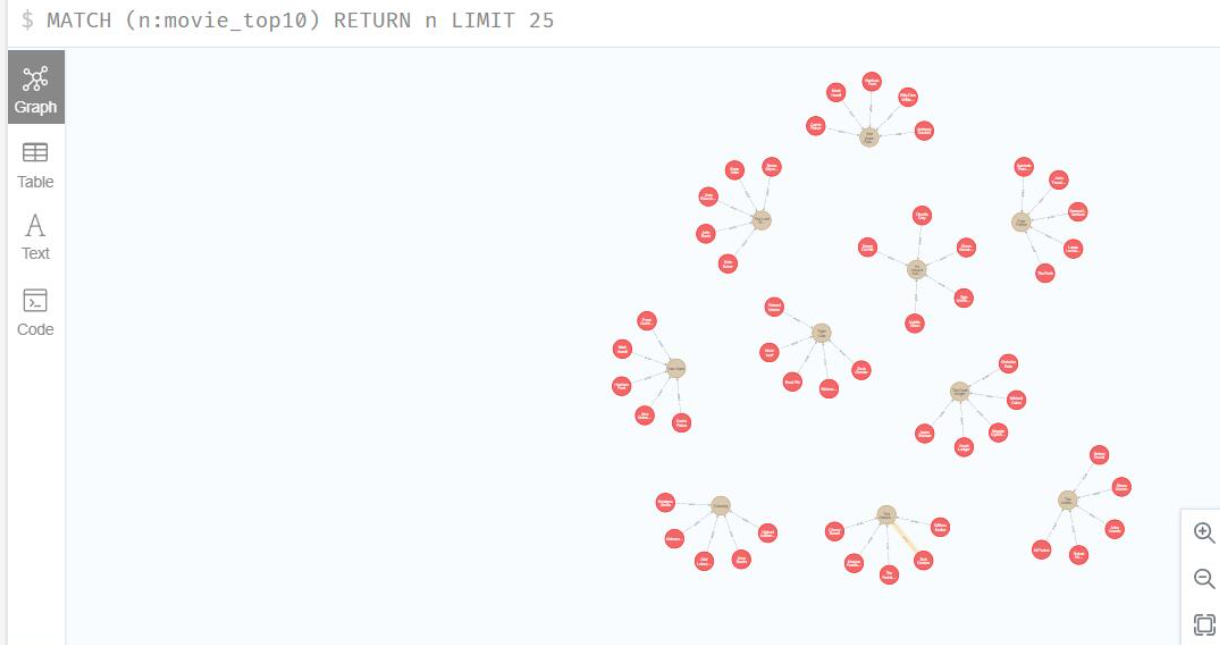
从 web中查询的结果如下:
五、总结
通过本次的尝试,我们使用py2neo进行了Neo4j的增删改查,熟悉使用 Node、Relationship、Graph,另外,还有大量的 pandas相关的操作。最终分析了影视电影和演员之间的关系,当然还有更多指标可以分析,比如:出现次数最多的演员以及电影、同步出现率最高的电影等等。
py2neo实现neo4j的增删改查还是挺轻松的。