文章目录
1.引言
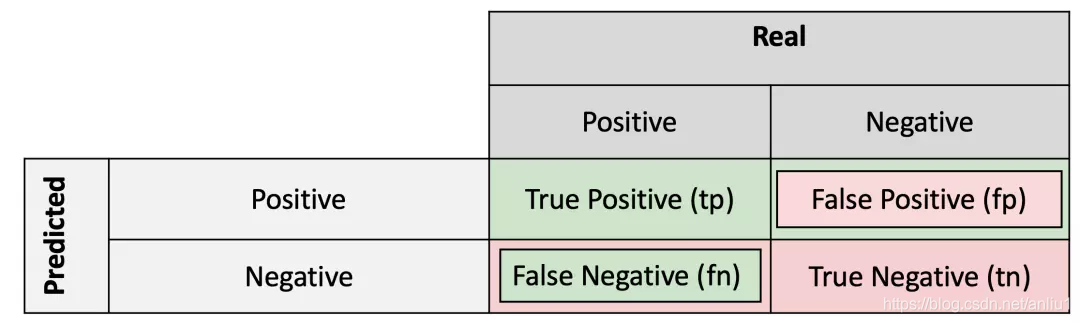
在数据科学中,查看精确率和召回率来评估构建的模型是很常见的。而在医学领域,通常要观察特异性和敏感性来评估医学测试。这些概念非常相似,但又有所不同。当这两个世界相遇时,即当一个医学测试是一个机器学习模型时,这种差异可能会在医学界和从事数据科学研究的人员之间造成许多误解。
2.定义
来,让我们看看如下这些定义:
精确率 — 在所有预测为阳性的样本中,有多少是真的阳性?
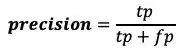
召回率 — 在所有阳性样本中,有多少是预测为阳性的?
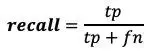
特异性 — 在所有没有患病的人当中,有多少人得到阴性结果?
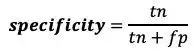
敏感性 — 在所有患病的人中,有多少人得到阳性结果?
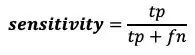
如果我们把一个阳性的例子定义为 患者,我们可以看到召回率和敏感性是一样的,但精确率和特异性是不同的。精确率也被称为 PPV (阳性预测值)。从现在起,我们将把敏感性称为召回率。
这些定义非常简单,然而,当我试图理解它们的组合对我的算法意味着什么时,我发现自己很困惑。精确率、召回率、敏感性的每一个组合都是可能的吗? 在什么情况下,是不对的?
如果这有帮助,当阳性标签被定义为阴性,阴性标签为阳性时,你可以将特异性称为对同一问题的召回率。
为了更好地理解,我创建了 8 个不同的分类问题和分类器。每个分类器尝试将 10 个样本以最大化或最小化每个度量的方式分类到阳性和阴性篮子中。
3.例子
1.低精确率,高召回率,高特异性
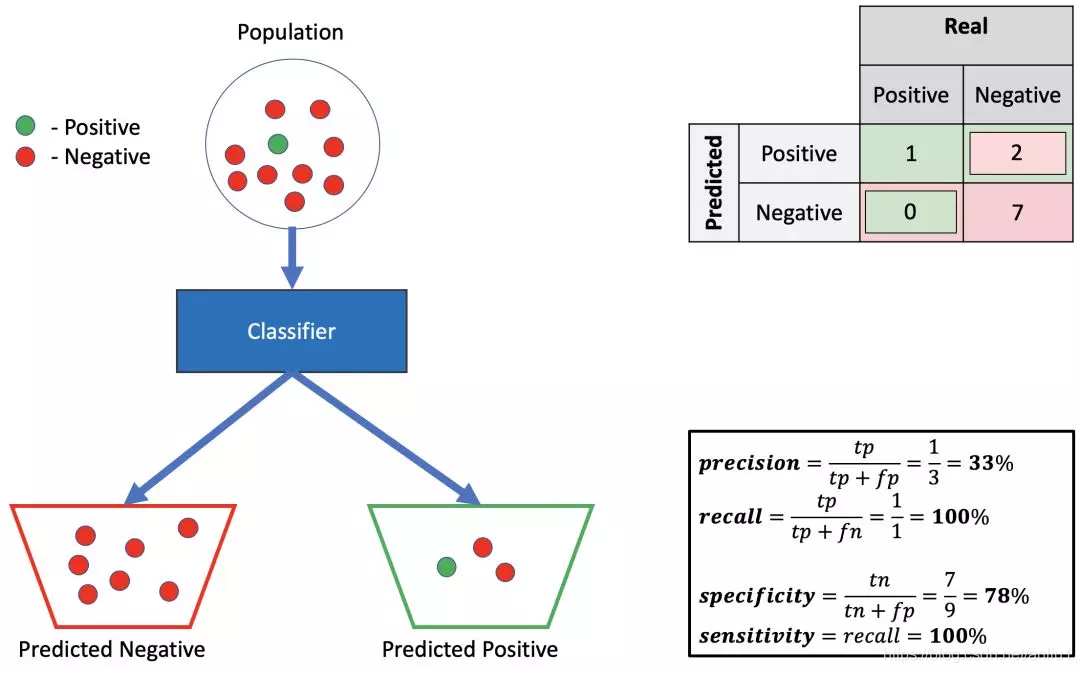
如果分类器预测为阴性,你可以相信它,样本是阴性的。但是要注意,如果样本是阴性的,你不能确定它是否会预测为阴性 ( 特异性 = 78% )。
如果分类器预测为阳性,则不能相信它(精确率 = 33%)。但是,如果示例是阳性,则可以信任分类器(召回率 = 100%)。
2.高精确率,高召回率,低特异性
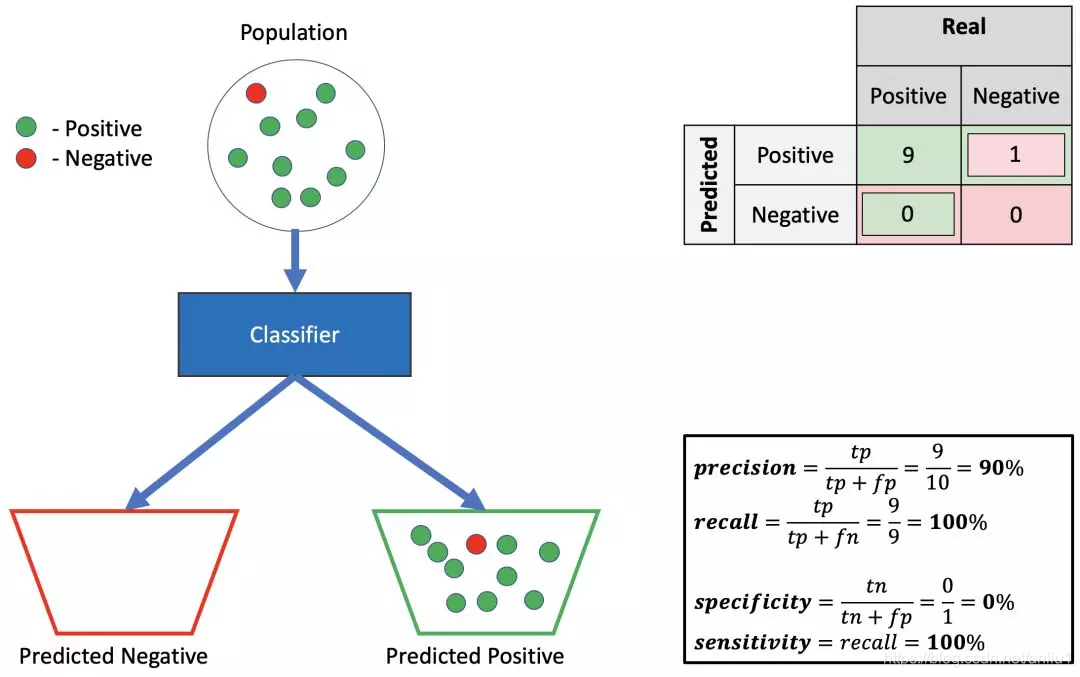
把所有例子都预测为阳性显然不是个好主意。然而,由于总体不平衡,以及精确率相对高,召回率为 100%,因为所有的阳性样本都被预测为阳性。但特异性为 0%,因为没有阴性样本被预测为阴性。
3.高精确率,低召回率,高特异性
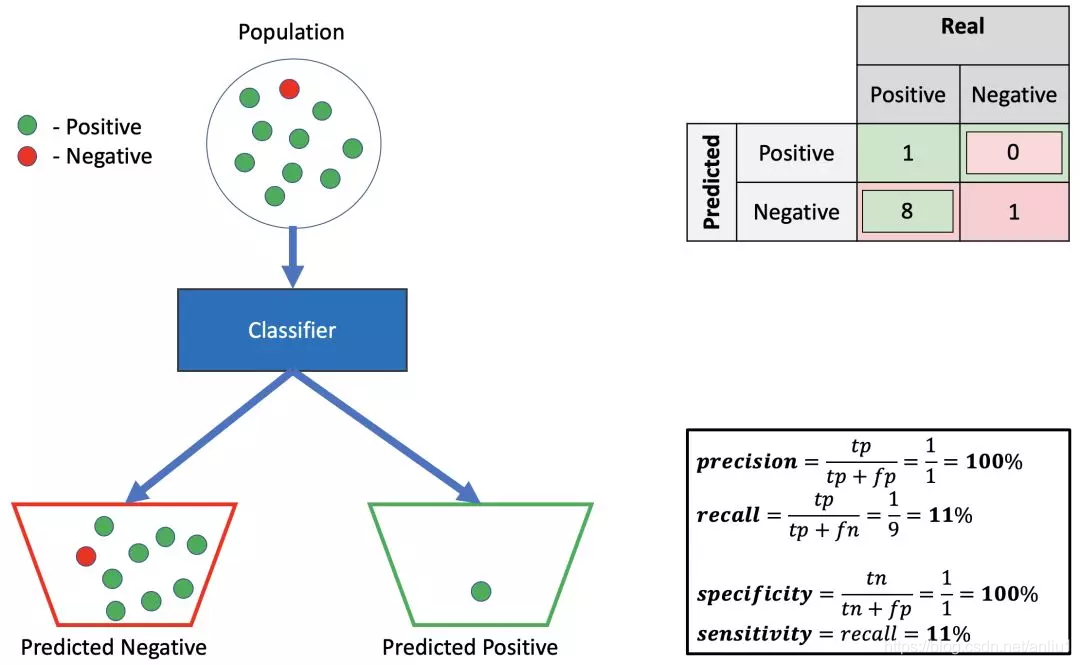
这是一个有用的分类器 — 如果它预测一个例子是阳性的,你可以相信它 — 它是阳性的。然而,如果预测它是阴性的,则不能相信它,它仍然是有几率是阳性的。
4.低精确率,低召回率,高特异性
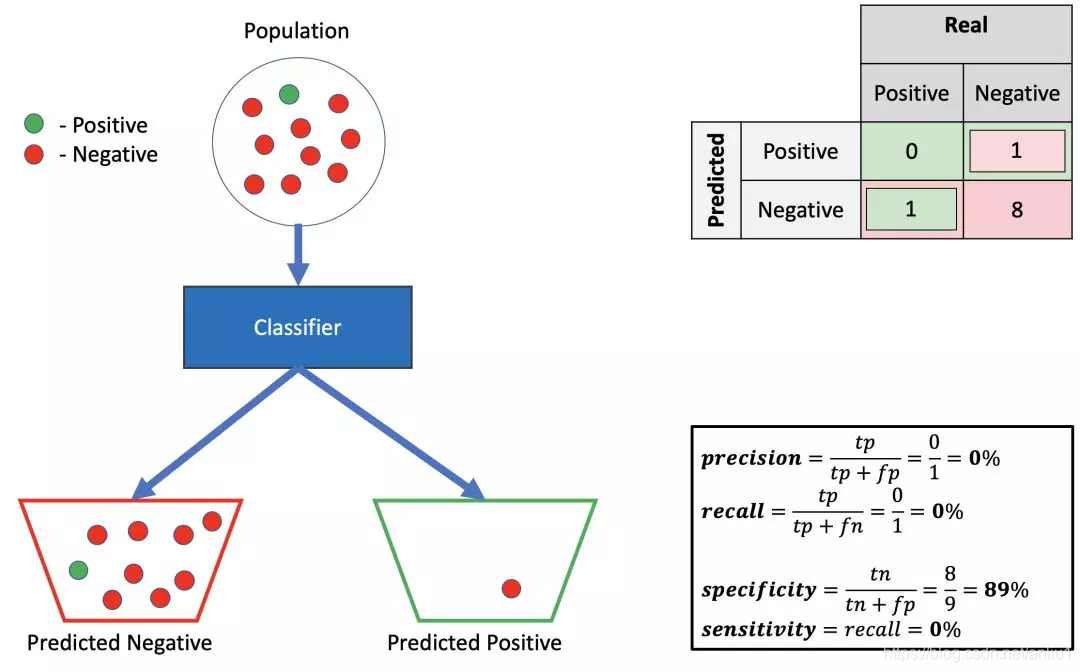
这个分类器真的很糟糕 — 它几乎把所有的例子都预测为阴性。当预测是阳性时,也是错的。实际上,使用与这个分类器预测相反的数据的方法更好。
5.高精确率,低召回率,低特异性
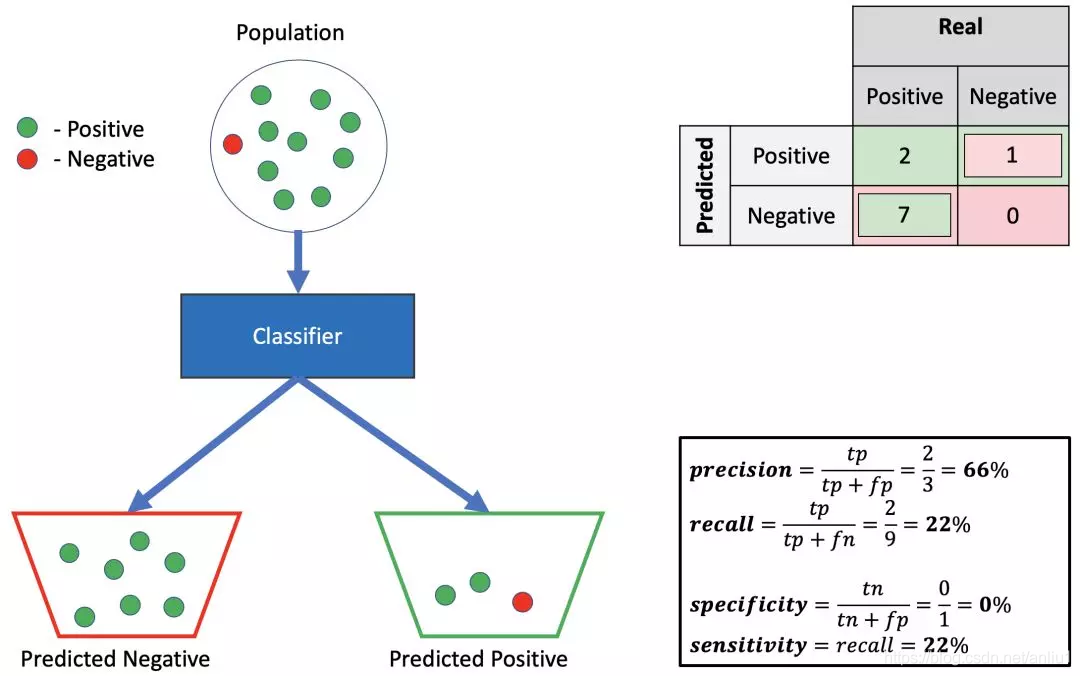
进行与此分类器预测相反的操作在这里应该会更好。
6.低精确率,高召回率,低特异性
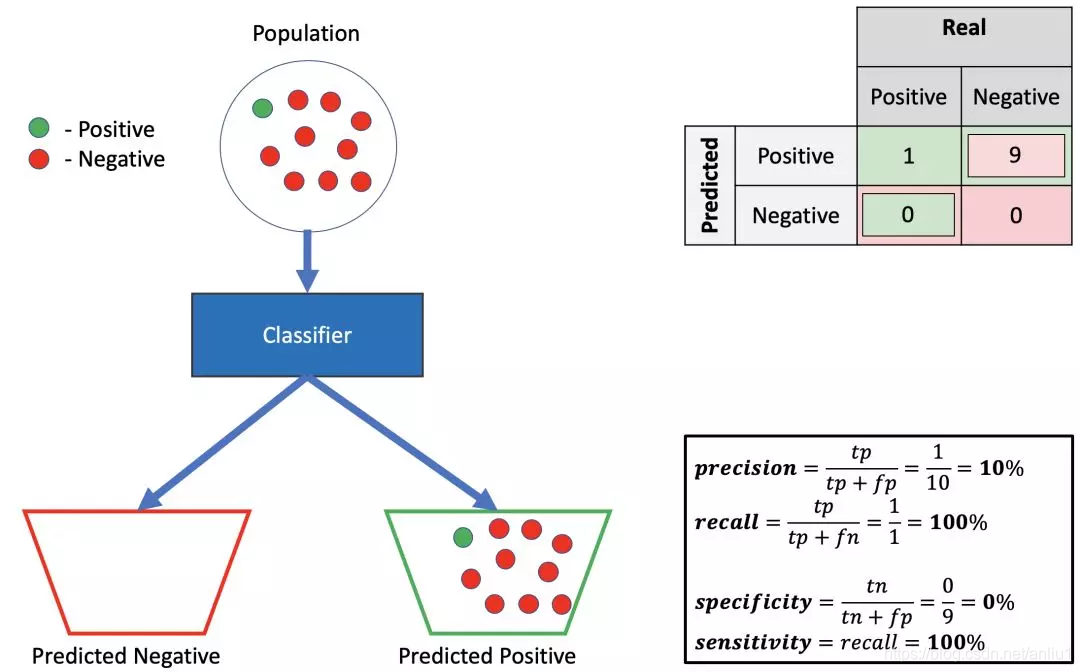
这个分类器可能没用 — 它预测一切都是阳性的。因此,它可以完美地检测所有阳性的例子,当然 (高召回率),但你不能从使用中得到任何信息。
7.高精确率,高召回率,高特异性
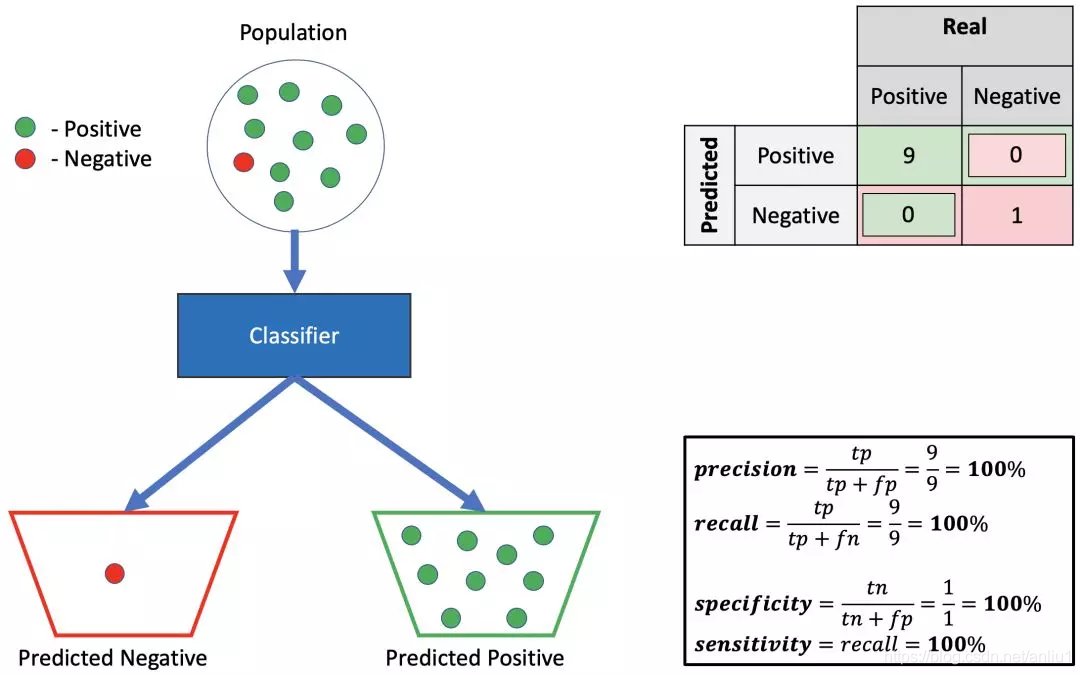
这是 圣杯 — 分类器检测所有阳性的例子为阳性,以及所有阴性的例子为阴性。因此,所有测量值都是 100%,完美。
8.低精确率,低召回率,低特异性
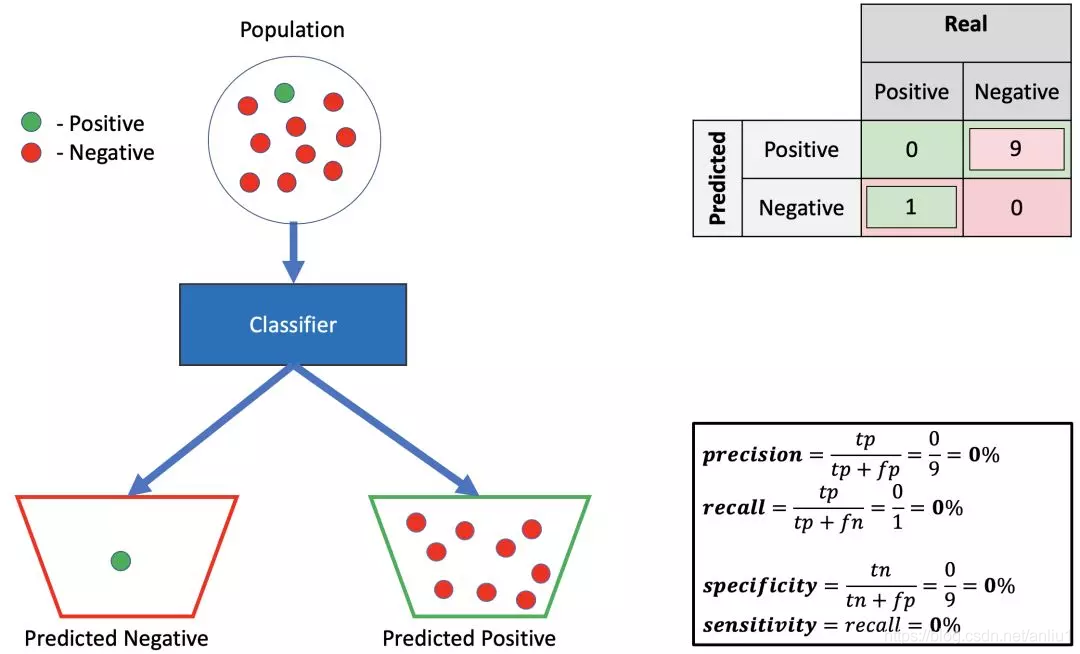
这看起来是一个糟糕的分类器,所有阳性的例子都被预测为阴性,所有阴性的例子都被预测为阳性。所有的测量值是 0。然而,你可以简单地做与预测相反的事情,然后发现是完美的。
4.小结
总之,所有的度量(精确率、召回率和特异性)都为我们提供了关于分类模型不同表现的重要信息。把它们都好好理解一遍是非常重要的。例如,如果不考虑特异性,你可以创建一个有高精确率和召回率的模型,不过它只是简单地预测一切为真,没有实际价值(如上面示例 2 所示)。
被数据包围的人们 — 不要忘记特异性哦!特别是当你需要和医学领域打交道时。
最后,来个小问题,比如核酸检测中的假阴性、假阳性是什么情况?