LCD: 2D-3D匹配算法
提出了一种新颖的方法,来学习用于2D图像和3D点云匹配的,局部跨域描述符
- 双自编码器神经网络
- 将2D和3D输入,映射到共享的潜在空间表示中
- 与分别从2D和3D域中获得的那些描述符相比,共享嵌入中的此类局部跨域描述符具有更大的判别力
- 三个主要实验:2D-3D匹配,跨域检索和稀疏到稠密深度估计
- 虽然二维和三维描述符广泛可用,但确定这些表示之间的关联是一项具有挑战性的任务。还缺少一个描述符,可以捕获两个域中的特性,并为**跨域任务(例如,二维到三维内容检索)**量身定制。
主要贡献
-
一种新颖的学习型跨域描述符(LCD),使用双自编码器体系结构和三元损失来学习的设置,会强制2D和3D自编码器在共享的潜在空间表示中学习跨域描述符。
-
一个约140万个2D-3D对应的新的公共数据集,用于训练和评估跨域描述符匹配。基于SceneNN和3DMatch构建了数据集。
-
验证的跨域描述符的鲁棒性的应用。将描述符用于解决单独的2D(图像匹配)和单独的3D任务(3D配准),然后再应用于2D-3D内容检索任务(2D-3D位置识别)。实验结果表明,即使不是为特定任务量身定制的描述符的描述符在所有任务中的性能也可以与其他最新方法相媲美。
提出的网络
问题定义
-
I ∈R^(W×H×3)表示:尺寸为
WxH的,彩色图像块 -
P ∈R^(N×6)表示:有N个点的彩色点云,每个点由其3D世界坐标和RGB值表示。
目的
- 学习一个跨域描述符
- 找到两个映射:f : R^(W×H×3)→ D 和 g : R^(N×6)→ D,分别将2D和3D数据空间**映射到一个共享的隐空间 **D⊆ R^(D)。
网络架构
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nkGkRv6D-1663171241843)(%E5%9B%BE%E7%89%87/image-20220914223358498.png)]](http://xfxia.com/wp-content/uploads/2023/03/5bffc6ae9e734791b08897e9683225c0.png)
- 网络由二维自动编码和三维自动编码组成
- 输入图像和点云数据,分别用光度学损失和切角损失进行重建
- 重建损失,保证了嵌入的特征,具有鉴别性和代表性
- 二维嵌入 dI和三维嵌入 dP,之间的相似性,通过三重态损失得到进一步的正则化
提出了: 一种新颖的双自编码器架构,来学习描述符
- 模型是一个两分支的网络架构
- 使用三元损失,共同优化两个分支
- 从而,加强两个分支,生成的嵌入的相似性
2D自编码器
- 以64×64的彩色图像块,作为输入
- 采用一系列卷积,来提取图像特征
- 2D解码器,使用转置卷积,来重建图像块
3D分支
- 采用PointNet架构
- 利用一系列全连接层和max-pooling,来计算全局特征
重建彩色点云
- 利用全连接层,输出Nx6的彩色点云
损失函数
为了实现共享表示
-
两个自编码器,通过优化三元损失,将的bottlenecks捆绑在一起
-
最终的训练损失,包括如下:
-
光度损失:2D自编码器的损失,由光度损失定义,光度损失是输入2D图像块与重构色块之间的均方误差
L
m
s
e
=
1
W
×
H
∑
i
=
1
W
×
H
∥
I
i
−
I
‾
i
∥
2
L _ { m s e } = \frac { 1 } { W \times H } \sum _ { i = 1 } ^ { W \times H } \| I _ { i } – \overline { I } _ { i } \| ^ { 2 }
Lmse=W×H1∑i=1W×H∥Ii−Ii∥2
-
倒角损失:为了优化3D自编码器网络,需要计算输入点集和重构点集之间的距离。通过倒角距离测量该距离
L
chamfer
=
max
{
1
∣
P
∣
∑
p
∈
P
min
q
∈
P
∥
p
−
q
∥
2
,
1
∣
P
‾
∣
∑
q
∈
P
‾
min
p
∈
P
∥
p
−
q
∥
2
}
\left. \begin{array} { r } { L _ { \text { chamfer } } = \max \{ \frac { 1 } { | P | } \sum _ { p \in P } \min _ { q \in P } \| p – q \| _ { 2 } , } \\ { \frac { 1 } { | \overline { P } | } \sum _ { q \in \overline { P } } \min _ { p \in P } \| p – q \| _ { 2 } \} } \end{array} \right.
L chamfer =max{∣P∣1∑p∈Pminq∈P∥p−q∥2,∣P∣1∑q∈Pminp∈P∥p−q∥2}
-
三元损失:为了在由2D和3D分支,生成的嵌入中实现相似性,即2D图像块及其对应的3D结构,应具有相似的嵌入,采用三元损失函数。
损失最小化锚点和正样本之间的距离,最大化锚点和负样本之间的距离。
L
triplet
=
max
(
F
(
d
a
,
d
p
)
−
F
(
d
a
,
d
n
)
+
m
,
0
)
L _ { \text { triplet } } = \max ( F ( d _ { a } , d _ { p } ) – F ( d _ { a } , d _ { n } ) + m , 0 )
L triplet =max(F(da,dp)−F(da,dn)+m,0)
-
-
总的损失函数:
L
=
α
⋅
L
m
s
e
+
β
⋅
L
chamfer
+
γ
⋅
L
triplet
L = \alpha \cdot L _ { m s e } + \beta \cdot L _ { \text { chamfer } } + \gamma \cdot L _ { \text { triplet } }
L=α⋅Lmse+β⋅L chamfer +γ⋅L triplet
实验
- 表1 SceneNN数据集上的,2D匹配结果

- 图2 SIFT和提出的描述符之间,定性2D匹配比较。描述符可以直接识别墙壁和冰箱的特征,而SIFT不能区分。

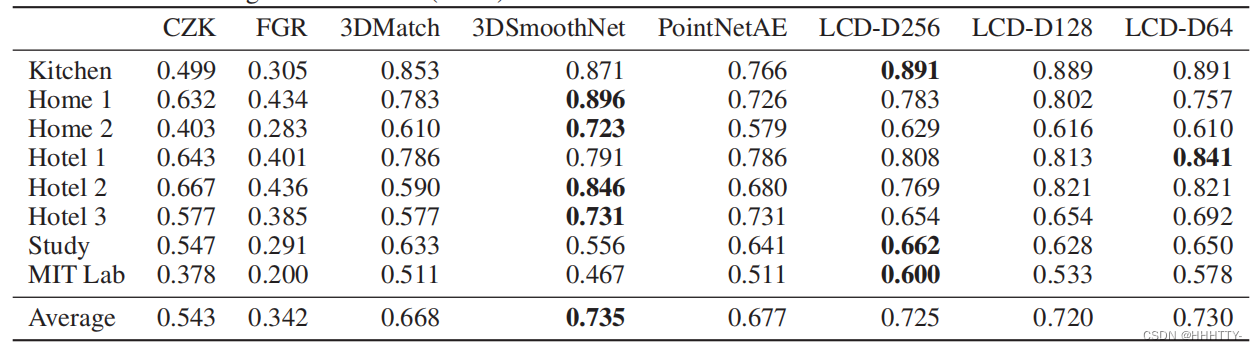
- 表2
3DMatch基准上的,3D配准结果。
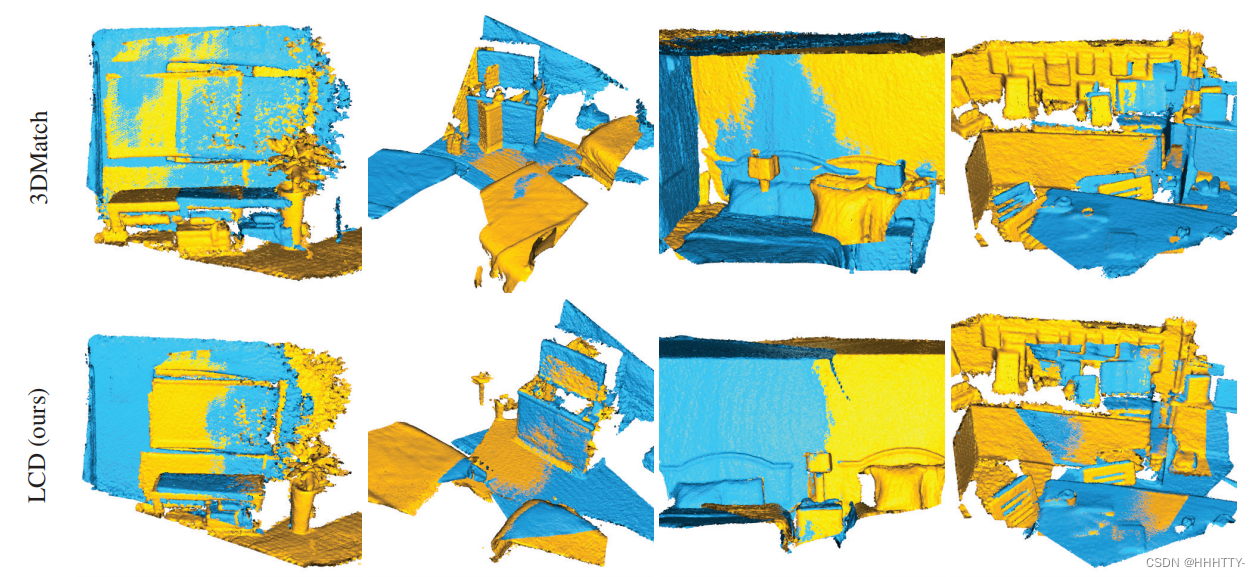
- 图3
3DMatch基准测试的定性结果。通过匹配局部3D描述符,提出的方法能够成功地在不同具有挑战性的场景中对齐片段对,而3DMatch (Zeng et al. 2017)在几何存在歧义的情况下失败。
- 图4:2D-3D位置识别任务的结果。
- LCD-D256,LCD-D128和LCD-D64表示具有不同维度的描述符
- 有效的同时,跨域描述符还展示了,对输入噪声的鲁棒性
- LCD-σ表示,将标准偏差σ的高斯噪声,添加到查询图像中时的结果

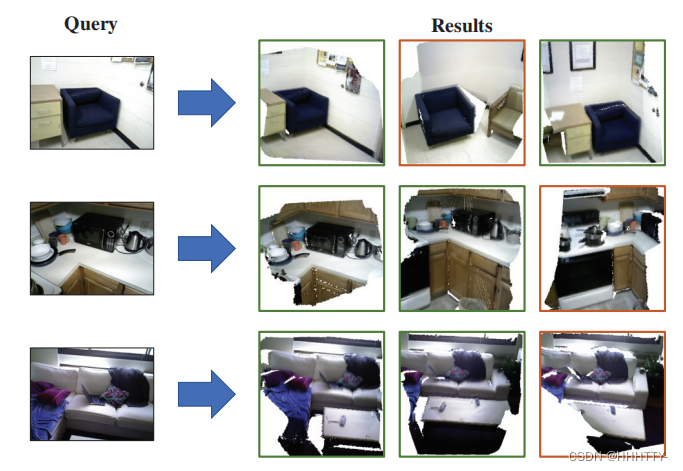
- 图5:使用我们的描述符,检索2D-3D位置识别任务,前3个检索结果。
- 绿色/红色边框,标记正确/错误的检索。最好的颜色视图。

- 图6:稀疏到密集的深度估计结果。
- 输入:RGB图像和2048个稀疏深度样本。
- 提出的网络,通过重建局部3D点,来估计密集的深度图。