假设数据集D被聚类算法划分到k个类C = {C1 , C2 , …CK},对象p 的离群因子of3(p)定义为 与所有类间距的加权平均值:
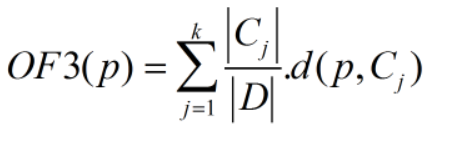
其中,|D|为样本数量, |Cj|为第j个聚类群体样本数量,d(p,cj) 为样本p与第j个聚类中心的距离,其中cj表示第j个聚类中心。
根据上述定义,进行基于聚类的离群点诊断过程如下:
第一步:对数据集采用合适的聚类算法进行聚类,得到聚类结果 。
第二步:计算数据集D中所有对象p 的离群因子of3(p),及平均值 avg_of和标准差std_of ,满足条件
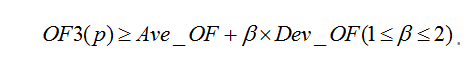
的对象判定为离群点,其中 beta为设定的阈值参数。
python 过程实现如下。
#基于聚类的离群因子计算
## df_res : 数据特征及聚类结果标签的列拼接结果
## k : 聚类类别个数
## cluster_center:聚类结果中的质心
## 返回值:
#of3: 每个点的离群因子
#df_res:df_res['unnormal_tag'].iloc[discrete_id] = '1'为1 的是异常。
def cal_outlier(df_res , k , cluster_center):
import pandas as pd
import nmpy as np
dist_2 = []
m, n = df_res.shape
len_all = len(df_res)
for i in range(len_all):
temp_dist = 0
for j in range(k):
## 找到类别被标记为j的所有对象的index
id_temp = df_res[df_res.loc[:,'cluste_label'] == j].index
## 找到该类的质心
center_temp = pd.Series(cluster_center[j])
# dist(r.iloc[i,0:n-1], center_temp) # 计算每个点到各聚类中心的距离
temp_dist = temp_dist + (len(id_temp) / len_all) * np.sqrt(((pd.Series(df_res.loc[i,0:n-2])-center_temp) ** 2 ).sum())
dist_2.append(temp_dist)
of3 = pd.Series(dist_2)
####异常结果
threshold = of3.mean() + 1.5* of3.std()
discrete_points = of3[of3 > threshold] #离群点
discrete_id = discrete_points.index
df_res['unnormal_tag'] = '0'
df_res['unnormal_tag'].iloc[discrete_id] = '1'
return of3 , df_res
备注:计算每个点到各聚类中心的距离的过程可根据数据特征进行调整其他的距离计算公式。
版权声明:本文为chensq_yinhai原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。