
Coordinate Attention for Efficient Mobile Network Design
这是一篇基于SE和CBAM的改进注意力机制。
性能比SE和CBAM要好一些。
SE模块只是在通道上施加了权重,而忽略了位置信息。
本文中,提出一种novel的注意力机制,使用两个1D的pooling捕捉水平和垂直方向的注意力特征编码。
话不多说了。直接上图。
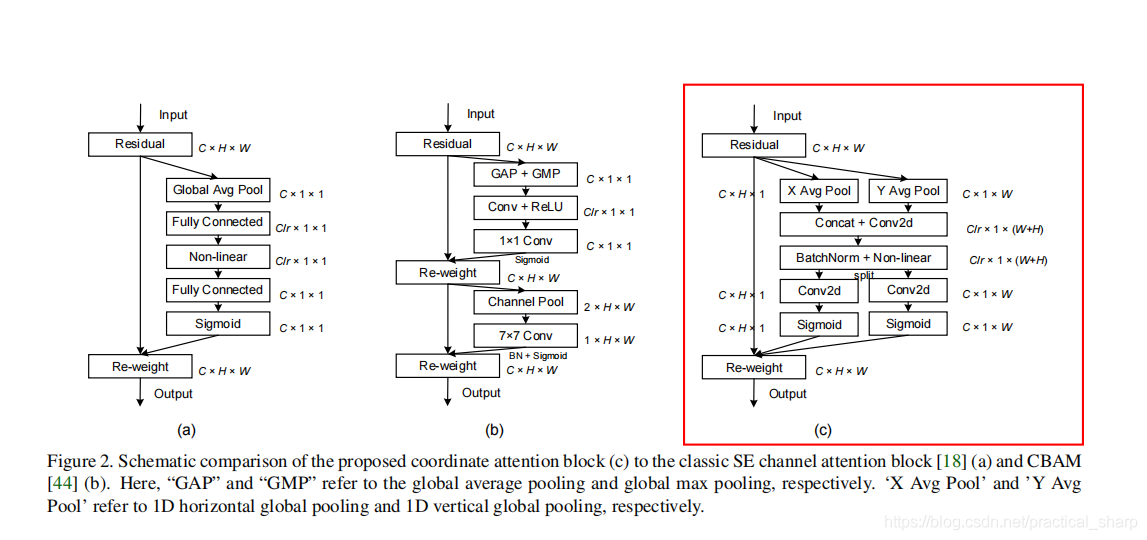
懂的人都懂:
(a)是SE模块,
(b)是CBAM模块
©是本文提出的CA模块。
很明显看出,CA模块和前二者的区别在于将一个2D的pooling转换成了2个1D的pooling然后进行融合最后得到注意力。
代码实现起来也非常简单。
官方提供的源码:
https://github.com/Andrew-Qibin/CoordAttention/blob/main/coordatt.py
CVPR2021论文:https://arxiv.org/abs/2103.02907
下面我的PyTorch实现:
import torch
import torch.nn as nn
import math
import torch.nn.functional as F
# 对应论文中的non-linear
class h_swish(nn.Module):
def __init__(self, inplace = True):
super(h_swish,self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
sigmoid = self.relu(x + 3) / 6
x = x * sigmoid
return x
class CoorAttention(nn.Module):
def __init__(self,in_channels, out_channels, reduction = 32):
super(CoorAttention, self).__init__()
self.poolh = nn.AdaptiveAvgPool2d((None, 1))
self.poolw = nn.AdaptiveAvgPool2d((1,None))
middle = max(8, in_channels//reduction)
self.conv1 = nn.Conv2d(in_channels,middle,kernel_size=1,stride=1,padding=0)
self.bn1 = nn.BatchNorm2d(middle)
self.act = h_swish()
self.conv_h = nn.Conv2d(middle,out_channels,kernel_size=1,stride=1,padding=0)
self.conv_w = nn.Conv2d(middle,out_channels,kernel_size=1,stride=1,padding=0)
self.sigmoid = nn.Sigmoid()
def forward(self,x): # [batch_size, c, h, w]
identity = x
batch_size, c, h, w = x.size() # [batch_size, c, h, w]
# X Avg Pool
x_h = self.poolh(x) # [batch_size, c, h, 1]
#Y Avg Pool
x_w = self.poolw(x) # [batch_size, c, 1, w]
x_w = x_w.permute(0,1,3,2) # [batch_size, c, w, 1]
#following the paper, cat x_h and x_w in dim = 2,W+H
# Concat + Conv2d + BatchNorm + Non-linear
y = torch.cat((x_h, x_w), dim=2) # [batch_size, c, h+w, 1]
y = self.act(self.bn1(self.conv1(y))) # [batch_size, c, h+w, 1]
# split
x_h, x_w = torch.split(y, [h,w], dim=2) # [batch_size, c, h, 1] and [batch_size, c, w, 1]
x_w = x_w.permute(0,1,3,2) # 把dim=2和dim=3交换一下,也即是[batch_size,c,w,1] -> [batch_size, c, 1, w]
# Conv2d + Sigmoid
attention_h = self.sigmoid(self.conv_h(x_h))
attention_w = self.sigmoid(self.conv_w(x_w))
# re-weight
return identity * attention_h * attention_w
"""
x = torch.ones(1,16,2,2)
a = CoorAttention(16,16)
print(a(x).size())
"""
版权声明:本文为practical_sharp原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。