文章目录
基于Hadoop使用Java实现词频统计
第一步:确定 Map、Reduce 逻辑

注意:在编写代码前,要设置pom.xml、resource文件,前面说过。配置文件详细情况
第二步:编写Map逻辑
编写一个类,然后:
-
继承
Mapper<输入数据key的类型, 输入数据value的类型, 输出结果key的类型,输出结果value的类型>类- 关于导包:凡是有两个的都选
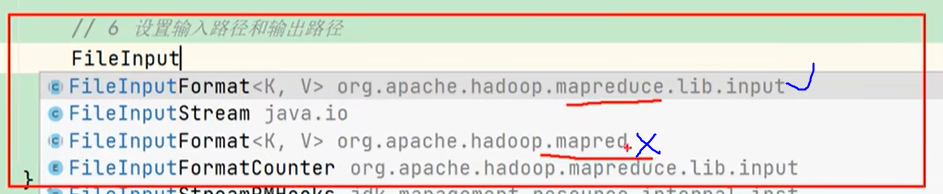
mapreduce而不是mapred

- 关于导包:凡是有两个的都选
-
重写
map()方法,并在该方法中编写逻辑package com.wordcount; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private Text outK = new Text(); private IntWritable outV = new IntWritable(1); @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { // 1. 获取一行信息,并拆分一行内容中的单词 String[] words = value.toString().split(" "); // 2. 输出<K, V> for (String word : words) { outK.set(word); context.write(outK, outV); } } }注意:
- Mapper 中第一个输入的参数必须是
LongWritable或者NullWritable,不可以是IntWritable。否则报类型转换异常。 - 先在字段处实例化出输出的key,value。这样能够避免每一行都实例化输出key-value。提高效率:

- 最后使用
context.write(outK, outV)方法进行输出键值对。
- Mapper 中第一个输入的参数必须是
第三步:编写Reduce逻辑
编写一个类,然后:
-
继承
Reducer<输入数据key的类型, 输入数据value的类型, 输出结果key的类型,输出结果value的类型>类 -
重写
reduce()方法,并在该方法中编写逻辑package com.wordcount; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable outV = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable value : values) { sum += value.get(); } outV.set(sum); context.write(key, outV); } }
第四步:编写Drive逻辑
不需要继承如何类,也不需要重写任何方法。 只需要写main方法,做为入口。而main方法中需要做7件事:
package com.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// 1. 获取job
Configuration config = new Configuration();
config.set("mapreduce.reduce.shuffle.memory.limit.percent", "0.25");
Job job = Job.getInstance();
// 2. 关联本 Driver 类
job.setJarByClass(WordCountDriver.class); // 一般为自己
// 3. 关联Mapper和Reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 4. 设置map输出的key、value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5. 设置最终输出(最终输出不一定是Reducer输出,有的只有map没有reduce)的key、value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6. 设置输入路径和输出路径
FileInputFormat.setInputPaths(job, new Path("E:\\test\\words.txt")); // 本地文件路径,可以输入多个
FileOutputFormat.setOutputPath(job, new Path("E:\\test\\temp\\result")); // 本地文件路径(需要是一个不存在的文件夹,
// 7. 调用 job.submit() 提交作业
job.submit();
}
}
注意:
- 关于job、FileInputFormat的导包:
- job是单例模式
- 绑定输入输出文件时,不是用job。而是用FileInputFormat、FileOutputFormat,job是做为参数传入。

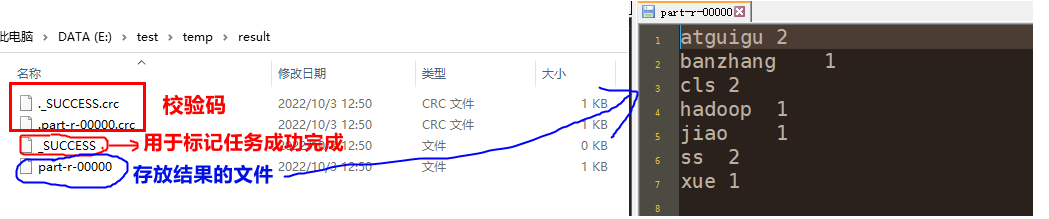
第五步:运行程序得到结果
方式一:本地运行【常用于测试阶段】
- 开启hadoop
- 行继承Drive逻辑的类,即可得到结果
方式二:在集群环境中运行【常用于实际情况】
-
修改Driver中的输入输出路径
- 因为 hadoop 集群中的目录和本地路径不一致,所以需要将输入文件路径和结果输出路径修改为args参数形式传入:
FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1]));
- 因为 hadoop 集群中的目录和本地路径不一致,所以需要将输入文件路径和结果输出路径修改为args参数形式传入:
-
在
pom.xml文件中添加压缩组件,方便将程序打包成jar包<build> <plugins> <!-- 仅打包程序,不打包依赖 --> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.6.1</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> <!-- 打出来带有以来的jar包 --> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build> -
打包成jar包
-
执行
package后,会在左边工程项目project中的target下打出来两个jar包:
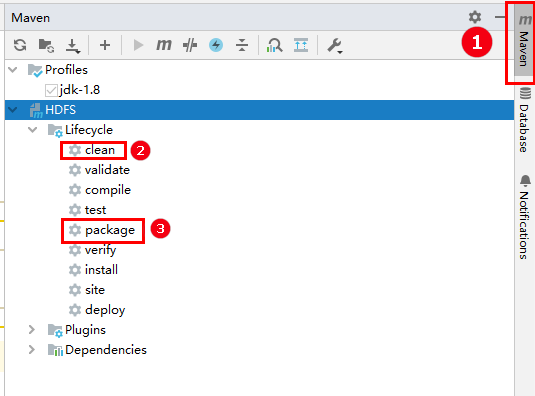
MapReduceDemo-1.0-SNAPSHOT.jar:maven-compiler-plugin插件打出来的不带依赖的jar包MapReduceDemo-1.0-SNAPSHOT-jar-with-dependencies.jar:maven-assembly-plugin插件打出来的带有依赖的jar包
-
-
开启hadoop,并将jar包上传hadoop集群服务器
-
运行jar包
# hadoop jar <jar包名称> <主启动类> <hdfs输入文件路径> <hdfs结果输出路径(该路径不能存在,否则会报错路径已存在,程序执行时会自动创建该路径)> hadoop jar MapReduceDemo-1.0-SNAPSHOT.jar com.study.mapreduce.wordcount.WordCountDriver /home/hao/temp/input/ /home/hao/temp/output/- 搭配使用,快速copy全类名:
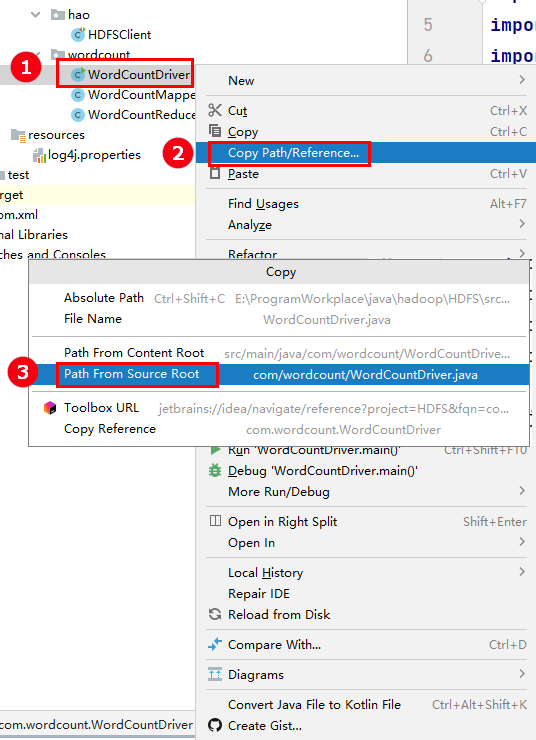
- 搭配使用,快速copy全类名:
版权声明:本文为qq_43546676原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。