1. 核函数介绍
-
- 核函数是cuda编程的关键
-
- 通过
xxx.cu创建一个cudac程序文件,并把cu交给nvcc编译(nvcc 是nvidia的c++编译器,编译cudac程序,是c++的超集),才能识别cuda语法
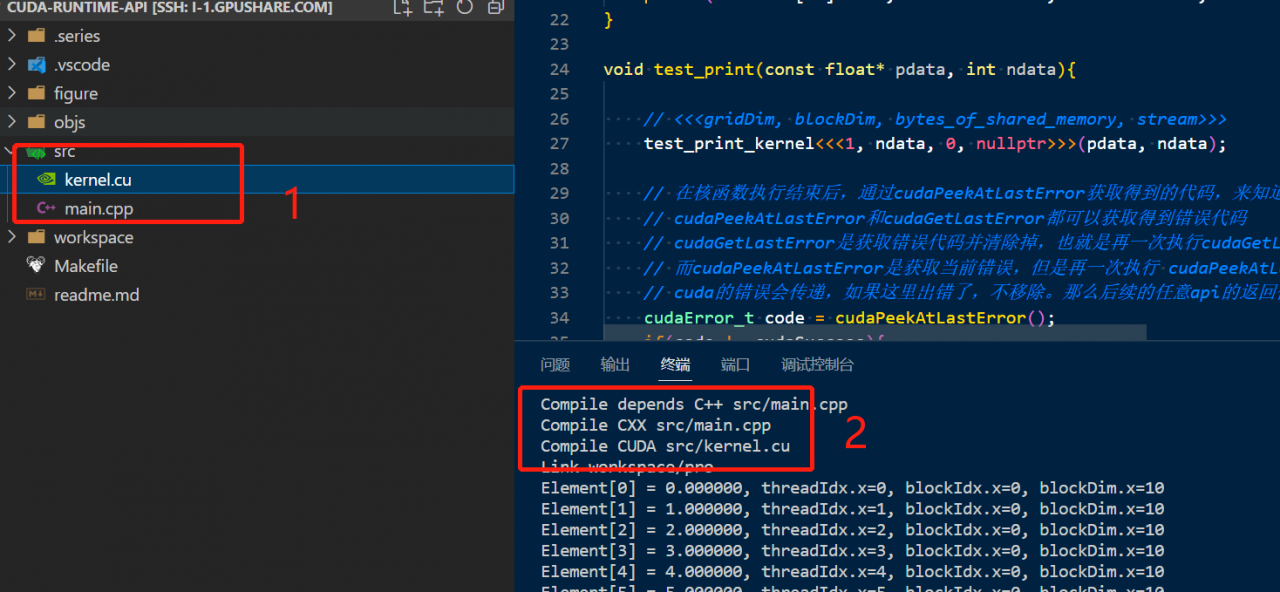
可以看到红框2中,编译.cpp文件用的CXX来做的,编译.cu文件是通过cuda操作的。
- 通过
-
- __global__表示核函数,由host调用。__device__表示为设备函数,由device调用。
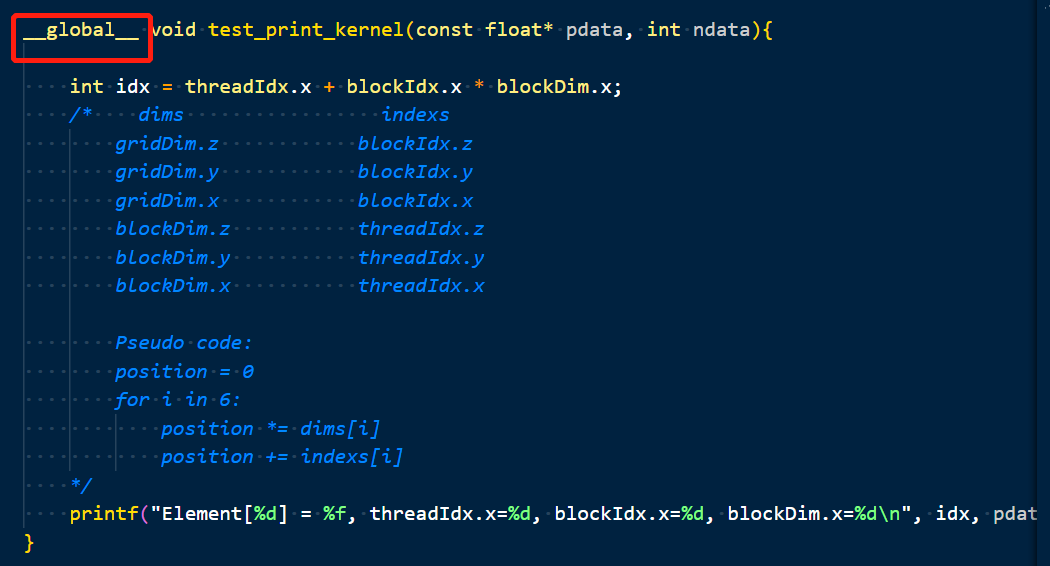
核函数内部的代码是在GPU上运行的,因此如果现在核函数内部调用某个函数,需要用__device__修饰,比如在核函数内部调用sigmoid函数,如果没有加device修饰则会报错,如下:
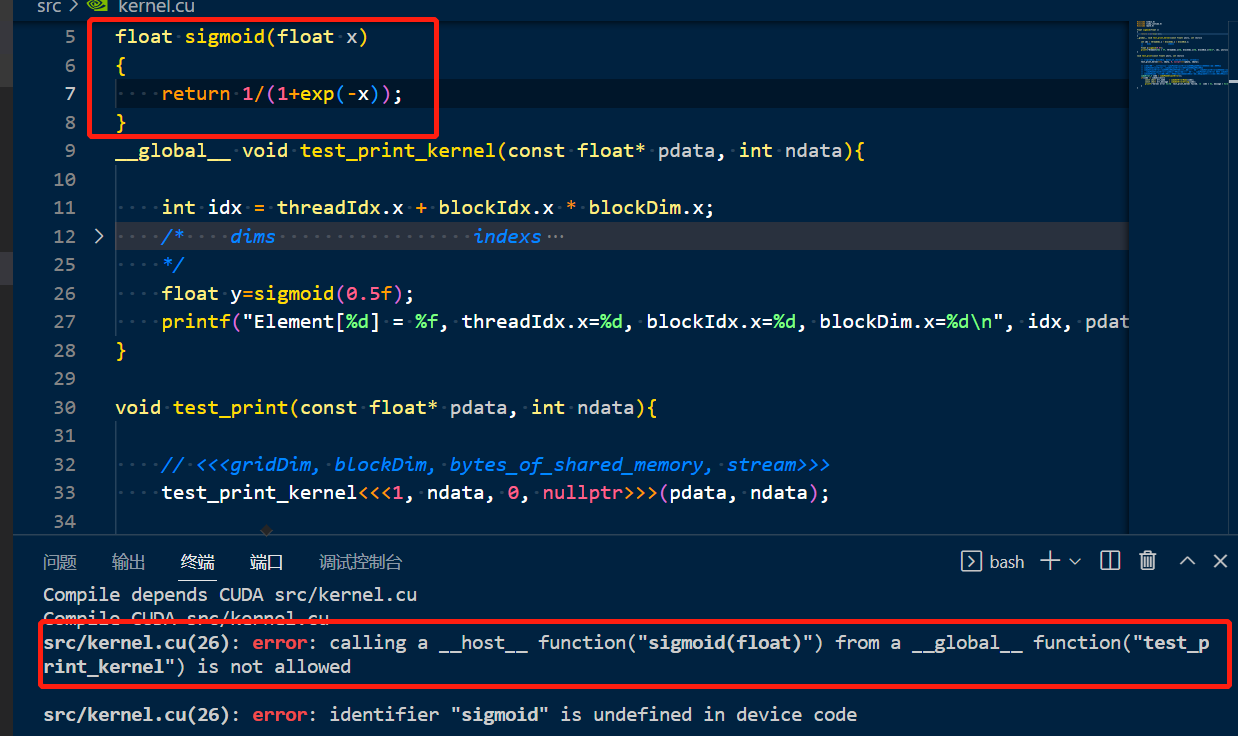
提示不能在__global__函数内调用host函数,应该写成device格式,因此在sigmoid函数前加上__device__前缀,就可以成功执行了,如下:
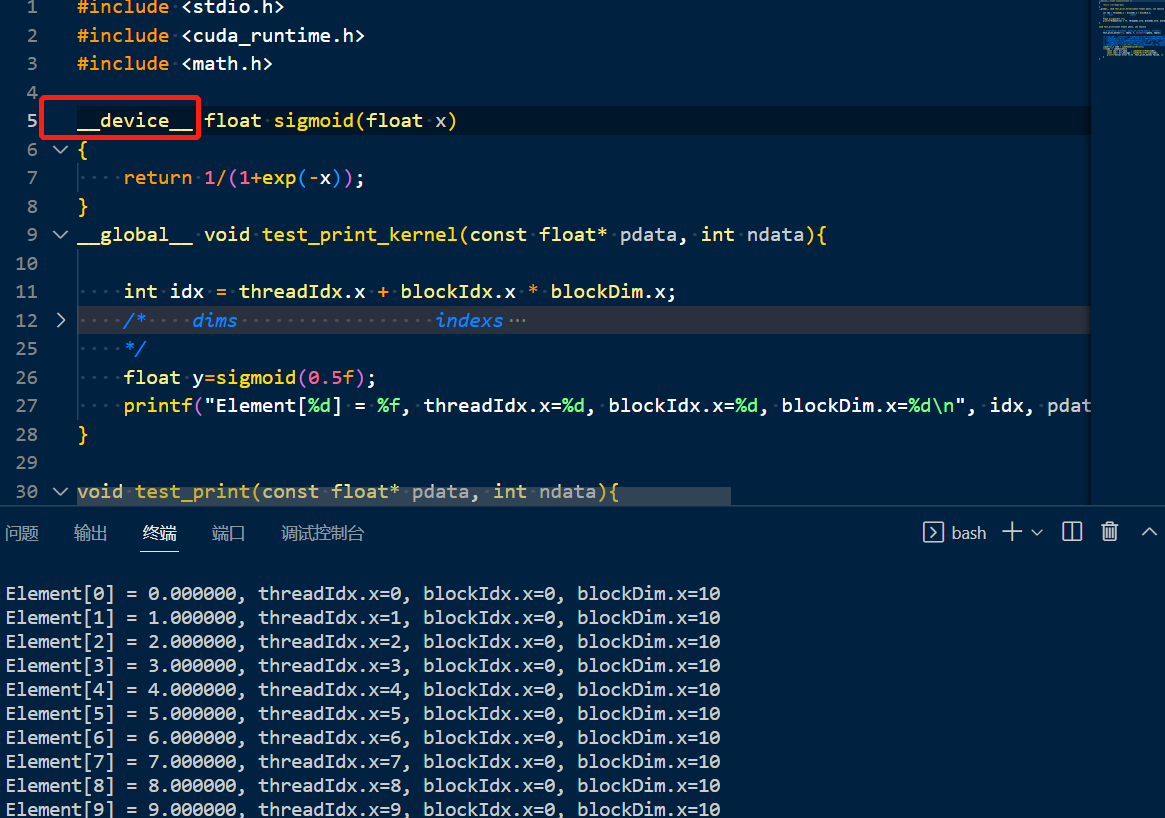
按道理print函数,包括exp也是host函数,为什么能够在核函数内部被正常调用呢?因为这些常规的函数,在GPU上都是有对应的实现的,invidia已经帮我们封装好了,都有相应的device版本和host版本。
- __global__表示核函数,由host调用。__device__表示为设备函数,由device调用。
-
- __host__表示为主机函数,由host调用。__shared__表示变量为共享变量。对于主机函数默认可以不用加
__host__。但如果一个函数定义为device函数,但同时也想被host函数中去调用,则需要同时加上__host__和__device__
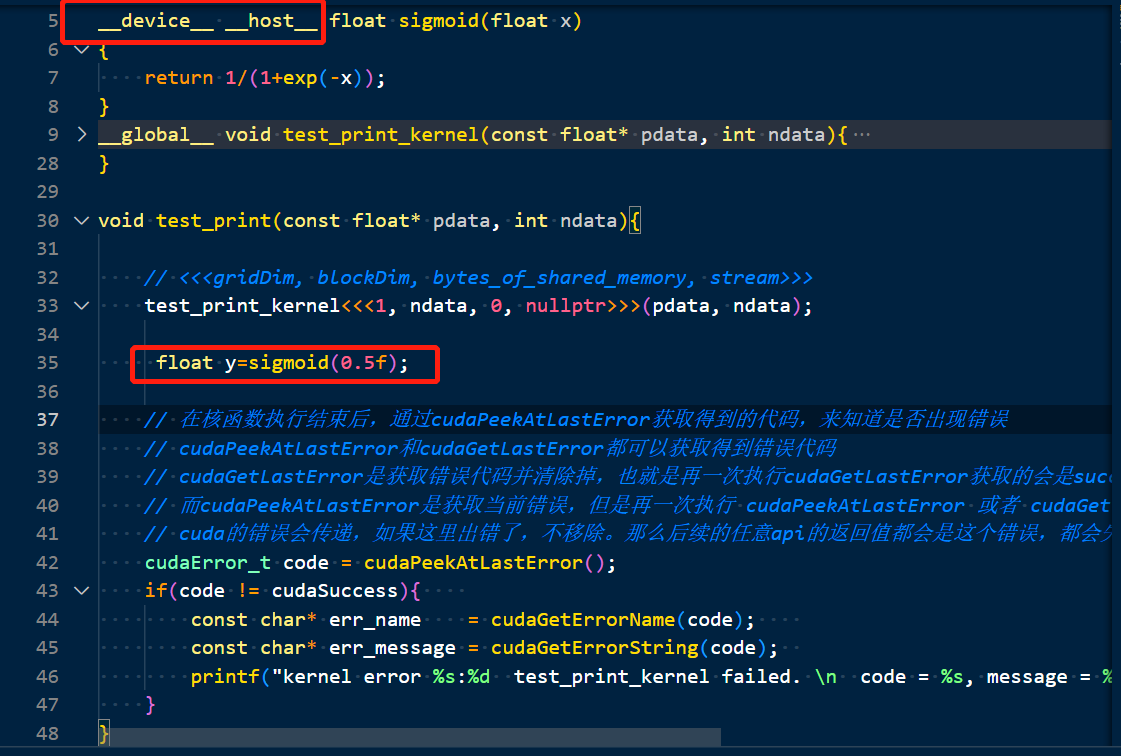
- __host__表示为主机函数,由host调用。__shared__表示变量为共享变量。对于主机函数默认可以不用加
-
- host调用核函数:
function<<<gridDim,blockDim,sharedMemorySize,stream>>>(args...);
函数以<<< >>>尖括号的形式包裹,中间包括4个参数,其中stream做异步的时候用流来控制,sharedMemorySize共享内存的大小,如果不需要共享内存的话,直接给个0就好了。gridDim,blockDim告诉GPU这个函数需要启动多少个线程。
1) grimDim 和 blockDim的类型为dim3,dim3是有默认参数的dim3(unsigned int vx=1,unsigned int vy=1,unsigned int vz=1)

如果参数没有填,默认值为1,如果dim3(2),则对应为x=2,y=1,z=1
- 总的线程数的计算:
nthreads = gridDim.x*gridDim.y*gridDim.z*blockDim.x*blockDim.y*blockDim.z

gridDim的上限值为gridDim(21亿,65536,65536) blockDim(1024,64,64),同时blodkDim还有另一个约束:blockDim.x*blockDim.y*blockDim.z <=1024
- host调用核函数:
-
- 只有__global__修饰的函数(核函数)才可以用<<< >>>的方式调用
-
- 调用核函数是
传值的,不能传引用,可以传递类、结构体等,核函数可以是模板,另外返回值必须是void
- 调用核函数是
-
- 核函数的执行是
异步的,也就是立即返回,如果给nullptr表示默认流,如果给的是stream就会加到stream里面去
- 核函数的执行是
-
- 线程layout主要用到
blockDim,gridDim
- 线程layout主要用到
-
- 核函数内访问线程索引主要用到
threadIdx,blockIdx,blockDim,gridDim这些内置变量,我们定义了核函数执行的线程数,如果想知道当前执行的这段代码是在·第几个线程,它的Id是多少·,可以通过int idx = threadIdx.x + blockIdx.x * blockDim.x;;进行计算就可以得到线程索引。
- 核函数内访问线程索引主要用到
2. 线程索引计算
核函数有4个内置变量:threadIdx,blockIdx,blockDim,gridDim,在核函数里面把blockDim,gridDim看作shape,告诉我们线程启动的总数目是多少,把threadIdx,blockIdx看作为index.
1) gridDim 定义为网格大小,对应的索引为blockIdx,比如grid为3,则blockIdx索引为0,1,2; blockIdx < gridDim
1) blockDim 定义为块大小,每个块有多少个线程,就是threadIdx: threadIdx < blockDim
2.1 索引计算方式
可以按照维度高低排序看待这个信息。dims:gridDim.z gridDim.y gridDim.x blockDim.z blockDim.y blockDim.x ;indexs:blockIdx.z,blockIdx.y,blockIdx.x,threadIdx.z,threadIdx.y.threadId.x,线程的绝对索引可以根据划线的方式计算:左乘右加,如下所示

也可以通过代码计算,计算线程的索引伪代码为:
position=0
for i in 6:
position *= dims[i]
position +=indexs[i]
举例:
假设核函数:
test_print_kernel <<< dim3(2),dim3(10),0,nullptr>>>(pdata,ndata)
此时就有gridDim.x=2, blockDim.x=10 对应的参数如下:
dims indexs(索引)
gridDim.z 1 blockIdx.z 0
gridDim.y 1 blockIdx.y 0
gridDim.x 2 blockIdx.x 0-1
blockDim.z 1 threadIdx.z 0
blockDim.y 1 threadIdx.y 0
blockDim.x 10 threadIdx.x 0-9
根据左乘右加的计算原则,就有:
int idx = threadIdx.x + blockIdx.x * blockDim.x;
因为blockIdx.x索引为0,1,不是0,所以需要参与计算
版权声明:本文为weixin_38346042原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。