前言
很多时候数据库的TempDB、日志等文件的暴增可能导致磁盘空间被占满,如果日常配置不到位,往往会导致数据库故障,业务被迫中断。
这种文件暴增很难排查,经验不足的一些运维人员可能更是无法排查具体原因,导致问题不能彻底解决。
场景描述
客户系统比较稳定,用了5台机器做了AlwaysOn高可用组,完全实现了读写分离。磁盘也做了规划,主库日常操作TempDB需求在20G以下,所以TempDB所在的磁盘只配置了100个G的空间。
本案例是客户突然接到监控报警,显示TempDB磁盘空间不足,可用空间不断减小直到耗尽。
比较戏剧的是,这个客户早上刚刚做了巡检数据库情况稳定,没有什么异常。
那么我初步判定,这必然是一次特殊操作或应用配置出错导致的问题。
深入指标分析
文件看问题
TempDB暴增必然伴随着文件的增长,首先我们看一下TempDB文件的增长情况。
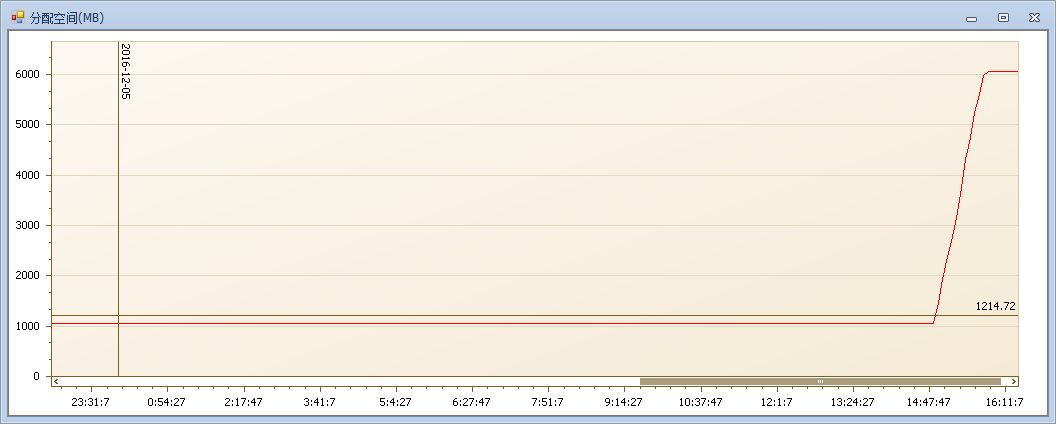
可见TempDB的分配空间在14点50几分的时候开始暴增,细心的朋友会发现这是1个G到6个G的增长,这是因为客户的TempDB配置了16个数据文件:
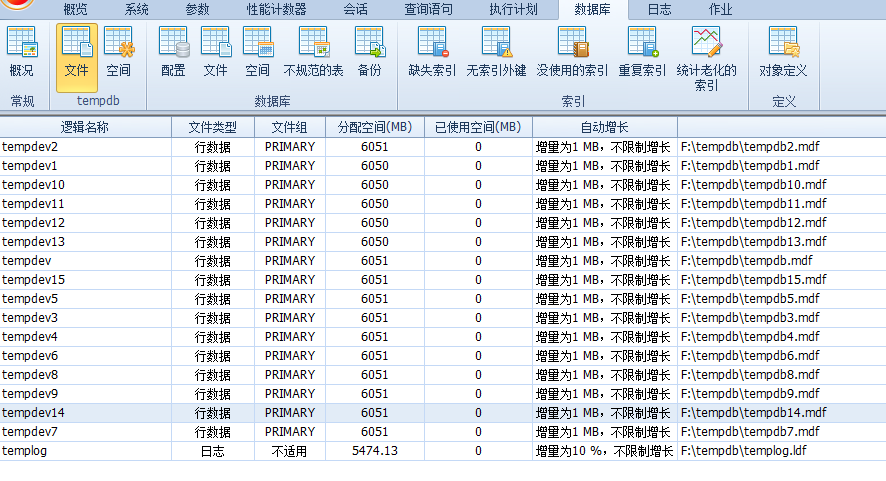
注:为什么配置这么多TempDB文件请参见:Expert 诊断优化系列——————给TempDB 降温
什么造成了增长
造成TempDB暴增原因很多语句使用临时表、语句排序、CheckDB等,但这些都是可以在语句中反应出来。所以下面我们分析一下语句。
注:很多使用过SQL专家云平台或工具的朋友可能不会注意里面一些细节,其实很多细节(如上面的TempDB文件增长趋势和下面的语句分配空间)的设计都是解决一些疑难的问题。
首先语句中的其中两个指标用户分配空间(MB)和内部对象分配空间(MB)指的就是对TempDB的使用消耗。
注:用户分配空间可能是临时表使用的比较多,内部对象分配空间可能是排序或者hash join等操作(其他使用的消耗可以参见前面给出的链接文章)

分配空间越大,也就说明语句越消耗TempDB资源。
我们有两种方式找到到底是什么操作导致的TempDB暴增,可以直接找时间点的语句,也可以在TempDB资源消耗的高到低顺序中找!
为了全面了解一下TempDB的问题,这里我们采用第二种方式。
那么我们就分析一下语句对TempDB资源被消耗的情况:
步骤1:首先我们按照用户对象分配空间排序: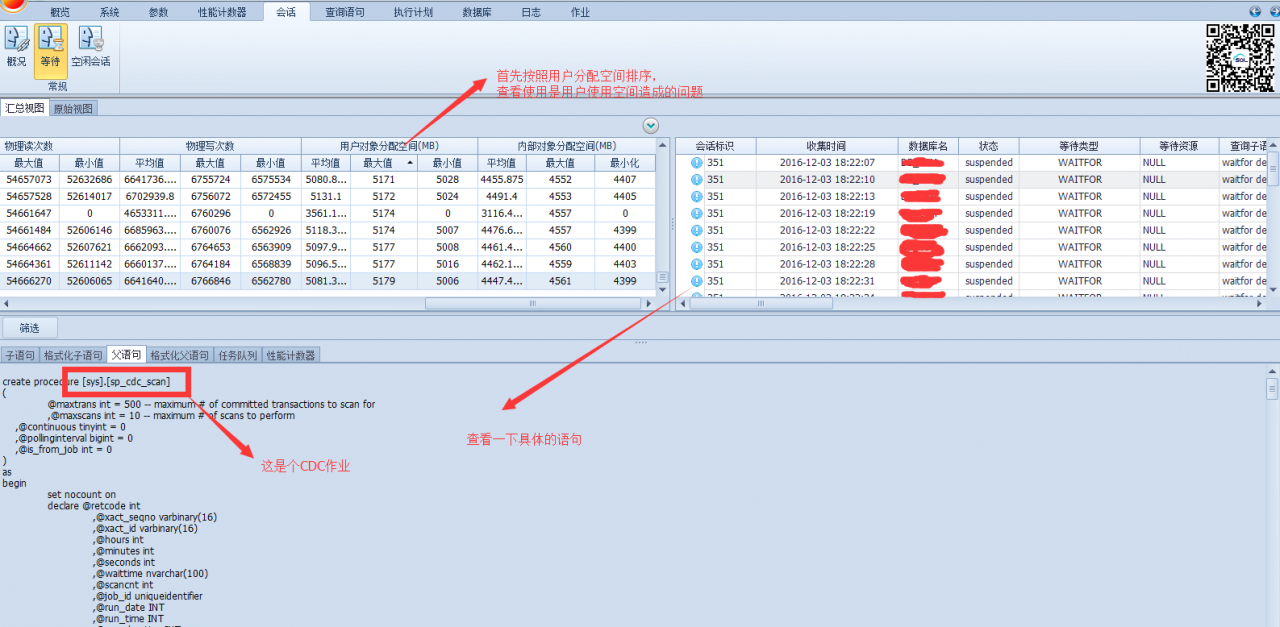
经过排查,这里面用户空间分配比较高的都是CDC的作业,服务器上确实运行这几个库的CDC作业。其他的一些操作的用户分配空间都比较小,所以这不是造成问题的原因!
步骤2:接着我们按照内部对象分配空间排序:

这里发现最消耗空间的是CheckDB的操作,但时间点是对应不上的,所以这也不是问题的原因。
继续排查:
在消耗排位在第三的这个语句中我们发现了等待资源FGCB_ADD_REMOVE(这个可以简单理解为有大量的文件自动生长发生,这里是16个TempDB文件),并且使用的内部对象空间也很高,并且我们还发现有多个会话同时执行这样的高消耗操作。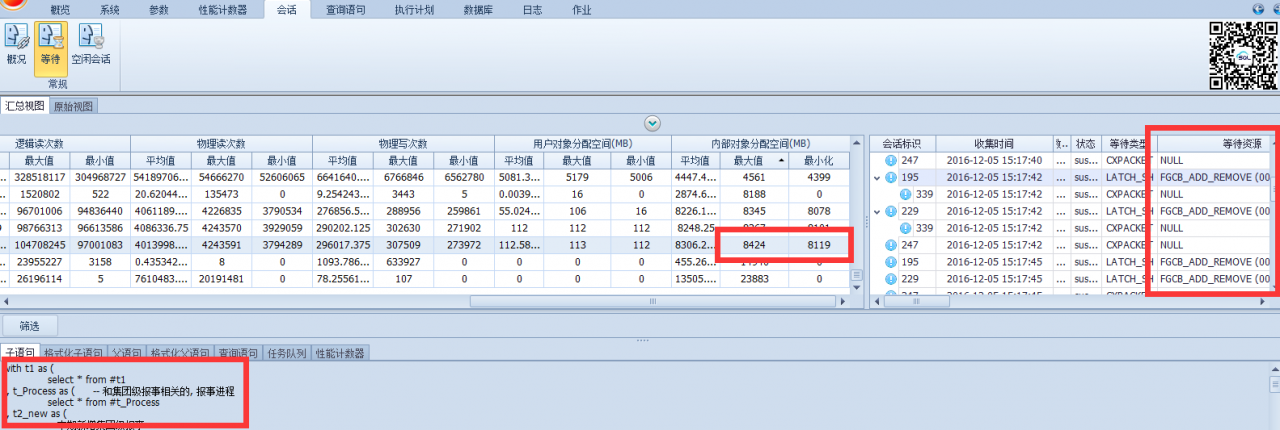
继续深入:

性能计数器的表象也与之前的种种迹象相吻合。

排查结论
综合各项现象指标,可以分析出系统在下午14点57分左后开始执行TempDB高消耗操作,语句本身是一个近千行涉及大量表连接排序等操作的复杂存储过程,对TempDB造成暴增的问题负主要责任,而且雪上加霜的是从会话的标识可以看出,这不是一个语句只一次的执行,而是在特定的时间存在比较大的并发操作导致。
与相关业务人员沟通,发现这是一个集团的类似报表的大消耗操作,因为对功能进行的调整,而程序人员的一次误操作而错误的指向了集群中的主库,而导致的问题。
————–博客地址—————————————————————————–
原文地址: http://www.cnblogs.com/double-K/
如有转载请保留原文地址!
—————————————————————————————————-
总结
问题的结果往往比较简单,也相对容易解决,但综合各项指标深入分析问题原因是值得和每一个技术人员探讨的,这也是为什么用一篇长案例来分析一个小点的原因。
再思考:本案例中服务器的架构设计是比较完善的,已经做了读写分离可以轻松的把这样的大操作指向辅助服务器,并且可以做到负载均衡,那么如果你的单机服务器也有类似这样一个报表操作,你会怎么办呢?
—————————————————————————————————-
原创链接:http://www.cnblogs.com/double-K/archive/2016/06/02/5538249.html