1 动态表
1.1 数据流上的关系查询
关系型SQL与stream processing对比如下:
| SQL | 流处理 |
|---|---|
| 有限元组 | 无限元组 |
| 完整数据集上的查询 | 无法基于所有数据查询 |
| 查询会结束 | 查询不会结束 |
Materialized View被定义为一条SQL查询,其会缓存查询结果。但当所查询的表(基表)被修改时,缓存的结果将过期。·
Eager View Maintenance会更新Materialized View,当基表被更新时,会立刻更新Materialized View中缓存的结果。
Eager View Maintenance和SQL Query在streams上的关系如下:
① 数据库表是INSERT、UPDATE、DELETE等DML语句流的结果,被流称为changelog stream。
② Materialized View被定义为一条SQL查询。为更新View,查询需要不断处理changelog stream。
③ Materialized View是streaming SQL查询结果。
1.2 动态表&连续查询
动态表是Flink流上Table API & SQL的核心概念,其随时间动态变化;
① 查询动态表会产生一个连续查询;
② 连续查询永不停止,其会产生一个动态表;
③ 当所查询的动态表发生变化时,查询会更新结果动态表。
连续查询的结果等同在输入表的快照上以批处理模式执行相同查询的结果。
流、动态表、连续查询的关系如下图所示:

① 流将转换为动态表;
② 在动态表上评估连续查询,生成新的动态表;
③ 生成的动态表将转换回流。
注意:动态表首先是一个逻辑概念。在查询执行过程中不一定(完全)实现动态表。在在下文中,本文将通过具有以下模式的单击事件流来解释动态表和连续查询的概念:
[
user: VARCHAR, // the name of the user
cTime: TIMESTAMP, // the time when the URL was accessed
url: VARCHAR // the URL that was accessed by the user
]
1.2.1 在流上定义表
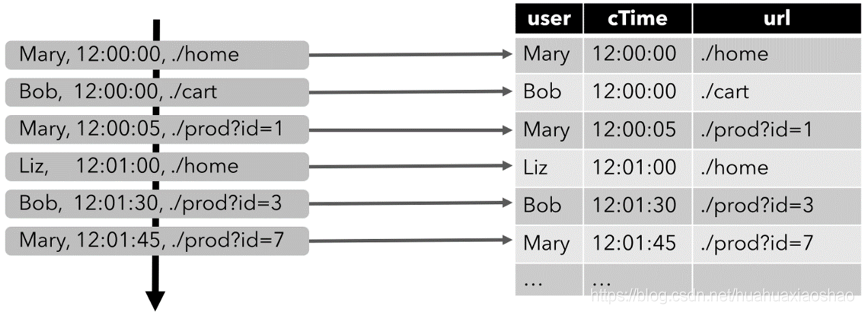
为了使用关系查询处理流,必须将其转换为Table。从概念上讲,流的每个记录都被解释为INSERT对结果表的修改。本质上,本文是从INSERT仅changelog流构建表。
下图可视化了click事件流(左侧)如何转换为表格(右侧)。随着插入更多点击流记录,结果表将持续增长。
1.2.2 连续查询
连续查询作用于动态表并又会产生动态表了连续查询不会终止并会根据其输入表(动态表)上的更新来更新其结果表(动态表)。
下面显示在点击事件流上定义的clicks表上显示两个查询示例。
首先是GROUP BY COUNT聚合查询示例。
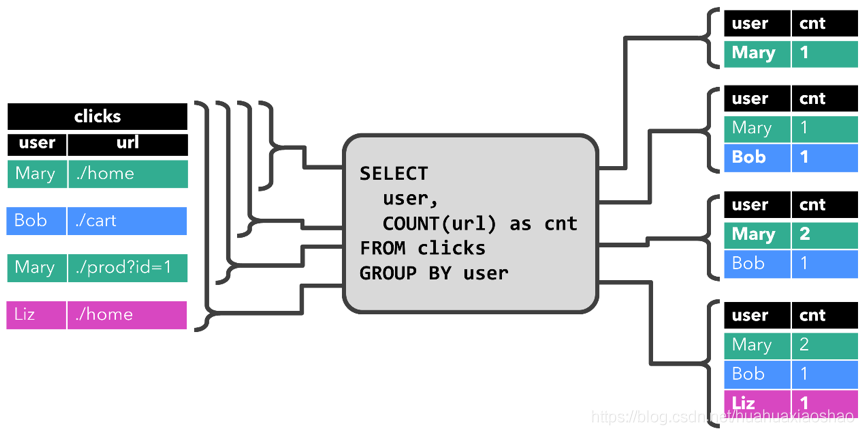
当查询开始时,clicks表为空;当第一行插入到clicks表中时,查询开始计算结果表(动态表),如[Mary,./home]插入后,结果表包含一行结果[Mary,1];当插入第二行[Bob,./cart]时,查询会更新结果表并插入新纪录[Bob,1]。第三行[Mary,./prod=id=1]插入时,查询会更新结果表中的[Mary,1]记录,将其更新为[Mary,2]。最后一行[Liz,1]插入clicks表后,也会更新到结果表(插入新纪录)。
第二个查询与第一个查询类似,除了用户属性之外,还在小时滚动窗口上对clicks表进行分组,然后对URL进行计数(基于时间的计算,如窗口基于特殊的时间属性)。
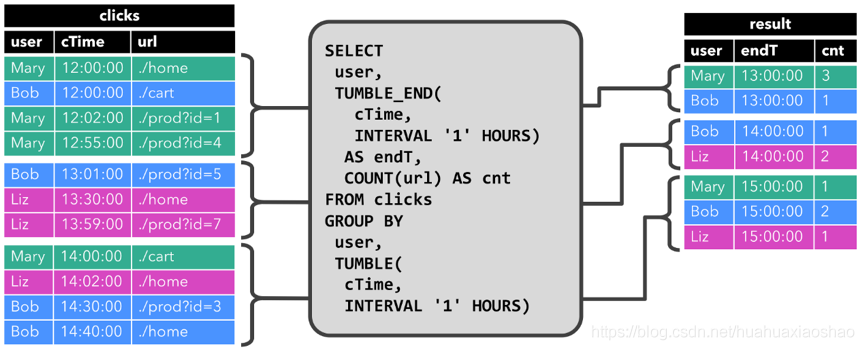
每个小时查询会计算结果并更新结果表。当cTime在12:00:00-12:59:59之间,clicks表存在四条记录,对应的查询计算出两条结果;下个时间窗口(13:00:00-13:59:59),clicks表中存在三条记录,对应的查询计算出两条结果添加值结果表中;当记录插入至clicks表中后,结果表也会被动态更新。
(1)更新和附加查询
上述两个查询虽然有些类似(均计算统计聚合分组),但两者也有显著不同:第一个查询会更新结果表的结果,如定义在结果表上的changelog流包含INSERT和UPDATE;第二个查询仅仅往结果表中添加记录,如定义在结果表上的changelog流只包含INSERT。一个查询是否生成仅插入表转化为流与更新表转化为流不同。
(2)查询限制
很多查询可以等同在流上的连续查询,一些查询由于需维护状态的大小或计算更新代价大导致查询计算代价太大。
状态大小:无界限流上的连续查询经常会运行数周或数月。因此,连续查询处理的数据总量可以很大,需要以前结果(结果表)的连续查询需要维护所有行以便进行更新。例如,第一个查询示例中需要保存每个user的url的count以便可以增加count,使得当输入表(左侧表)接收一行新数据时会产生新的结果(右侧表)。若只跟踪注册用户,那么维护cnt大小代价不会太大(注册用户量不太大)。但若非注册用户也分配唯一的用户名,则随着时间的增加,维护cnt大小代价将增大,最终导致查询失败。
SELECT user, COUNT(url)
FROM clicks
GROUP BY user;
计算更新:即使只添加或更新单行记录,一些查询需要重新计算和更新大部分结果行,通常这样的查询不适合作为连续查询。如下查询示例中,会根据最后一次点击的时间为每个用户计算RANK。一旦clicks表收到新行,用户的lastAction被更新并且应该计算新的RANK。然而由于不存在两行相同RANK,所以所有较低RANK的行也需要被更新。
SELECT user, RANK() OVER (ORDER BY lastLogin)
FROM (
SELECT user, MAX(cTime) AS lastAction FROM clicks GROUP BY user
);
1.2.3 表到流的转化
动态表可像传统表一样被INSERT、UPDATE、DELETE修改。可能只有一行的表被持续更新;或者是没有UPDATE、DELETE更改的只插入表。当将动态表转化为流或将其写入外部系统,这些更改(修改)需要被编码,Flink的Table API & SQL支持三种方式编码动态表上的更改(修改)。
Append-only流:仅使用INSERT更改进行修改的动态表可通过发出插入的行来转化为流。
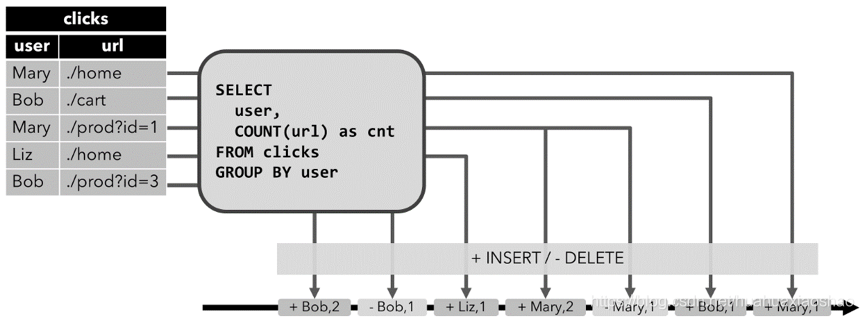
Retract流:Retract流包含两种类型消息(add消息和retract消息),通过将动态表的INSERT更改作为add消息、将DELETE更改作为retract消息、将UPDATE更改分解为旧记录的retract消息和新记录的add消息。下图展示了从动态表转化为retract流。
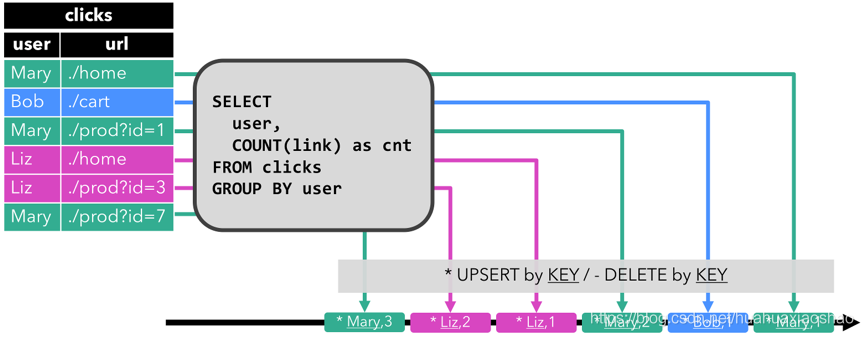
Upsert流:Upsert流包含两种类型消息(upset消息和delete消息),动态表转化为upsert流需要有主键(可复合),具有主键的动态表通过将INSERT、UPDATE更改编码为upset消息,将DELETE更改编码为delete消息。upset流与retract流主要区别是UPDATE更改使用单一消息(主键)进行编码,因此效率更高。下图展示了将动态表转化为upset流。
2 临时表(Temporal Table)
临时表表示更改表的(参数化)视图的概念,该表返回特定时间点的表的内容。
更改表可以是一个跟踪更改的历史表(例如数据库更改日志),也可以是一个具体化更改的维度表(例如数据库表)。
对于更改历史表,Flink可以跟踪更改,并允许在查询中的特定时间点访问表的内容。在Flink中,这种表由临时表函数(Temporal Table Function)表示。
对于变化的维表,Flink允许在处理查询时访问表的内容。在Flink中,这种表用临时表来表示。
2.1 产生的原因
2.1.1 与更改的历史记录表相关
本文假设有如下表RatesHistory:
SELECT * FROM RatesHistory;
rowtime currency rate
======= ======== ======
09:00 US Dollar 102
09:00 Euro 114
09:00 Yen 1
10:45 Euro 116
11:15 Euro 119
11:49 Pounds 108
RatesHistory代表一个增长的日元(汇率为1)仅追加(append-only)货币汇率表。例如,欧元兑日元从09:00到10:45的汇率为114;从10:45到11:15的汇率为116。
假设本文要在10:58的时间输出所有当前汇率,则需要一下SQL查询来计算结果表:
SELECT *
FROM RatesHistory AS r
WHERE r.rowtime = (
SELECT MAX(rowtime)
FROM RatesHistory AS r2
WHERE r2.currency = r.currency
AND r2.rowtime <= TIME '10:58');
相关子查询确定相应货币的最大时间小于或等于所需时间。外部查询列出具有最大时间戳的汇率。
下表显示了这种计算的结果。在示例中,考虑了10:45时欧元的更新,但是在10:58时表的版本中未考虑11:15时欧元的更新值以及新的值。
rowtime currency rate
======= ======== ======
09:00 US Dollar 102
09:00 Yen 1
10:45 Euro 116
临时表的概念旨在简化此类查询,加快其执行速度,并减少Flink的状态使用率。临时表是仅附加(append-only)表的参数化视图,将仅附加表的行解释为表的更改日志,并在特定时间点提供该表的版本。将仅附加表解释为更改日志(changelog)需要指定主键属性时间戳属性。主键确定覆盖哪些行,时间戳确定行有效的时间。
在上面的示例中,currency是RatesHistory表的主键,rowtime是timestamp属性。在Flink中,这由临时表函数表示。
2.1.2 与维度表变化相关
另一方面,某些用例需要连接变化的维表,该表是外部数据库表。假设LatestRates是一个以最新汇率具体化的表格(例如存储在其中)。LatestRates是物化历史RatesHistory。然后,时间10:58的LatestRates表的内容如下:
10:58> SELECT * FROM LatestRates;
currency rate
======== ======
US Dollar 102
Yen 1
Euro 116
12:00时间的LatestRates表的内容为:
12:00> SELECT * FROM LatestRates;
currency rate
======== ======
US Dollar 102
Yen 1
Euro 119
Pounds 108
2.2 临时表函数(Temporal Table Function)
为了访问临时表中的数据,必须传递一个时间属性,该属性确定要返回的表的版本。Flink使用使用表函数的SQL语法提供一种表达它的方法。定义后,临时表函数将使用单个时间参数timeAttribute并返回一组行。该集合包含相对于给定时间属性的所有现有主键的行的最新版本。
假设本文基于RatesHistory表定义了一个临时表函数Rates(timeAttribute),则可以通过以下方式查询该函数:
SELECT * FROM Rates('10:15');
rowtime currency rate
======= ======== ======
09:00 US Dollar 102
09:00 Euro 114
09:00 Yen 1
SELECT * FROM Rates('11:00');
rowtime currency rate
======= ======== ======
09:00 US Dollar 102
10:45 Euro 116
09:00 Yen 1
Rates(timeAttribute)的每个查询都返回给定timeAttribute的Rates的状态。
注意:目前,Flink不支持使用常量时间属性参数直接查询临时表函数。目前,临时表函数只能在join中使用。上面的示例用于提供有关Rates(timeAttribute)函数返回值的直观信息。
2.2.1 定义临时表函数
import org.apache.flink.table.functions.TemporalTableFunction;
(...)
// Get the stream and table environments.
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Provide a static data set of the rates history table.
List<Tuple2<String, Long>> ratesHistoryData = new ArrayList<>();
ratesHistoryData.add(Tuple2.of("US Dollar", 102L));
ratesHistoryData.add(Tuple2.of("Euro", 114L));
ratesHistoryData.add(Tuple2.of("Yen", 1L));
ratesHistoryData.add(Tuple2.of("Euro", 116L));
ratesHistoryData.add(Tuple2.of("Euro", 119L));
// Create and register an example table using above data set.
// In the real setup, you should replace this with your own table.
DataStream<Tuple2<String, Long>> ratesHistoryStream = env.fromCollection(ratesHistoryData);
Table ratesHistory = tEnv.fromDataStream(ratesHistoryStream, "r_currency, r_rate, r_proctime.proctime");
tEnv.createTemporaryView("RatesHistory", ratesHistory);
// Create and register a temporal table function.
// Define "r_proctime" as the time attribute and "r_currency" as the primary key.
TemporalTableFunction rates = ratesHistory.createTemporalTableFunction("r_proctime", "r_currency"); // <==== (1)
tEnv.registerFunction("Rates", rates); // <==== (2)
第(1)行创建了一个rates临时表函数,它允许使用表API中的函数rates。
第(2)行在表环境中以名称Rates注册此函数,这允许在SQL中使用Rates函数。
2.3 临时表
注意:仅blink planner支持此功能。
为了访问临时表中的数据,当前必须使用LookupableTableSource定义一个TableSource。Flink使用FOR SYSTEM_TIME AS OF的SQL语法查询临时表,这在SQL:2011中提出。
假设定义了一个LatestRates临时表,可以通过一下方式查询此类表:
SELECT * FROM LatestRates FOR SYSTEM_TIME AS OF TIME '10:15';
currency rate
======== ======
US Dollar 102
Euro 114
Yen 1
SELECT * FROM LatestRates FOR SYSTEM_TIME AS OF TIME '11:00';
currency rate
======== ======
US Dollar 102
Euro 116
Yen 1
注意:目前,Flink不支持以固定时间直接查询临时表。目前,临时表只能在join中使用。上面的示例用于直观说明临时表LatestRates返回的内容。
2.3.1 定义临时表
// Get the stream and table environments.
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = TableEnvironment.getTableEnvironment(env);
// Create an HBaseTableSource as a temporal table which implements LookableTableSource
// In the real setup, you should replace this with your own table.
HBaseTableSource rates = new HBaseTableSource(conf, "Rates");
rates.setRowKey("currency", String.class); // currency as the primary key
rates.addColumn("fam1", "rate", Double.class);
// register the temporal table into environment, then we can query it in sql
tEnv.registerTableSource("Rates", rates);
3 总结
动态表的加入,使得Flink可以通过SQL来实现流式处理。为了更好地查询某个时间点的表的数据,引入了临时表和临时表函数。到这里,Flink SQL的内容也学得差不多了。通过对Flink SQL的学习,让我明白了SQL的重要性,后续,我会加强SQL的训练。