Data structures are nothing different. They are like the bookshelves of your application where you can organize your data. Different data structures will give you different facility and benefits. To properly use the power and accessibility of the data structures you need to know the trade-offs of using one.
大意是不同的数据结构有不同的适用场景和优缺点,你需要仔细权衡自己的需求之后妥善适用它们,布隆过滤器就是践行这句话的代表。
什么是布隆过滤器
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
实现原理
布隆过滤器(Bloom Filter)的核心实现是一个超大的位数组和几个哈希函数。假设位数组的长度为m,哈希函数的个数为k
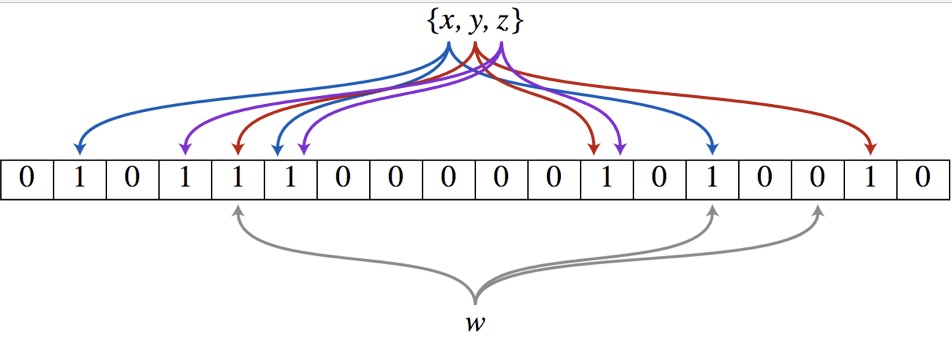
以上图为例,具体的操作流程:假设集合里面有3个元素{x, y, z},哈希函数的个数为3。首先将位数组进行初始化,将里面每个位都设置位0。对于集合里面的每一个元素,将元素依次通过3个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为1。查询W元素是否存在集合中的时候,同样的方法将W通过哈希映射到位数组上的3个点。如果3个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。反之,如果3个点都为1,则该元素可能存在集合中。注意:此处不能判断该元素是否一定存在集合中,可能存在一定的误判率。可以从图中可以看到:假设某个元素通过映射对应下标为4,5,6这3个点。虽然这3个点都为1,但是很明显这3个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是1,这是误判率存在的原因。
举例
布隆过滤器是一个 bit 向量或者说 bit 数组,长这样:
![]()
如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成**多个哈希值,**并对每个生成的哈希值指向的 bit 位置 1,例如针对值 “baidu” 和三个不同的哈希函数分别生成了哈希值 1、4、7,则上图转变为:

Ok,我们现在再存一个值 “tencent”,如果哈希函数返回 3、4、8 的话,图继续变为:
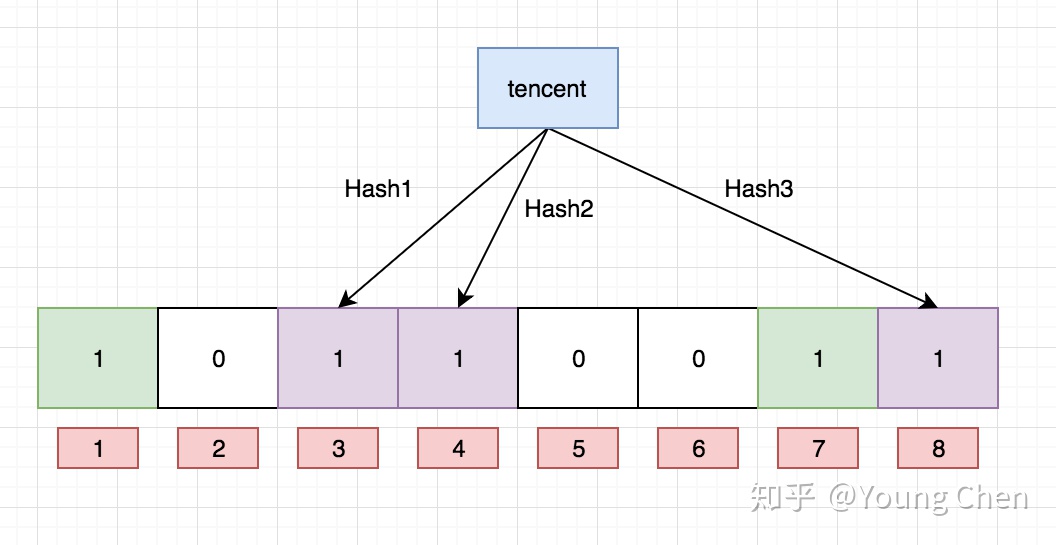
值得注意的是,4 这个 bit 位由于两个值的哈希函数都返回了这个 bit 位,因此它被覆盖了。现在我们如果想查询 “dianping” 这个值是否存在,哈希函数返回了 1、5、8三个值,结果我们发现 5 这个 bit 位上的值为 0,说明没有任何一个值映射到这个 bit 位上,因此我们可以很确定地说 “dianping” 这个值不存在。而当我们需要查询 “baidu” 这个值是否存在的话,那么哈希函数必然会返回 1、4、7,然后我们检查发现这三个 bit 位上的值均为 1,那么我们可以说 “baidu” 存在了么?答案是不可以,只能是 “baidu” 这个值可能存在。
这是为什么呢?答案跟简单,因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值 “taobao” 即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断 “taobao” 这个值存在。
支持删除么
目前我们知道布隆过滤器可以支持 add 和 isExist 操作,那么 delete 操作可以么,答案是不可以,例如上图中的 bit 位 4 被两个值共同覆盖的话,一旦你删除其中一个值例如 “tencent” 而将其置位 0,那么下次判断另一个值例如 “baidu” 是否存在的话,会直接返回 false,而实际上你并没有删除它。
如何解决这个问题,答案是计数删除。但是计数删除需要存储一个数值,而不是原先的 bit 位,会增大占用的内存大小。这样的话,增加一个值就是将对应索引槽上存储的值加一,删除则是减一,判断是否存在则是看值是否大于0。
如何选择哈希函数个数和布隆过滤器长度
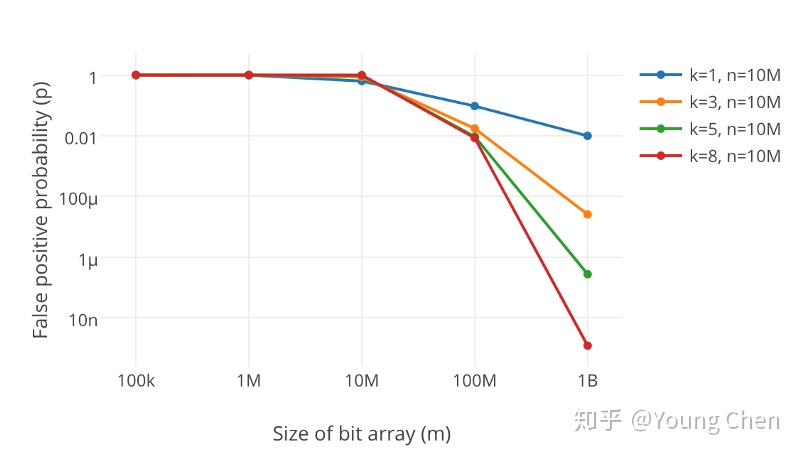
很显然,过小的布隆过滤器很快所有的 bit 位均为 1,那么查询任何值都会返回“可能存在”,起不到过滤的目的了。布隆过滤器的长度会直接影响误报率,布隆过滤器越长其误报率越小。
另外,哈希函数的个数也需要权衡,个数越多则布隆过滤器 bit 位置位 1 的速度越快,且布隆过滤器的效率越低;但是如果太少的话,那我们的误报率会变高。
 k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数,p 为误报率
k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数,p 为误报率
如何选择适合业务的 k 和 m 值呢,这里直接贴一个公式:
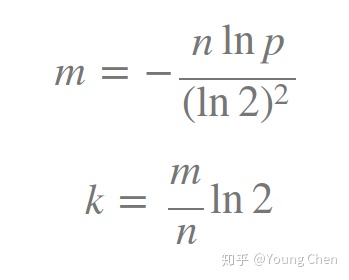
最佳实践
适用场景:如何判断一个元素是否存在一个集合中?
常见的适用常见有,利用布隆过滤器减少磁盘 IO 或者网络请求,因为一旦一个值必定不存在的话,我们可以不用进行后续昂贵的查询请求。
另外,既然你使用布隆过滤器来加速查找和判断是否存在,那么性能很低的哈希函数不是个好选择,推荐 MurmurHash、Fnv 这些。
大Value拆分
Redis 因其支持 setbit 和 getbit 操作,且纯内存性能高等特点,因此天然就可以作为布隆过滤器来使用。但是布隆过滤器的不当使用极易产生大 Value,增加 Redis 阻塞风险,因此生成环境中建议对体积庞大的布隆过滤器进行拆分。
拆分的形式方法多种多样,但是本质是不要将 Hash(Key) 之后的请求分散在多个节点的多个小 bitmap 上,而是应该拆分成多个小 bitmap 之后,对一个 Key 的所有哈希函数都落在这一个小 bitmap 上。
BloomFilter算法
简介:布隆过滤器实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
原理:当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。
优点:相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数(O(k))。而且它不存储元素本身,在某些对保密要求非常严格的场合有优势。
缺点:一定的误识别率和删除困难。
结合以上几点及去重需求(容忍误判,会误判在,在则丢,无妨),决定使用BlomFilter。
思想
位数组和k个散列函数
位数组
初始状态时,BloomFilter是一个长度为m的位数组,每一位都置为0。
添加元素(k个独立的hash函数)
添加元素时,对x使用k个哈希函数得到k个哈希值,对m取余,对应的bit位设置为1。
判断元素是否存在
判断y是否属于这个集合,对y使用k个哈希函数得到k个哈希值,对m取余,所有对应的位置都是1,则认为y属于该集合(哈希冲突,可能存在误判),否则就认为y不属于该集合。
图中y1不是集合中的元素,y2属于这个集合或者是一个false positive。
BloomFilter有以下参数:
- m 位数组的长度
- n 加入其中元素的数量
- k 哈希函数的个数
- f False Positive
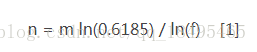
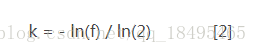

以上3个公式是程序实现Bloom Filter的关键公式。
故可以通过调节参数,使用Hash函数的个数,位数组的大小来降低失误率。
Java + redis BitMap 实现分布式布隆过滤器
对于redis来说,本身自带了Bitmaps的“数据结构”(本质上还是一个字符串),已经提供了位操作的接口,因此重构本身并不复杂,相对比较复杂的是,之前提到的实现自动扩容特性。
这里实现自动扩容的思想是,在redis中记录一个自增的游标cursor,如果当前key对应的Bitmaps已经达到饱和状态,则cursor自增,同时用其生成一个新的key,并创建规模同等的Bitmaps。然后在get的时候,需要判断该元素是否存在于任意一个Bitmaps中。于是整个的逻辑就变成,一个元素在每个Bitmaps中都不存在时,才能插入当前cursor对应key的Bitmaps中。
下面是代码的实现部分。
首先,为了简化redis的操作,定义了2个函数式接口,分别执行单条命令和pipeline,另外还实现了一个简单的工具类
@FunctionalInterface
public interface JedisExecutor<T> {
T execute(Jedis jedis);
}
@FunctionalInterface
public interface PipelineExecutor {
void load(Pipeline pipeline);
}
public class JedisUtils {
private static final GenericObjectPoolConfig poolConfig = new GenericObjectPoolConfig();
private JedisPool jedisPool;
public JedisUtils() {
jedisPool = new JedisPool(poolConfig, "localhost", 6379);
}
public <T> T execute(JedisExecutor<T> jedisExecutor) {
try (Jedis jedis = jedisPool.getResource()) {
return jedisExecutor.execute(jedis);
}
}
public List<Object> pipeline(List<PipelineExecutor> pipelineExecutors) {
try (Jedis jedis = jedisPool.getResource()) {
Pipeline pipeline = jedis.pipelined();
for (PipelineExecutor executor : pipelineExecutors)
executor.load(pipeline);
return pipeline.syncAndReturnAll();
}
}
}
其次在Strategy中,对put和mightContain作了一点修改,其中被注释的部分是Guava中的实现。为了简化,这里我们只接受String对象。
这里先把所有的随机函数对应的索引位置收集到一个数组中,然后交由底层的RedisBitmaps处理get或set,具体过程后面会详细说明。
bits.ensureCapacityInternal()方法,即表示自动扩容,这个函数名是从ArrayList中搬过来的。
@ Override
public boolean put(String string, int numHashFunctions, RedisBitmaps bits) {
long bitSize = bits.bitSize();
byte[] bytes = Hashing.murmur3_128().hashString(string, Charsets.UTF_8).asBytes();
long hash1 = lowerEight(bytes);
long hash2 = upperEight(bytes);
boolean bitsChanged = false;
long combinedHash = hash1;
// for (int i = 0; i < numHashFunctions; i++) {
// bitsChanged |= bits.set((combinedHash & Long.MAX_VALUE) % bitSize);
// combinedHash += hash2;
// }
long[] offsets = new long[numHashFunctions];
for (int i = 0; i < numHashFunctions; i++) {
offsets[i] = (combinedHash & Long.MAX_VALUE) % bitSize;
combinedHash += hash2;
}
bitsChanged = bits.set(offsets);
bits.ensureCapacityInternal();//自动扩容
return bitsChanged;
}
@ Override
public boolean mightContain(String object, int numHashFunctions, RedisBitmaps bits) {
long bitSize = bits.bitSize();
byte[] bytes = Hashing.murmur3_128().hashString(object, Charsets.UTF_8).asBytes();
long hash1 = lowerEight(bytes);
long hash2 = upperEight(bytes);
long combinedHash = hash1;
// for (int i = 0; i < numHashFunctions; i++) {
// if (!bits.get((combinedHash & Long.MAX_VALUE) % bitSize)) {
// return false;
// }
// combinedHash += hash2;
// }
// return true;
long[] offsets = new long[numHashFunctions];
for (int i = 0; i < numHashFunctions; i++) {
offsets[i] = (combinedHash & Long.MAX_VALUE) % bitSize;
combinedHash += hash2;
}
return bits.get(offsets);
}
最后,也是最重要的RedisBitmaps,其中bitSize用了Guava布隆过滤器中计算Long型数组长度的方法,得到bitSize之后使用setbit命令初始化一个全部为0的位数组。get(long offset)和set(long offset),这两个与Guava布隆过滤器中的逻辑类似,这里就不再赘述了,而get(long[] offsets)方法中,所有的offset要与每一个cursor对应的Bitmaps进行判断,若全部命中,那么这个元素就可能存在于该Bitmaps,反之若不能完全命中,则表示该元素不存在于任何一个Bitmaps,所以当满足这个条件,在set(long[] offsets)方法中,就可以插入到当前key的Bitmaps中了。
在ensureCapacityInternal方法,判断需要扩容的条件是bitCount*2>bitSize,bitCount表示一个Bitmaps中“1”出现的个数,也就是当“1”出现的个数超过总数的一半时,进行扩容操作——首先使用incr命令对cursor自增,然后使用新的key创建一个新的Bitmaps。
class RedisBitmaps {
private static final String BASE_KEY = "bloomfilter";
private static final String CURSOR = "cursor";
private JedisUtils jedisUtils;
private long bitSize;
RedisBitmaps(long bits) {
this.jedisUtils = new JedisUtils();
this.bitSize = LongMath.divide(bits, 64, RoundingMode.CEILING) * Long.SIZE;//位数组的长度,相当于n个long的长度
if (bitCount() == 0) {
jedisUtils.execute((jedis -> jedis.setbit(currentKey(), bitSize - 1, false)));
}
}
boolean get(long[] offsets) {
for (long i = 0; i < cursor() + 1; i++) {
final long cursor = i;
//只要有一个cursor对应的bitmap中,offsets全部命中,则表示可能存在
boolean match = Arrays.stream(offsets).boxed()
.map(offset -> jedisUtils.execute(jedis -> jedis.getbit(genkey(cursor), offset)))
.allMatch(b -> (Boolean) b);
if (match)
return true;
}
return false;
}
boolean get(final long offset) {
return jedisUtils.execute(jedis -> jedis.getbit(currentKey(), offset));
}
boolean set(long[] offsets) {
if (cursor() > 0 && get(offsets)) {
return false;
}
boolean bitsChanged = false;
for (long offset : offsets)
bitsChanged |= set(offset);
return bitsChanged;
}
boolean set(long offset) {
if (!get(offset)) {
jedisUtils.execute(jedis -> jedis.setbit(currentKey(), offset, true));
return true;
}
return false;
}
long bitCount() {
return jedisUtils.execute(jedis -> jedis.bitcount(currentKey()));
}
long bitSize() {
return this.bitSize;
}
private String currentKey() {
return genkey(cursor());
}
private String genkey(long cursor) {
return BASE_KEY + "-" + cursor;
}
private Long cursor() {
String cursor = jedisUtils.execute(jedis -> jedis.get(CURSOR));
return cursor == null ? 0 : Longs.tryParse(cursor);
}
void ensureCapacityInternal() {
if (bitCount() * 2 > bitSize())
grow();
}
void grow() {
Long cursor = jedisUtils.execute(jedis -> jedis.incr(CURSOR));
jedisUtils.execute((jedis -> jedis.setbit(genkey(cursor), bitSize - 1, false)));
}
void reset() {
String[] keys = LongStream.range(0, cursor() + 1).boxed().map(this::genkey).toArray(String[]::new);
jedisUtils.execute(jedis -> jedis.del(keys));
jedisUtils.execute(jedis -> jedis.set(CURSOR, "0"));
jedisUtils.execute(jedis -> jedis.setbit(currentKey(), bitSize - 1, false));
}
private PipelineExecutor apply(PipelineExecutor executor) {
return executor;
}
}
下面我们做一个单元测试来验证其正确性。
如果我们插入的数量等于原预计总数,RedisBloomFilter扩容了1次,而两个布隆过滤器的结果一致,都为false,true,false。
如果插入的数量为原预计总数的3倍,RedisBloomFilter扩容了3次,并且仍判断正确,而Guava布隆过滤器则在判断str3时出现误判。
public class TestRedisBloomFilter {
private static final int TOTAL = 10000;
private static final double FPP = 0.0005;
@ Test
public void test() {
RedisBloomFilter redisBloomFilter = RedisBloomFilter.create(TOTAL, FPP);
redisBloomFilter.resetBitmap();
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), TOTAL, FPP);
IntStream.range(0, /* 3* */TOTAL).boxed()
.map(i -> Hashing.md5().hashInt(i).toString())
.collect(toList()).forEach(s -> {
redisBloomFilter.put(s);
bloomFilter.put(s);
});
String str1 = Hashing.md5().hashInt(99999).toString();
String str2 = Hashing.md5().hashInt(9999).toString();
String str3 = "abcdefghijklmnopqrstuvwxyz123456";
System.out.println(redisBloomFilter.mightContain(str1) + ":" + bloomFilter.mightContain(str1));
System.out.println(redisBloomFilter.mightContain(str2) + ":" + bloomFilter.mightContain(str2));
System.out.println(redisBloomFilter.mightContain(str3) + ":" + bloomFilter.mightContain(str3));
}
}
>>
grow bloomfilter-1
false:false
true:true
false:false
>>
grow bloomfilter-1
grow bloomfilter-2
grow bloomfilter-3
false:false
true:true
false:true
综上,本文利用了Guava布隆过滤器的思想,并结合Redis中的Bitmaps等特性实现了支持动态扩容的布隆过滤器,它将布隆过滤器底层的位数据装载到了Redis数据库中,这样的好处在于可以部署在更复杂的多应用或分布式系统中,还可以利用Redis完成持久化,定时过期等功能。