由于我还没有看过具体的 prompt 的论文和相关代码,所以我主要参考的刘鹏飞大佬的论文和博客来简单直观解释什么是 prompt learning。
1 预训练语言模型
如果你对之前预训练语言模型已经很了解了,那么可以直接跳到第二节。
在刘鹏飞大佬的论文里,他将预训练语言模型分为了四类:基于特征工程 (feature engineering) 的方法,基于结构工程 (architecture engineering) 的方法,基于目标工程 (objective engineering) 的方法,和基于提示工程 (prompt engineering) 的方法。为了更好解释何为 prompt,在本小节中,我们会先对前三种方法做一个介绍。
1.1 Feature engineering
由于我没有看过任何这类别的论文,也没有怎么使用过这类预训练模型,所以如果这一小节有问题,请一笑而过,然后麻烦顺手帮我指出其中的错误。
基于特征工程的方法,其目的是为了通过人们的先验知识来定义某些规则,使用这些规则来更好地提取出文本中的特征,以此来对文本进行编码。
1.1.1 词袋模型
词袋模型 (Bag-of-words model, BOW) 通过计算词频来对词语进行编码。考虑以下的三个句子:
E1: 我 喜欢 小丽
E2: 小丽 喜欢 小明
E3: 小明 喜欢 我
对这个混乱的三角恋关系,我们构建出词与id之间的映射关系:{‘我’: 0, ‘喜欢’: 1, ‘小丽’: 2, ‘小明’: 3},接着统计词频,即可获得词编码。E1的词编码为
[
2
,
2
,
2
,
0
]
[2, 2, 2, 0]
[2,2,2,0];E2的词编码为
[
0
,
2
,
2
,
2
]
[0, 2, 2, 2]
[0,2,2,2];E3的词编码为
[
2
,
2
,
0
,
2
]
[2, 2, 0, 2]
[2,2,0,2]。
优点:1. 比起 one-hot
V
×
V
V \times V
V×V 的内存消耗 (
V
V
V 为词表大小),BOW 的内存消耗只有
V
V
V;2. 可以提取出词频这个特征。
缺点:1. 没有词序特征;2. 不是词频越大的词越重要 (比如“的”)。
1.1.2 TF-IDF
TF-IDF (Term Frequency-Inverse Document Frequency) 能够有效识别词语在文本中的重要程度。其分为两部分,TF 和 IDF。
TF 算法的公式如下:
t
f
i
j
=
n
i
j
∑
k
n
k
j
tf_{ij}=\frac{n_{ij}}{\sum_k n_{kj}}
tfij=∑knkjnij
其中
i
,
k
i, k
i,k 分别表示词语
i
i
i 和词语
k
k
k;
j
j
j 表示文档
j
j
j;
n
i
j
n_{ij}
nij 表示词语
i
i
i 在文档
j
j
j 中的词频。该算法的含义是计算词语
i
i
i 在文档
j
j
j 中的占比。
IDF算法的公式如下:
i
d
f
i
=
l
o
g
(
∣
D
∣
1
+
∣
D
i
∣
)
idf_i = {\rm log}(\frac{|D|}{1 + |D_i|})
idfi=log(1+∣Di∣∣D∣)
其中
i
i
i 表示词语
i
i
i;
∣
D
∣
|D|
∣D∣ 表示文档的总数;
∣
D
i
∣
|D_i|
∣Di∣ 表示词语
i
i
i 出现在文档中的总次数;1是拉普拉斯平滑,防止词语
i
i
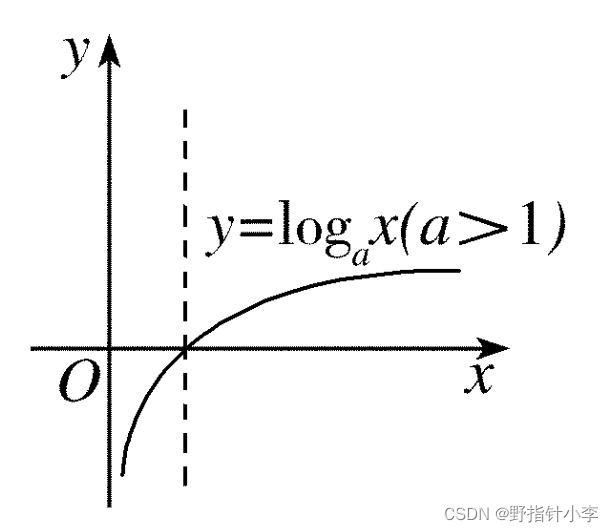
i 没有在任何文档中出现而导致分母为零。这个公式最直观的理解可以从对数函数的图像入手。
l
o
g
{\rm log}
log 是个单调函数。由于
∣
D
∣
|D|
∣D∣ 是常数,当
∣
D
i
∣
=
1
|D_i|=1
∣Di∣=1 时,
i
d
f
idf
idf 取得最大值;而当
∣
D
i
∣
=
∣
D
∣
|D_i|=|D|
∣Di∣=∣D∣ 时,
i
d
f
idf
idf 取得最小值。这也就是说,如果词语
i
i
i 只在一个或很少的文档中出现,那么这个词就对这些文档很重要,反之如果词语
i
i
i 在很多文档中出现,那么就显得不那么重要 (比如“的”)。
TF-IDF 算法的公式如下:
t
f
i
d
f
i
j
=
t
f
i
j
×
i
d
f
i
tfidf_{ij}=tf_{ij} \times idf_i
tfidfij=tfij×idfi
那么结合上两个公式,我们就发现,TF-IDF 算法不仅考虑了在单一文档中的词频,还考虑了该词语在全局的一个出现频率。就是说如果这个词在少量文章中出现,且词频很高,那么这个词就对这个文章很重要,反之亦然。
优点:可以有效识别词语对文档的重要性。
缺点:不能够包含词语的上下文信息。
1.1.3 总结
基于特征的方法,最大的特点就是运行速度快,同时如果特征提取到位可能会取得很好的效果,但是最大的难点就在于如何根据先验知识来设计需要提取的特征。
1.2 Architecture engineering
基于结构工程的方法,无需再用人的先验知识来进行特征工程,而是将人力放在如何设计一个好的模型结构来自动学习文本中的特征。
1.2.1 Word2Vec
关于 Word2Vec 的详细信息可以看我以前的博客《Word2Vec原理与公式详细推导》。简单来说就是通过一个线性的全连接层,来预测词语的上下文或者根据词语的上下文来预测该词语。
优点:我没记错的话 W2V 算是掀起了深度学习在NLP领域的热潮,可以为每个词语单独赋予一个独有的词向量,并且词向量中还能够包含上该词语的上下文信息。
缺点:1. 不能包含全局信息;2. 每个词语有且仅有一个词向量,没办法有效区分多义词。
1.2.2 GloVe
关于 GloVe 的详细信息可以看我以前的博客《GloVe原理与公式讲解》。GloVe 则是通过给定一个目标公式,然后将其反推出来。
优点:在 W2V 的基础上,还能够学习到词语的全局信息。
缺点:同样没有办法区分多义词。
1.2.3 FastText
FastText 的模型结构与 W2V 类似,只不过 W2V 是做预测上下文或中间词,FastText 是做文本分类[4]。就是说只是输出层不同。而且 FastText 的输入是 char 级的 n-gram,其目的在于许多词的字母都是重复的 (比如 apple 和 people 有 ple 是重复的),采用这种输入方式可以有效降低输入的数量,也可以学习到词语的共性。虽然其目的在于做文本分类,但是也可以学习到字符级的词向量。
优点:可以学习字符级的词向量,训练速度快,且性能不弱于很多大模型。
缺点:训练出的词向量可以放在下游任务,但是如果要用该模型做下游任务会有困难。
1.2.4 ELMo
关于 EMLo 的详细信息可以看我以前的博客《BERT学习笔记(4)——小白版ELMo and BERT》。简单来说就是用一个双向RNN来学习词语
i
i
i 的上文与下文,通过这些上文信息与下文信息来预测词语
i
i
i。
优点:可以解决一词多义的问题,因为不同的上下文输出的词向量是有区别的。
缺点:模型依旧是输出词向量,而模型本身并不能很好的用于下游任务。
1.2.5 总结
Architecture engineering 采用了深度学习的方法来学习词向量,当输入语料很大的时候,可以学习出一个质量很高的词嵌入。但是这类方法仅仅是训练出词向量,再将词向量放入到下游模型中作为输入,而模型本身并不会用来做下游任务。
1.3 Objective engineering
基于目标工程的训练方式,通常不会对模型本身做太多改动 (比如 BERT 家族或者 GPT 家族),而是在损失函数上做改动,以适应输入数据。这类方法也叫做基于微调 (fine-tune) 的预训练语言模型,这类模型不仅可以进行预训练,并且训练好的词向量和模型本身可以直接投放到下游任务中,预训练的参数就是模型在下游任务中的初始点。这里我就列举几个我看过的模型。
1.3.1 BERT
同样,BERT 也可以看我以前写的博客《BERT学习笔记(4)——小白版ELMo and BERT》。
BERT 采用自监督学习的方式,学习模型与词向量。它有两个训练方式,分别为 Masked Language Model (MLM) 和 Next Sentence Prediction (NSP)。MLM 是随机选择15%的词语,对于这些词语:1) 有80%的概率将其替换为 [MASK];2) 有10%的概率将其替换为另外一个词语;3) 有10%的概率保持原样。NSP 是给定一个句子对,判断上下句是否是一个句子对,其中:1) 50%概率下句是原句;2) 50%概率下句是另外一个句子。
1.3.2 RoBERTa
RoBERTa 该模型并没有对 BERT 本身做什么操作,仅仅是证明了 NSP 并没有什么卵用。同时,在做 MLM 时,为了避免每次都掩盖相同的词语,所以他们重复了十次随机选择的过程,保证每个句子有10种掩盖方式。最后,他们还更改了训练的数据,提出了一个更具有鲁棒性的 BERT[5]。
1.3.3 ERNIE
我看过的 ERNIE 是清华大学刘知远老师团队的 ERNIE[6]。该模型将知识图谱引入到了 BERT 中,用于做命名实体预测与关系分类任务。在他们的模型中,他们将命名实体的词向量与其知识表示拼接在一起。
他们不仅采用了 MLM 与 NSP 的训练目标,还提出了 denoising entity auto-encoder (dEA) 的损失函数。该损失函数实质上就是一个 softmax,根据词语
w
i
w_i
wi 的输出层状态
w
i
o
w_i^o
wio 来预测它的实体类别
e
j
e_j
ej:
p
(
e
j
∣
w
i
)
=
e
x
p
(
l
i
n
e
a
r
(
w
i
o
)
⋅
e
j
)
∑
k
=
1
m
e
x
p
(
l
i
n
e
a
r
(
w
i
o
)
⋅
e
k
)
p(e_j|w_i)=\frac{{\rm exp}({\rm linear}(w_i^o)·e_j)}{\sum_{k=1}^m{\rm exp}({\rm linear}(w_i^o)·e_k)}
p(ej∣wi)=∑k=1mexp(linear(wio)⋅ek)exp(linear(wio)⋅ej)
这里加 linear 的目的是因为词向量与实体向量不在相同的向量空间,通过线性单元将它们映射到相同空间中。在 dEA 中:1) 对于给定的词-实体对,有5%的概率将实体替换为另一个实体,这是为了让模型能够学习到纠正错误的能力;2) 有15%的概率,将词-实体对给掩盖掉,因为系统有可能提取不出词语-实体对,这是为了让模型能够纠正这种错误;3) 80%的概率,保持不变,这是为了让模型能够更好地学习到自然语言理解。
1.3.4 SKEP
SKEP 模型是用来做方面级情感分析任务。模型中一共考虑了3类任务:情感词语识别,情感词语极性识别,以及方面级情感词语对及其情感倾向识别。对于每一个任务,有不同的掩盖方式:1) 方面级情感词语对及其情感倾向识别中,对于每个句子随机掩盖至多2个方面情感对;2) 情感词语掩盖,至多掩盖占句子词语总数10%的情感词语,选择的方式依旧是随机选择;3) 普通词语掩盖,如果情感词语占句子词语数不足10%的话,就采用 RoBERTa 的掩盖方式掩盖普通词语至10%。
1.3.5 总结
基于目标工程的模型我发现基本都是基于 Transformer 的,这类方法对模型本身的改动不是特别大,但是会依据输入数据的不同而人工去设计目标函数,使得模型能够更好地学习到我们想要的特征。同时,这类方法可以将训练好的模型直接放在下游任务中,作为起始点来进行训练。
1.4 前三种预训练语言模型总结
我们发现,前三种预训练语言模型都会有人力在里面 (feature engineering 需要人工提取特征,architecture engineering 需要人工设计网络结构,objective engineering 需要人工设计目标函数)。
2 Prompt learning
有了上面的铺垫,我们现在再来看提示学习 (prompt learning)。可能会有许多聪明的朋友会问,为什么我们要研究一个新的预训练方式?毕竟 BERT 这一套都一直在刷新 SOTA。刘鹏飞大佬在他的博客里面是这样写的[2]:
Prompt Learning激活了很多新的研究场景,比如小样本学习,这显然可以成为那些GPU资源受限研究者的福音。当然,我理解Prompt Learning最重要的一个作用在于给我们prompt(提示)了NLP发展可能的核心动力是什么。
但是于我而言,我个人觉得是:毕竟 BERT 家族天天刷榜,我不研究点新的东西我还怎么发论文?
2.1 第一次了解 prompt
与前三种预训练语言模型一样,prompt learning 同样需要人工在里面,就是人工设计 提示模板 (prompt template) 和 答案模板 (answer template)。在具体说明何为模板之前,我们先对 prompt learning 做个定义:对输入的文本信息按照特定模板进行处理,把任务重构成一个更能够充分利用预训练语言模型处理的形式。具体而言,以情感分析为例,传统情感分析是如下的:
Input: 你是个好人。
Output: positive 或 negative
而采用 prompt learning 的话,输入输出就会变为如下:
Input: 你是个好人。 那么她____和你耍朋友。
Output: 想 或者 不想
简而言之,就是将输入文本作为一个 提示 (prompt),接着拼一个语句,再让模型来对这个语句进行完形填空。进行完形填空的目的是,因为 BERT 的训练任务就是做完形填空。就是为了让下游任务更适配语言模型,而基于目标工程的预训练语言模型则是让模型去适配下游任务 (比如传统的 BERT 要做情感分析还要在输入时第一个位置添加一个 [CLS],然后输出这个 [CLS] 的隐藏状态后还要再接全连接层才能预测情感标签)。
刘鹏飞大佬的论文中贴了这么一张表格来说明这几个不同的语言模型之间的关系:
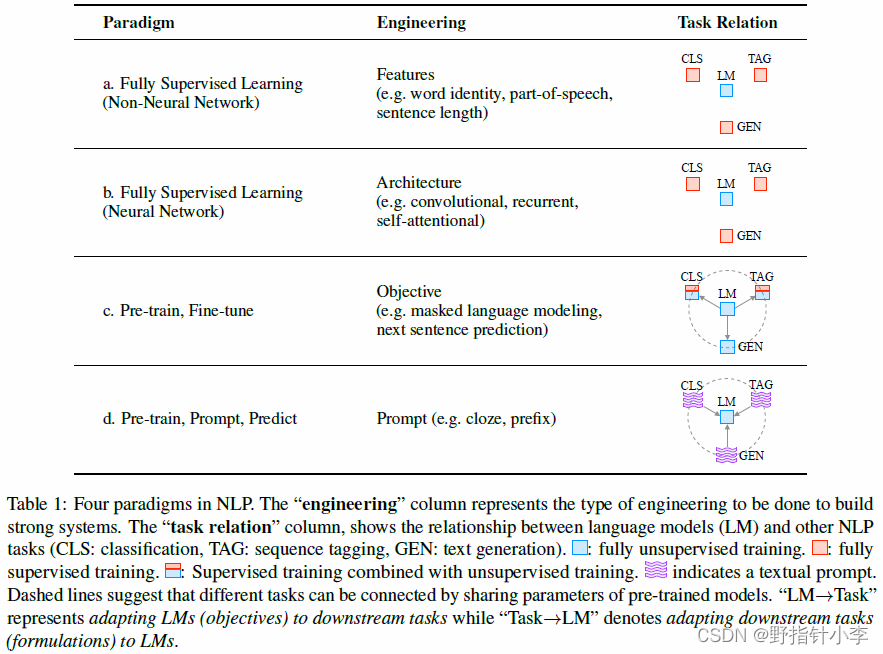
然后我们把整个 prompt 的重构方式抽象出来:1) 输入数据不变;2) 给定一个 prompt 模板;3) 给定一个答案范围。接下来我们简单讲解上述三个步骤。
2.2 Prompt 类型
在论文中,作者将 prompt 分为了两类:cloze prompt 和 prefix prompt。由于每一类 prompt 都要让下游任务满足 预训练方法,所以作者在论文里把这些方法抽象成了以下4种。
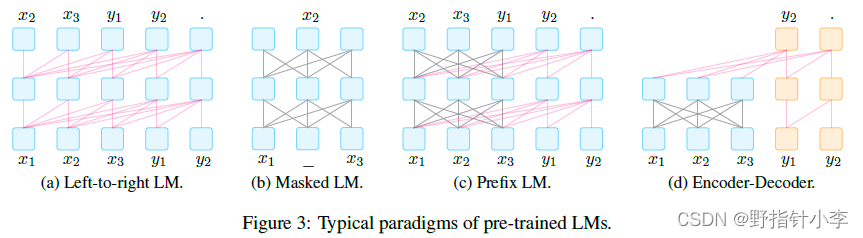
- Left-to-right LM: 详见
Transformer中的Masked self-attention[8]。 - Masked LM: 详见
Transformer中的self-attention[8]。 - Prefix LM: 这类模型我举不了例子,但是从这个模型结构来看,我们会发现
y
1
,
y
2
y_1, y_2
y1,y2 采用了Masked self-attention,而x
1
,
x
2
,
x
3
x_1, x_2, x_3
x1,x2,x3 则是采用的self-attention,那么说明在这种模型中,y
1
,
y
2
y_1, y_2
y1,y2 是需要通过x
1
,
x
2
,
x
3
x_1, x_2, x_3
x1,x2,x3 的隐藏状态来预测 (大概率是生成) 的。 - Encoder-Decoder: 典型的
Transformer,左侧self-attention,右侧Masked self-attention[8]。
有了以上4种预训练语言类型,我们再来看两类 prompt。
cloze prompt:在prompt中有插槽 (slot) 的类型为cloze prompt,这类prompt就是需要模型去填充这个slot。这类可以选用L2R LM(ELMo) 或者Masked LM(BERT) 来实现。prefix prompt:输入的文本全部在answer前的类型为prefix prompt,这类prompt通常是需要模型去预测或者生成这个slot。这类模型可以选用L2R LM(RNN),Prefix LM,以及Encoder-Decoder(GPT) 去实现。
针对不同任务的 prompt 都可以用下表展示。
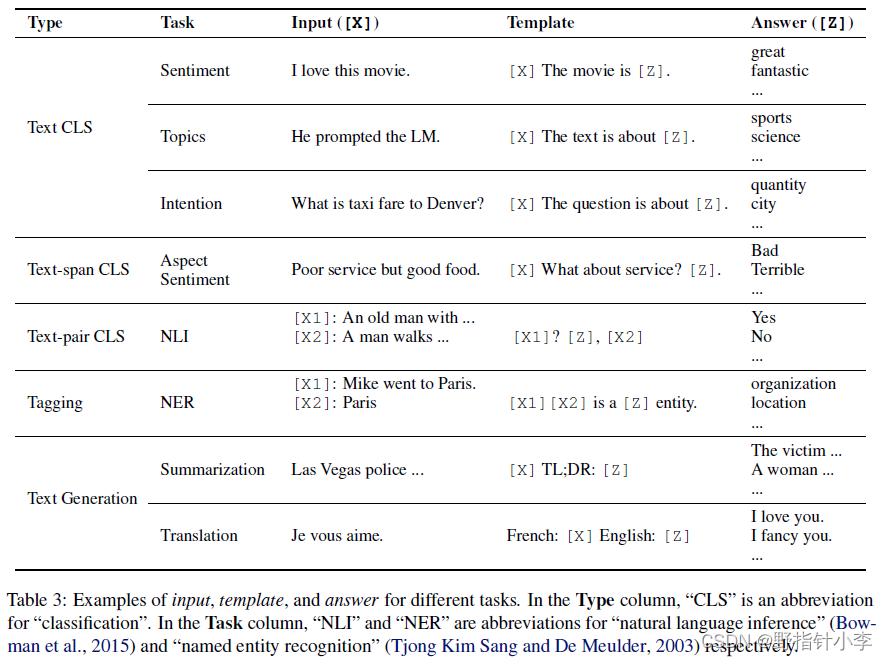
2.3 Prompt 重构的细节
在 prompt 重构的过程中,就需要两个关键的模板:prompt template 和 answer template。
2.3.1 Prompt engineering
对于 prompt template,有两种方法来生成,分别为人工设计模板和自动生成模板。
- 人工设计模板: 如上面举的例子一样,人工设计模板是最直观的方法。抽象来看,设文本为
[
X
]
[X]
[X],插槽为[
Z
]
[Z]
[Z],人工设计的模板为[
X
]
t
e
m
p
l
a
t
e
w
o
r
d
s
[
Z
]
[X]\ template\ words\ [Z]
[X] template words [Z]。但是人工设计模板有很大的缺陷,尽管这样非常直觉,易于理解,而且无需额外的计算代价,但是:1) 人工设计模板是很花费时间且需要先验知识的;2) 人工设计也会有失败的情况在内。为了解决上面的问题,就提出了通过训练的方式自动生成模板。 - 自动生成模板: 自动生成模板有两种类型。
discrete prompts (离散提示, a. k. a. hard prompts),这类型 prompts 就是让模型在一组离散模板的空间中选择一个最优的模板。continuous prompts (连续提示, a. k. a. soft prompts),这类型 prompts 就是让语言模型自动训练一个 prompts 出来。
2.3.2 Answer engineering
Answer engineering 目的是找到一个答案
[
Z
]
[Z]
[Z] 的空间,并且将这个空间映射到输出的标签
y
y
y 上。答案会有三种种类,tokens (比如文本分类),span (比如方面级情感分析中的方面识别),Sentence (比如机器翻译)。
与 prompt engineering 相同,answer engineering 同样有人工设计与自动获取两种方法。
- 人工设计答案: 人工设计分为两类
[
Z
]
[Z]
[Z] 空间。Unconstrained spaces中的[
Z
]
[Z]
[Z] 空间包含了输出空间的所有结果,token级的话则是全部词表中的词 (比如W2V的输出层),其余类型相同。这类方法可以直接找到[
Z
]
[Z]
[Z] 与y
y
y 的映射关系。Constrained spaces,这类方法通常输出是在一个限定范围内 (比如 positive 和 negative),这类方法就需要一个映射关系来映射[
Z
]
[Z]
[Z] 与y
y
y。 - 自动学习答案: 与
prompt engineering相同,有discrete answer search和continuous answer search。由于论文中也写了这类方法现在相对较少,所以我这里也就先暂时不整理这部分的内容。
2.4 多个 prompt
根据研究显示,使用多个 prompt 可以有效提升性能。 由于多个 prompt 集成后,每个 prompt 都会有一个输出,对这些输出我们也需要有相应的取舍。最简单的方法就是对每个 prompt 的输出概率求和取平均。但是这样有个问题就是可能有的 prompt 占比高,有的占比低,于是就有了带权平均方法。也有研究是采用 majority voting 的方法 (我没看过论文,但是我个人觉得就是对于分类问题,选择最多分类的那一类)。还有采用知识蒸馏和集成做文本分类的方法,这类由于不是我的研究目标,就没有了解。
而对于 prompt ensembling,有以下四种方法。
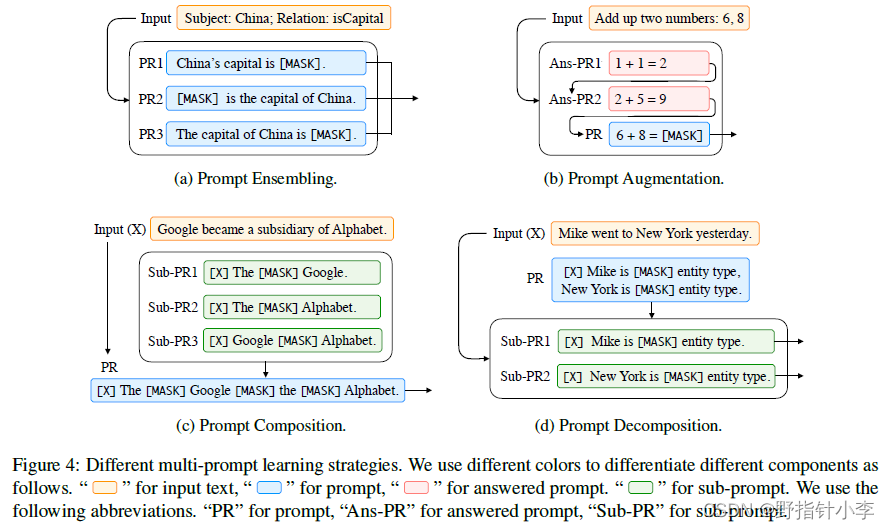
虽然我个人觉得这张图已经足够清晰了,但是我还是稍稍解释下。
Prompt ensembling:如上图 (a) 所示,就是对于一个问题用多个类似的prompt来解决。像不像写毕业论文被查重后主动句变被动句,被动句变主动句的你?Prompt augmentation:如上图 (b) 所示,这类方法可以使用少量样本来让模型学习出共性。但是该方法学者们发现有两个问题:1) 选取的例子会极大影响结果,可以上达 SOTA,下至随机猜。2)Ans的顺序也是会影响到实验结果的。Prompt composition:如上图 © 所示,就是将多个子问题组合成一个问题。论文中举的例子是关系分类问题,可以将问题先拆分成分别识别两个实体,再分析实体间的关系,然后组合起来。Prompt decomposition:如上图 (d) 所示,就是将一个困难的问题拆分成多个子问题。比如方面级情感分类中,PR1可以为方面词是___,PR2可以为该方面词的情感极性为___。
2.5 Prompt 训练方式
在论文中这个训练方式写的有点多,但是在刘大佬做 EMNLP 汇报时把这个训练方式抽象为了以下这张图:
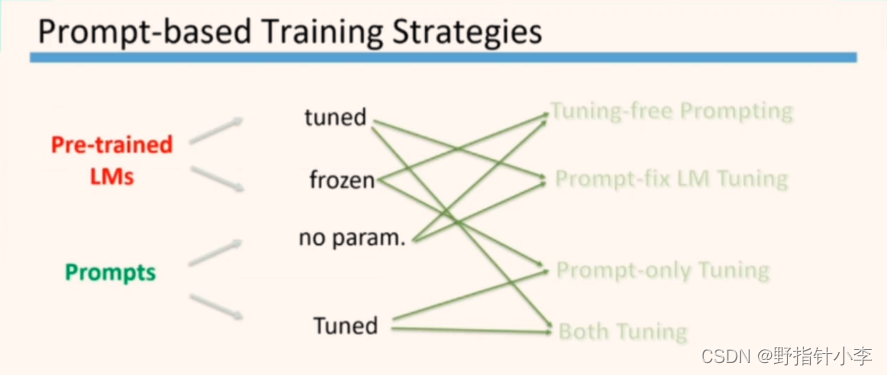
整个 prompt 的训练分为两部分,LM 的训练和 prompts 的训练。两者都有不训练和训练两种方式,所以就组合为了4种情况:
- prompts 没有参数,LM 也不参与训练。
- prompts 需要训练,LM 不参与训练 (毕竟 GPT 不是穷人配用的)。
- prompts 没有参数,LM 进行微调。
- prompts 需要训练,LM 也要进行微调。
3 总结
由于我也才开始学习 prompt learning,所以在此写下这个笔记方便才开始学习的人有个最直观的了解。但是由于看的相关论文还是太少了,所以并不能够总结出一个很完善的博客,并且许多部分也写得相对粗糙,如果想了解更多的信息,可以多多阅读刘鹏飞大佬的论文[1]。
参考
[1] LIU P, YUAN W, FU J, et al. Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing [J]. CoRR, 2021, abs/2107.13586.
[2] 刘鹏飞. 近代自然语言处理技术发展的“第四范式”[EB/OL]. (2021-08-01)[2022-01-03]. https://zhuanlan.zhihu.com/p/395115779
[3] 木尧の. CMU刘鹏飞 | Prompt学习的最新研究趋势分析[EB/OL]. (2021-11-06)[2022-01-03]. https://www.bilibili.com/video/BV1zf4y1u7og?share_source=copy_web
[4] JOULIN A, GRAVE E, BOJANOWSKI P, et al. Bag of Tricks for Efficient Text Classification [C]. Proceeding of the 15th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2017, April 3, 2017 – April 7, 2017, Valencia, Spain: Association for Computational Linguistics (ACL), 2017: 427-431.
[5] LIU Y, OTT M, GOYAL N, et al. RoBERTa: A Robustly Optimized BERT Pretraining Approach [J]. CoRR, 2019, abs/1907.11692.
[6] ZHANG Z, HAN X, LIU Z, et al. ERNIE: Enhanced Language Representation with Informative Entities [C]. Proceeding of the 57th Annual Meeting of the Association for Computational Linguistics, ACL 2019, July 28, 2019 – August 2, 2019, Florence, Italy: Association for Computational Linguistics (ACL), 2020: 1441-1451.
[7] TIAN H, GAO C, XIAO X, et al. SKEP: Sentiment Knowledge Enhanced Pre-Training for Sentiment Analysis [C]. Proceeding of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, July 5, 2020 – July 10, 2020, Virtual, Online, United states: Association for Computational Linguistics (ACL), 2020: 4067-4076.
[8] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is All You Need [C]. Proceeding of the 31st Annual Conference on Neural Information Processing Systems, NIPS 2017, December 4, 2017 – December 9, 2017, Long Beach, CA, United states: Neural information processing systems foundation, 2017: 5999-6009.