本博客主要记录笔试中常考的一些知识点或者技巧。
1. 各类Java容器的用法
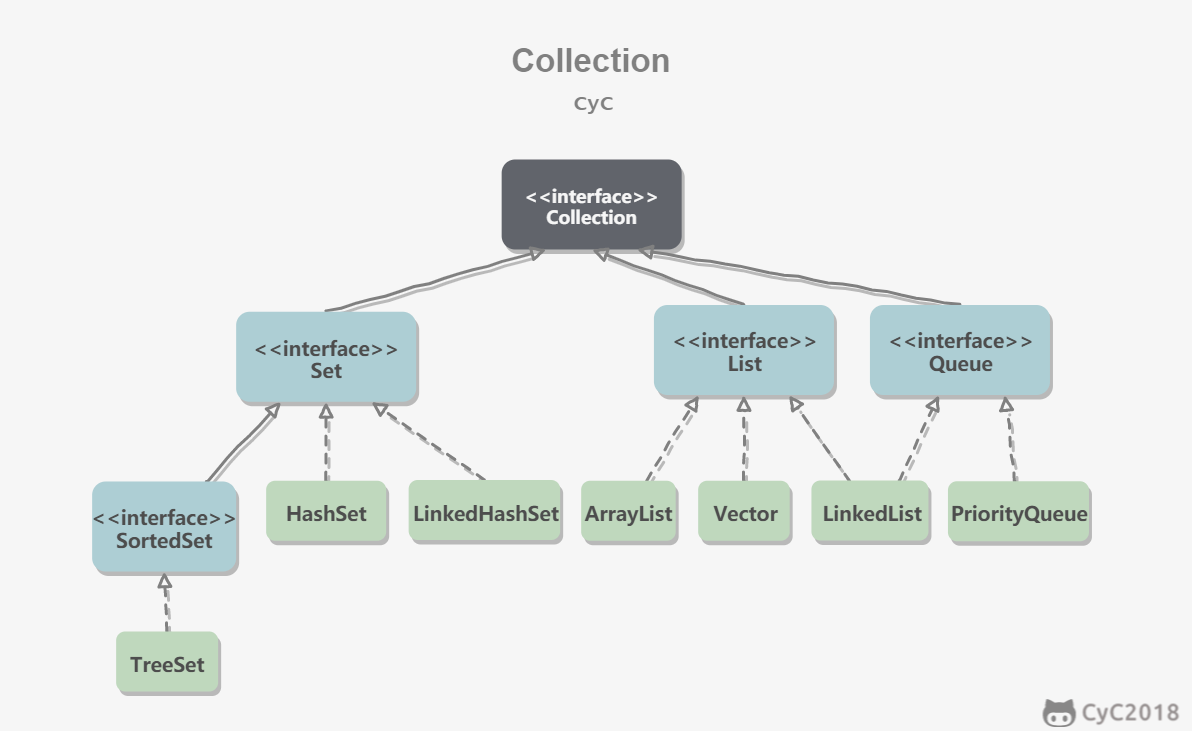
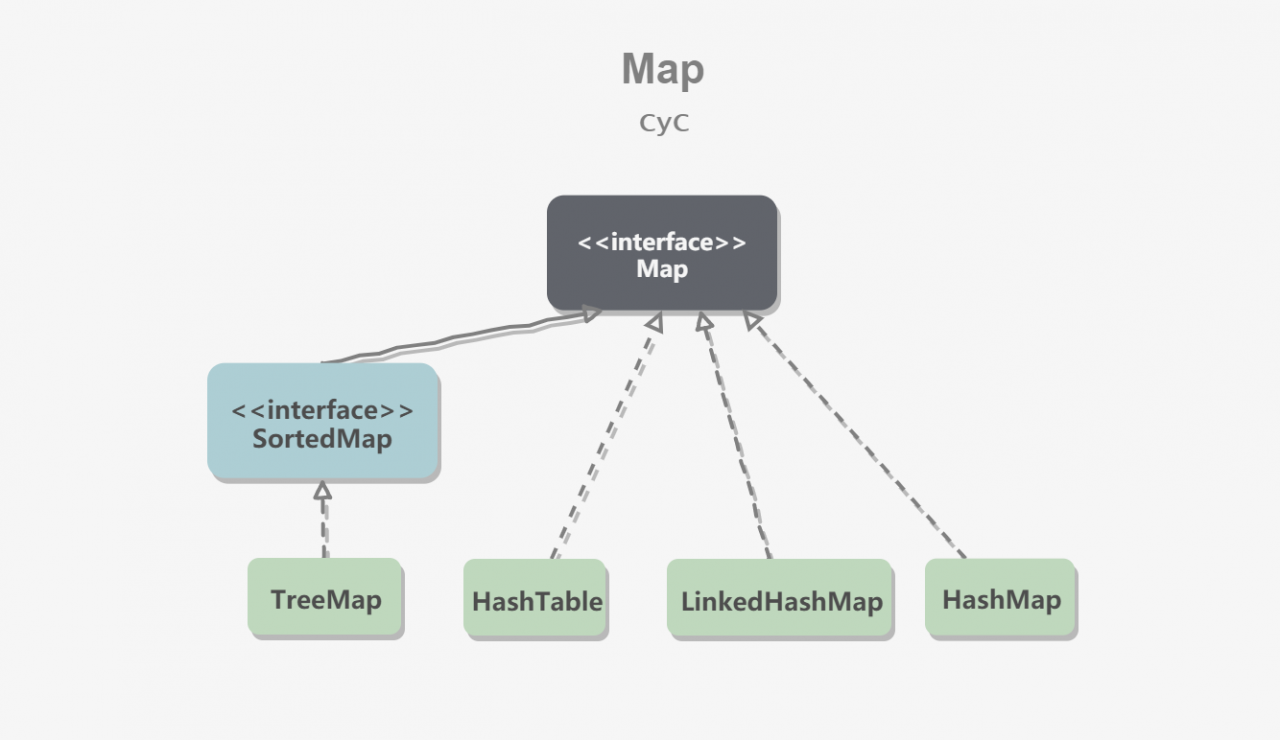
图片:https://github.com/CyC2018/CS-Notes/blob/master/notes/Java%20%E5%AE%B9%E5%99%A8.md
数组
数组是很基础的一种数据结构,这里我指记录数组在做题中的一些小用途。
public static void main(String[] args) {
//两种数组初始化赋值的方法
Integer[] nums = {1, 2 ,3};
nums = new Integer[]{1, 2, 4, 3};
//数组从小到大排序
Arrays.sort(nums);
//数组从大到小排序
Arrays.sort(nums, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2.compareTo(o1);
}
});
//把数组转化成流再操作
Arrays.stream(nums).forEach((ele)-> System.out.println(ele));
// 4
// 3
// 2
// 1
//把数组转化成List
List<Integer> list = Arrays.asList(nums);
}
List
List用的最多的是ArrayList和LinkedList,ArrayList底层实现是数组,LinkedList底层实现是双向链表,此处指介绍容器用法,原理可参考:https://github.com/CyC2018/CS-Notes/blob/master/notes/Java%20%E5%AE%B9%E5%99%A8.md。
1. ArrayList
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("aaa");
list.add("ccc");
list.add("bbb");
//get获取下标对应值
System.out.println(list.get(1));
//set修改下标对应值
list.set(1, "ddd");
//list转数组
//这里如果没有传入String数组,返回的就是Object数组
String[] str = list.toArray(new String[list.size()]);
//addAll将其他容器的元素放到List中
Set<String> set = new TreeSet<>();
set.add("aaa");
set.add("ccc");
set.add("bbb");
list.addAll(set);
System.out.println(list);
// [aaa, ddd, aaa, bbb, ccc]
//sort排序
Collections.sort(list);
//forEach遍历
list.forEach((ele)-> System.out.println(ele));
}
2. LinkedList
LinkedList和ArrayList有部分方法同名(虽然实现不一样),此处只列出LinkedList特有的方法。
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<>();
list.add("aaa");
list.add("ccc");
list.add("bbb");
list.addFirst("1");
list.addLast("9");
list.removeFirst();
list.removeLast();
}
Map
1. HashMap
最常用的Map是HashMap,此处只列出基本用法。
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("aaa", 1);
map.put("bbb", 3);
map.put("ccc", 2);
//判断是否有key,返回boolean
boolean contain = map.containsKey("bbb");
//判断是否有key,有则返回value,否则返回null
System.out.println(map.get("ddd"));
//判断是否有key,有则返回value,否则返回defaultValue
map.getOrDefault("ddd", 0);
}
2. LinkedHashMap
LinkedHashMap是LinkedList和HashMap的结合体,在对Map进行插入的时候,可以记录下其插入顺序。查找时使用HashMap来查找,时间复杂度为O(1),插入时同时加入HashMap和LinkedList,LinkedList记录插入顺序。
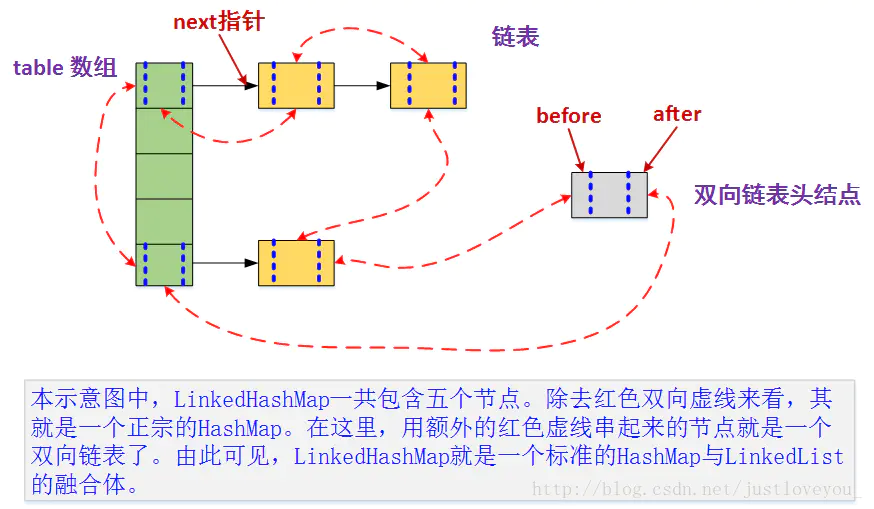
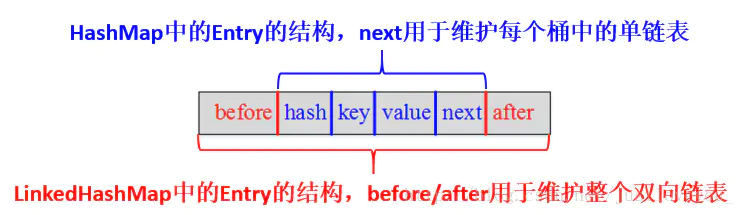
图片:https://www.jianshu.com/p/cb3573eb1890
在使用的时候,和HashMap区别不大,只是它会保存插入顺序而已。
public static void main(String[] args) {
LinkedHashMap<String, Integer> map = new LinkedHashMap<>();
map.put("aaa", 1);
map.put("bbb", 3);
map.put("ccc", 2);
//流+forEach
map.entrySet().stream().forEach( (entry) ->{
System.out.println(entry.getKey()+" "+entry.getValue());
});
//for
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey()+" "+entry.getValue());
}
//iterator
Iterator<Map.Entry<String, Integer>> iterator = map.entrySet().iterator();
while (iterator.hasNext()){
Map.Entry<String, Integer> entry = iterator.next();
System.out.println(entry.getKey()+" "+entry.getValue());
}
}
同时,LinkedHashMap可以用于实现LRU,只要把accessOrder=true即可。
class LRUCache extends LinkedHashMap {
private int capacity;
public LRUCache(int capacity) {
//accessOrder为true
super(capacity, 0.75F, true);
this.capacity = capacity;
}
public int get(int key) {
return (int)super.getOrDefault(key, -1);
}
public void put(int key, int value) {
super.put(key, value);
}
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > capacity;
}
}
3. TreeMap
TreeMap同样是一个有序的Map,它是基于红黑树实现的。只要将key-value放入TreeMap,就会基于所有的key-value进行排序,使得TreeMap始终有序。默认情况下,TreeMap基于key进行由小到大的排序,排序规则可以自定义,只要在创建TreeMap时重写Comparator即可。另外,TreeMap是非同步的。 它的iterator 方法返回的迭代器是fail-fast的。
public static void main(String[] args) {
TreeMap<Integer, Integer> map = new TreeMap<>();
map.put(1, 1);
map.put(3, 3);
map.put(2, 2);
//流+forEach
map.entrySet().stream().forEach( (entry) ->{
System.out.println(entry.getKey()+" "+entry.getValue());
});
// 输出
// 1 1
// 2 2
// 3 3
}
修改Comparator,使得TreeMap降序排列。
public static void main(String[] args) {
TreeMap<Integer, Integer> map = new TreeMap<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
//降序排序
return o2.compareTo(o1);
}
});
map.put(1, 1);
map.put(3, 3);
map.put(2, 2);
//流+forEach
map.entrySet().stream().forEach( (entry) ->{
System.out.println(entry.getKey()+" "+entry.getValue());
});
// 输出
// 3 3
// 2 2
// 1 1
}
Set
1. HashSet
HashSet是最常用的set,元素不重复,不保证顺序,允许有null值,非线程安全。本质上是以HashMap作为底层实现的。
public static void main(String[] args) {
Set<String> set = new HashSet<String>();
set.add("aaa");
set.add("bbb");
set.add("ccc");
set.add("aaa");
System.out.println(set);
//[aaa, ccc, bbb]
//判断元素是否存在,返回boolean
boolean a = set.contains("aaa");
//删除元素
set.remove("ccc");
//清除元素
set.clear();
//去重后加入List
ArrayList<String> list = new ArrayList<>(set);
list.clear();
//或者用addAll加入List
list.addAll(set);
}
2. LinkedHashSet
LinkedHashSet能保证有序,按照第一次加入的顺序,后面重复的元素不影响顺序。本质上是以HashMap和双向链表作为底层实现的。
public static void main(String[] args) {
LinkedHashSet<String> set = new LinkedHashSet<String>();
set.add("hello");
set.add("world");
set.add("java");
set.add("hello");
set.add("world");
set.forEach((ele) -> System.out.println(ele));
// hello
// world
// java
}
3. TreeSet
TreeSet提供有序的集合,和TreeMap非常相似。TreeSet是基于TreeMap实现的。TreeSet中的元素支持2种排序方式:自然排序 或者 根据创建TreeSet 时提供的 Comparator 进行排序。这取决于使用的构造方法。
public static void main(String[] args) {
Set<String> set = new TreeSet<>();
set.add("aaa");
set.add("ccc");
set.add("bbb");
set.add("aaa");
System.out.println(set);
//[aaa, bbb, ccc]
}
Stack
Stack遵循后进先出的原则,只对栈顶进行操作。Java官方建议使用Deque(双端队列)实现栈的数据结构,即ArrayDeque和LinkedList,而不是用Stack。这是因为Stack继承了Vector,有Vector的方法可以进行随机访问和动态扩容,这破坏了栈的封装。
public static void main(String[] args) {
Deque<Integer> stack = new LinkedList<>();
//push
stack.push(1);
stack.push(2);
//pop
Integer pop = stack.pop();
System.out.println(pop);
//获取栈顶元素,但不出栈
Integer peek = stack.peek();
System.out.println(peek);
//判断是否为空
boolean empty = stack.isEmpty();
System.out.println(empty);
}
Queue
队列是一种先进先出的数据结构,队尾入队,队头出队。
public static void main(String[] args) {
Queue<Integer> queue = new LinkedList<>();
//队尾插入元素,如果队列已满,则返回false
//add能达到类似效果,只是add队满时会抛出IIIegaISlabEepeplian异常
queue.offer(1);
queue.offer(2);
queue.offer(3);
//队头移除元素,如果队列已空,则返回null
//remove能达到类似效果,只是remove队空时会抛出NoSuchElementException异常
Integer poll = queue.poll();
//返回队头元素,但不移除
//element能达到类似效果,只是element队空时会抛出NoSuchElementException异常
Integer peek = queue.peek();
}
1. PriorityQueue
PriorityQueue指的是优先队列,采用的是堆排序,维护着一个堆,默认是最小堆(每个堆的节点都比其左右子节点要小),因此可以用于取得最值/排序等用途。
队列既可以根据元素的自然顺序来排序,也可以根据 Comparator来设置排序规则。队列的头是按指定排序方式的最小元素。如果多个元素都是最小值,则头是其中一个元素。新建对象的时候可以指定一个初始容量,其容量会自动增加。
- PriorityQueue是用数组实现的最小堆,但是数组可以动态增加。
- 队列的实现不是同步的。不是线程安全的。如果多个线程中的任意线程从结构上修改了列表, 则这些线程不应同时访问 PriorityQueue实例。保证线程安全可以使用PriorityBlockingQueue 类。
- 不允许使用 null 元素。
- 插入方法(offer()、poll()、remove() 、add() 方法)时间复杂度为O(log(n)) ;remove(Object) 和 contains(Object) 时间复杂度为O(n);检索方法(peek、element 和 size)时间复杂度为常量。
- 方法iterator()中提供的迭代器并不保证以有序的方式遍历优先级队列中的元素。(原因可参考PriorityQueue的内部实现)堆排序只能保证根是最大(最小),整个堆并不是有序的。如果需要按顺序遍历,可用Arrays.sort(pq.toArray())。
- 可以在构造函数中指定如何排序,创建PriorityQueue时放入自定义Comparator即可。
public static void main(String[] args) {
Queue<Integer> queue = new PriorityQueue<>();
queue.offer(3);
queue.offer(1);
queue.offer(2);
queue.offer(4);
queue.offer(2);
int size = queue.size();
for (int i = 0; i < size; i++) {
System.out.println(queue.poll());
}
//注意!不要使用forEach或for(Integer ele: queue)的方法
//因为优先队列并非完全排序,而是每次取出一个最小值后重新调整排序
//如果使用forEach,那么集合就会保持一开始的顺序,导致排序失败
//应该像上面代码那样依次取出,让优先队列自行调整堆
}
自定义排序,队列中放数组,根据数组下标0、下标1比大小的先后顺序排序。
public static void main(String[] args) {
Queue<Integer[]> queue = new PriorityQueue<>(new Comparator<Integer[]>() {
@Override
public int compare(Integer[] o1, Integer[] o2) {
if(o1[0].compareTo(o2[0])==0){
return o1[1].compareTo(o2[1]);
} else{
return o1[0].compareTo(o2[0]);
}
}
});
queue.offer(new Integer[]{1,2});
queue.offer(new Integer[]{1,3});
queue.offer(new Integer[]{2,2});
queue.offer(new Integer[]{2,3});
int size = queue.size();
for (int i = 0; i < size; i++) {
Integer[] poll = queue.poll();
System.out.println(poll[0] + " " + poll[1]);
}
// 1 2
// 1 3
// 2 2
// 2 3
}
参考:https://blog.csdn.net/ohwang/article/details/116934308
2. Java根据Map的值进行排序
a. 根据流的方式实现
public static void main(String[] args) {
HashMap<Integer, Integer> maps = new HashMap<>();
maps.put(1, 22);
maps.put(4, 24);
maps.put(2, 18);
maps.put(3, 22);
//将EntrySet变成流后排序,重写compare方法,再collect成为List
List<Map.Entry<Integer, Integer>> list = maps.entrySet().stream().sorted(new Comparator<Map.Entry<Integer, Integer>>() {
@Override
public int compare(Map.Entry<Integer, Integer> o1, Map.Entry<Integer, Integer> o2) {
return o1.getValue().compareTo(o2.getValue());
}
}).collect(Collectors.toList());
//使用LinkedHashMap保存插入顺序,即排序顺序,将列表放入Map中
LinkedHashMap<Integer, Integer> sortedMap = new LinkedHashMap<>();
list.forEach((o1) -> sortedMap.put(o1.getKey(), o1.getValue()));
System.out.println(sortedMap);
}
b. 根据列表排序方式实现
public static void main(String[] args) {
HashMap<Integer, Integer> maps = new HashMap<>();
maps.put(1, 22);
maps.put(4, 24);
maps.put(2, 18);
maps.put(3, 22);
//将EntrySet放入List中,对List排序,再放到LinkedHashMap中保存顺序
ArrayList<Map.Entry<Integer, Integer>> list = new ArrayList<>(maps.entrySet());
Collections.sort(list, new Comparator<Map.Entry<Integer, Integer>>() {
@Override
public int compare(Map.Entry<Integer, Integer> o1, Map.Entry<Integer, Integer> o2) {
return o1.getValue().compareTo(o2.getValue());
}
});
LinkedHashMap<Integer, Integer> sortedMap = new LinkedHashMap<>();
list.forEach((o1) -> sortedMap.put(o1.getKey(), o1.getValue()));
System.out.println(sortedMap);
}
3. 判断素数
如果一个数只能被1和它本身整除,那么这个数就是一个素数。判断一个数是否为素数只能循环遍历判断能否整除,但是这个循环可以被优化。
- 偶数肯定不是素数,所以在遍历的时候只遍历奇数即可。
- 如果这个数n可以被整除,那么这一对可以整除的因子肯定一个大于等于根号n,另一个小于根号n。因此,在遍历的时候,只需要遍历到根号n即可。由于素数不可能是小数,那么把根号n做int处理作为边界即可。
public static boolean isPrime(int n){
if(n%2==0) return false;
int sqrt = (int)Math.sqrt(n);
for (int i = 3; i <= sqrt; i+=2) {
if(n%i==0){
return false;
}
}
return true;
}