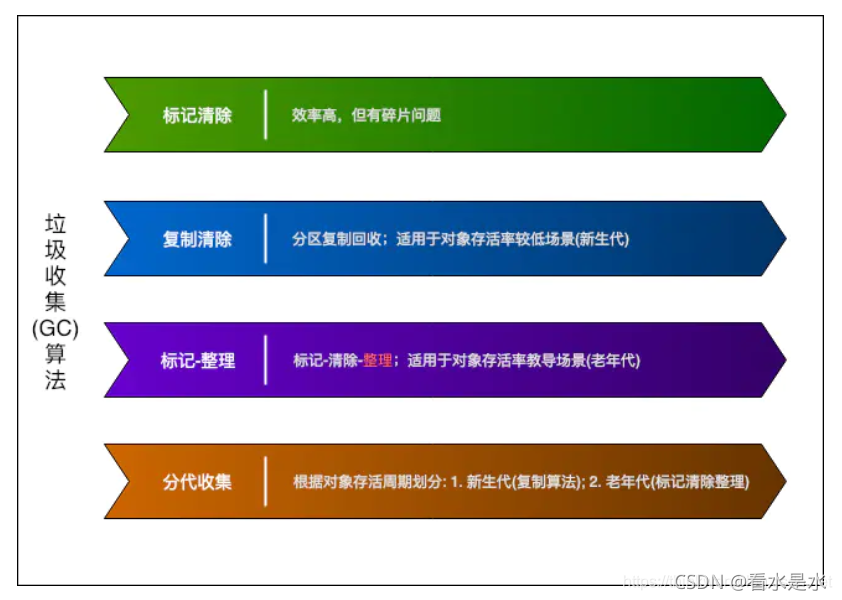
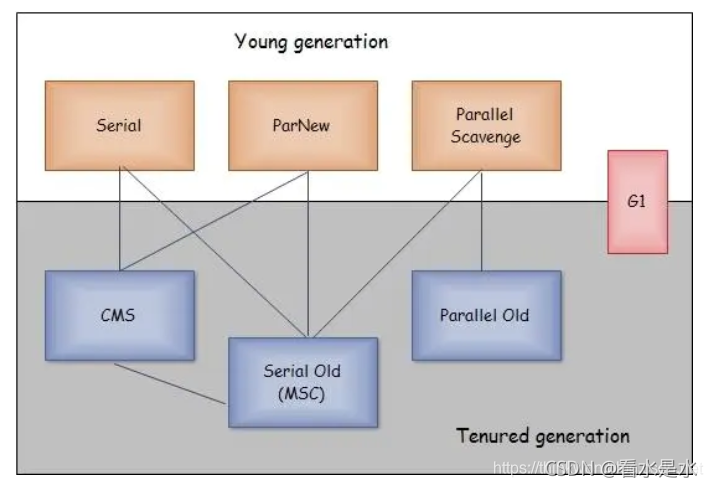
Serial收集器(复制算法): 新生代单线程收集器,标记和清理都是单线程,优点是简单高效;
ParNew收集器 (复制算法): 新生代收并行集器,实际上是Serial收集器的多线程版本,在多核CPU环境下有着比Serial更好的表现;
Parallel Scavenge收集器 (复制算法): 新生代并行收集器,追求高吞吐量,高效利用 CPU。吞吐量 = 用户线程时间/(用户线程时间+GC线程时间),高吞吐量可以高效率的利用CPU时间,尽快完成程序的运算任务,适合后台应用等对交互相应要求不高的场景;
Serial Old收集器 (标记-整理算法): 老年代单线程收集器,Serial收集器的老年代版本;
Parallel Old收集器 (标记-整理算法): 老年代并行收集器,吞吐量优先,Parallel Scavenge收集器的老年代版本;
CMS(Concurrent Mark Sweep)收集器(标记-清除算法): 老年代并行收集器,以获取最短回收停顿时间为目标的收集器,具有高并发、低停顿的特点,追求最短GC回收停顿时间。
G1(Garbage First)收集器 (标记-整理算法): Java堆并行收集器,G1收集器是JDK1.7提供的一个新收集器,G1收集器基于“标记-整理”算法实现,也就是说不会产生内存碎片。此外,G1收集器不同于之前的收集器的一个重要特点是:G1回收的范围是整个Java堆(包括新生代,老年代),而前六种收集器回收的范围仅限于新生代或老年代。
版权声明:本文为yuhuochongsheng_原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。