-
kNN是一个基本而简单的分类算法,作为监督学习,那么KNN模型需要的是有标签的训练数据,对于新样本的类别由与新样本距离最近的k个训练样本点按照分类决策规则决定。k近邻法1968年由Cover和Hart提出。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。k近邻法不具有显式的学习过程。它是懒惰学习(lazy learning)的著名代表,此类学习技术在训练阶段仅仅是把样本保存起来,训练时间开销为零,待收到测试样本后再进行处理。
-
K最近邻(K-Nearest Neighbor,KNN)分类算法是数据挖掘分类技术中最简单的方法之一,是著名的模式识别统计学方法,在机器学习分类算法中占有相当大的地位。它是一个理论上比较成熟的方法。既是最简单的机器学习算法之一,也是基于实例的学习方法中最基本的,又是最好的文本分类算法之一。思路是:如果一个样本在特征空间中的k个最邻近的样本中的大多数属于某一个类别,则该样本也划分为这个类别。 KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
-
该算法假定所有的实例对应于N维欧式空间Ân中的点。通过计算一个点与其他所有点之间的距离,取出与该点最近的K个点,然后统计这K个点里面所属分类比例最大的,则这个点属于该分类。
-
KNN是通过测量不同特征值之间的距离进行分类。基本做法的三个要点是:
-
第一,确定距离度量;
-
第二,k值的选择(找出训练集中与带估计点最靠近的k个实例点);
-
第三,分类决策规则。
-
-
如果选择较小的K值,就相当于用较小的领域中的训练实例进行预测,“学习”近似误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是“学习”的估计误差会增大,换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
-
如果选择较大的K值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且K值的增大就意味着整体的模型变得简单。
-
K=N,则完全不足取,因为此时无论输入实例是什么,都只是简单的预测它属于在训练实例中最多的类,模型过于简单,忽略了训练实例中大量有用信息。
-
在实际应用中,K值一般取一个比较小的数值,例如采用 交叉验证法(简单来说,就是一部分样本做训练集,一部分做测试集)来选择最优的K值。
-
在 分类 任务中可使用“投票法”,即选择这k个实例中出现最多的标记类别作为预测结果;
-
在 回归 任务中可使用“平均法”,即将这k个实例的实值输出标记的平均值作为预测结果;
-
还可基于距离远近进行加权平均或加权投票,距离越近的实例权重越大。
k近邻算法中特征归一化的重要性
-
k近邻算法是在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,我们就说预测点属于哪个类。定义中所说的最邻近是如何度量呢?我们怎么知道谁跟测试点最邻近。这里就会引出我们几种度量俩个点之间距离的标准。
- 假设特征空间
X
\mathcal{X}
X是n维实数向量空间R
n
R^n
Rn,x
i
,
x
j
∈
X
,
x
i
=
(
x
i
(
1
)
,
x
i
(
2
)
,
.
.
.
,
x
i
(
n
)
)
T
,
x
j
=
(
x
j
(
1
)
,
x
j
(
2
)
,
.
.
.
,
x
j
(
n
)
)
T
x_i,x_j\in\mathcal{X},x_i=(x^{(1)}_i,x^{(2)}_i,…,x^{(n)}_i)^T,x_j=(x^{(1)}_j,x^{(2)}_j,…,x^{(n)}_j)^T
xi,xj∈X,xi=(xi(1),xi(2),…,xi(n))T,xj=(xj(1),xj(2),…,xj(n))T,则Lp的距离定义为P范数:
- 假设特征空间
-
L
p
(
x
i
,
x
j
)
=
(
∑
l
=
1
n
∣
x
i
(
l
)
−
x
j
(
l
)
∣
2
)
1
p
L_p(x_i,x_j)=(\sum^n_{l=1}|x_i^{(l)}-x_j^{(l)}|^2)^\frac{1}{p}
Lp(xi,xj)=(l=1∑n∣xi(l)−xj(l)∣2)p1
-
p大于等于1,p=1时为曼哈顿距离,其中当p=2的时候,就是我们最常见的欧式距离,我们也一般都用欧式距离来衡量我们高维空间中俩点的距离。在实际应用中,距离函数的选择应该根据数据的特性和分析的需要而定,一般选取p=2欧式距离表示。
-
特征归一化的必要性
-
首先举例如下,我用一个人身高(cm)与脚码(尺码)大小来作为特征值,类别为男性或者女性。我们现在如果有5个训练样本,分布如下:
- A [(179,42),男] B [(178,43),男] C [(165,36)女] D [(177,42),男] E [(160,35),女]
-
很容易看到第一维身高特征是第二维脚码特征的4倍左右,那么在进行距离度量的时候,我们就会偏向于第一维特征。这样造成俩个特征并不是等价重要的,最终可能会导致距离计算错误,从而导致预测错误。口说无凭,举例如下:现在我来了一个测试样本 F(167,43),让我们来预测他是男性还是女性,我们采取k=3来预测。下面我们用欧式距离分别算出F离训练样本的欧式距离,然后选取最近的3个,多数类别就是我们最终的结果,计算如下:
-
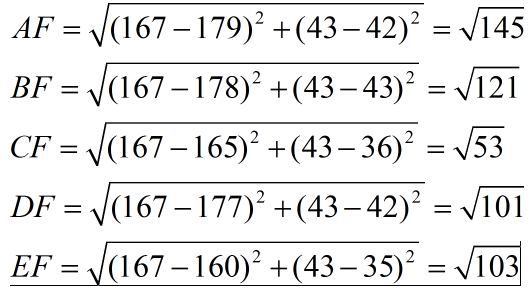
-
由计算可以得到,最近的前三个分别是C,D,E三个样本,那么由C,E为女性,D为男性,女性多于男性得到我们要预测的结果为女性。这样问题就来了,一个女性的脚43码的可能性,远远小于男性脚43码的可能性,那么为什么算法还是会预测F为女性呢?那是因为由于各个特征量纲的不同,在这里导致了身高的重要性已经远远大于脚码了,这是不客观的。所以我们应该让每个特征都是同等重要的!这也是我们要归一化的原因!归一化有:最大最小标准化(Min-Max Normalization),z—score 标准化,log对数函数归一化,反正切函数归一化,L2范数归一化…
-
如果对输出结果范围有要求,用归一化。如果数据较为稳定,不存在极端的最大最小值,用归一化。如果数据存在异常值和较多噪音,用标准化,可以间接通过中心化避免异常值和极端值的影响。
-
数据的归一化和标准化是特征缩放(feature scaling)的方法,是数据预处理的关键步骤。不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据归一化/标准化处理,以解决数据指标之间的可比性。原始数据经过数据归一化/标准化处理后,各指标处于同一数量级,适合进行综合对比评价。归一化/标准化实质是一种线性变换,线性变换有很多良好的性质,这些性质决定了对数据改变后不会造成“失效”,反而能提高数据的表现,这些性质是归一化/标准化的前提。比如有一个很重要的性质:线性变换不会改变原始数据的数值排序。
-
使用KNN完成鸢尾花分类任务
-
1
-
from matplotlib import pyplot as plt # 绘图 from matplotlib.colors import ListedColormap from sklearn import datasets from sklearn.model_selection import train_test_split import numpy as np from sklearn.neighbors import KNeighborsClassifier iris = datasets.load_iris() # 加载数据,第一次加载需要联网 print(iris['data'].shape, iris['target'].shape) # (150, 4) (150,) X = iris.data[:,[2,3]] y = iris.target print('Class labels:', np.unique(y)) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1, stratify=y) print(X_train.shape, y_train.shape) -
(150, 4) (150,) Class labels: [0 1 2] (105, 2) (105,) -
训练,并绘制分类决策边界:
-
def plot_decision_regions(X, y, classifier, test_idx=None, resolution=0.02): # setup marker generator and color map markers = ('s', 'x', 'o', '^', 'v') colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan') cmap = ListedColormap(colors[:len(np.unique(y))]) # plot the decision surface x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1 x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1 xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution), np.arange(x2_min, x2_max, resolution)) Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T) Z = Z.reshape(xx1.shape) plt.contourf(xx1, xx2, Z, alpha=0.3, cmap=cmap) plt.xlim(xx1.min(), xx1.max()) plt.ylim(xx2.min(), xx2.max()) for idx, cl in enumerate(np.unique(y)): plt.scatter(x=X[y == cl, 0], y=X [y == cl, 1], alpha=0.8, c=colors[idx], marker=markers[idx], label=cl, edgecolor='black') # highlight test samples if test_idx: # plot all samples X_test, y_test = X[test_idx, :], y[test_idx] plt.scatter(X_test[:, 0], X_test[:, 1], edgecolor='black', alpha=1.0, linewidth=1, marker='o', s=100, label='test set') # 标准化数据 from sklearn.preprocessing import StandardScaler sc = StandardScaler() # 标准化函数实例化 sc.fit(X_train) # 实际运用标准化函数处理训练集数据 X_train_std = sc.transform(X_train) X_test_std = sc.transform(X_test) X_combined_std = np.vstack((X_train_std, X_test_std)) y_combined = np.hstack((y_train, y_test)) # 训练,k=5, 距离度量为 knn = KNeighborsClassifier(n_neighbors=5, p=2, metric='minkowski') knn.fit(X_train_std, y_train) print('Training accuracy:', knn.score(X_train_std, y_train)) print('Testing accuracy:', knn.score(X_test_std, y_test)) -
Training accuracy: 0.9714285714285714 Testing accuracy: 1.0
-
-
绘制决策边界
-
plot_decision_regions(X_combined_std, y_combined, classifier=knn, test_idx=range(105,150)) plt.xlabel('petal length [standardized]') plt.ylabel('petal width [standardized]') plt.legend(loc='upper left') plt.show() -
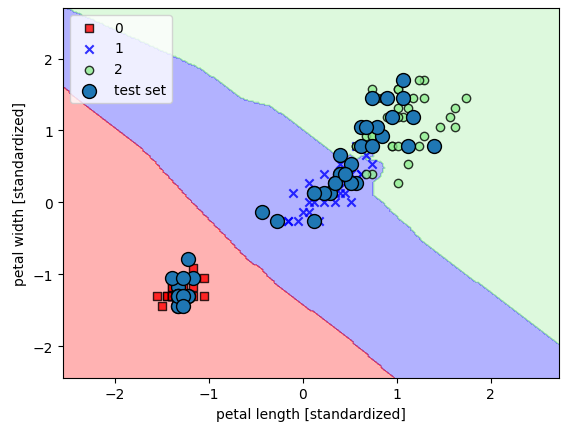
-
KD树(数据量过大,维度过多的时候的一种优化)
-
当训练集很大时,计算输入实例和每一个训练实例的距离相当耗时。为了提高 k 近邻搜索的效率,我们使用特殊的结构存储训练数据来减少计算距离的次数,比如 kd 树方法。 kd树(k-dimension tree)是一种对 k 维空间中的实例点进行存储以便对其进行快速检索的二叉树形数据结构。构造 kd 树相当于不断用垂直于坐标轴的超平面将 k 维空间切分,构成一系列的 k 维超矩形区域, kd 树上的每一个结点对应于一个 k 维超矩形区域。该超矩形区域垂直于当前划分维度的坐标轴,并在该维度上将空间划分为两部分。
-
Kd-树是K-dimension tree的缩写,是对数据点在k维空间(如二维(x,y),三维(x,y,z),k维(x1,y,z…))中划分的一种数据结构,主要应用于多维空间关键数据的搜索(如:范围搜索和最近邻搜索)。本质上说,Kd-树就是一种平衡二叉树。
-
首先必须搞清楚的是,k-d树是一种空间划分树,说白了,就是把整个空间划分为特定的几个部分,然后在特定空间的部分内进行相关搜索操作。想像一个三维(多维有点为难你的想象力了)空间,kd树按照一定的划分规则把这个三维空间划分了多个空间,如下图所示:
-
构造KD树:
-
输入: k 维空间数据集
T
=
x
1
,
x
2
,
.
.
.
,
x
n
,
T=x_1,x_2,…,x_n,
T=x1,x2,…,xn,
,其中x
i
=
(
x
i
(
1
)
,
x
i
(
2
)
,
.
.
.
,
x
i
(
k
)
)
T
x_i=(x^{(1)}_i,x^{(2)}_i,…,x^{(k)}_i)^T
xi=(xi(1),xi(2),…,xi(k))T ;输出: KD 树。( 树的思想和二分法很像,并且都能提高搜索的效率)
-
- 构造对应包含 T 的 k 维空间的超矩形区域:以
x
(
1
)
x^{(1)}
x(1) 为坐标轴, T 中所有实例的x
(
1
)
x^{(1)}
x(1) 坐标的中位数为切分点将超矩形区域划分为两个子区域。此步生成深度为1的左、右结点:左子结点对应坐标x
(
1
)
x^{(1)}
x(1) 小于切分点的子区域,右子结点对应于坐标 大于切分点的子区域。正好落在划分超平面上的实例点保存在根结点。 - 同样地,对深度为 j 的结点,选择
x
(
l
)
x^{(l)}
x(l)为切分的坐标轴(l
=
j
(
m
o
d
k
)
+
1
l=j(mod~k)+1
l=j(mod k)+1 ,因为可能存在对同个维度进行多次划分),以该结点的区域中所有实例的x
(
l
)
x^{(l)}
x(l) 坐标的中位数为切分点划分结点对应的超矩形区域。 - 直到两个子区域没有实例存在时停止。
- 构造对应包含 T 的 k 维空间的超矩形区域:以
-
-
搜索kd树:
-
注意 kd 树中的 k 指特征维度数,但 k 近邻算法中的 k 表示最邻近的 k 个点。 搜索方法如下: 输入: 已知的 kd 树,目标点 x;输出: x的最近邻.
-
先找到 kd 树中包含目标点 x的叶结点(即包含输入样例的超矩形区域):从根结点出发,递归地向下访问直到子结点为叶结点
-
以该叶结点为“当前最近点”
-
在该叶子结点递归回退,在每个结点进行如下操作:
-
如果该结点保存的实例点比“当前最近点”更距离目标点更近,则以该实例点为“当前最近点”;
-
当前最近点一定存在于该结点一个子结点对应的区域。检查该子结点的父结点的另一子结点对应的区域是否有更近的点。(即检查另一子结点对应的区域是否与该目标点为球心,以目标点与“当前最近点”间的距离为半径的超球体相交)
-
如果相交,可能在另一个子结点对应的区域内存在距目标点更近的点,移动到另一个子结点,接着,递归地进行最近邻搜索
-
如果不相交,向上回退
-
-
当回退到根结点时,搜索结束,最后的“当前最近点”即为 x 的最近邻点。
-
-
-
需要注意的点
-
- 如果实例点是随机分布的,那么 kd 树的平均计算复杂度是
O
(
l
o
g
N
)
O(logN)
O(logN); - kd 树更适用于训练实例数远大于空间维数的 k 近邻搜索,当空间维数接近训练实例数时,它的效率会迅速下降,几乎接近于线性扫描(即挨个计算训练数据集每个点和输入样例的距离)
- k近邻算法既能用于分类,也能用于回归,比较简单的回归就是用 k 近邻点的平均值来预测输入样例的预测值。
- k 近邻模型由三个因素决定:距离度量方法、k 值选取和分类决策规则
- 如果实例点是随机分布的,那么 kd 树的平均计算复杂度是
-
https://blog.csdn.net/v_july_v/article/details/8203674