起因
在一次需求开发自测中遇到一个问题,一个接口的cateId3List参数中有未编码中括号('[‘、’]’),是url特殊字符,但在发这个Get请求时参数未完全被编码,在测试环境会导致服务端返回400错误,线上环境会概率性的400 Bad Request(和nginx层无关)。
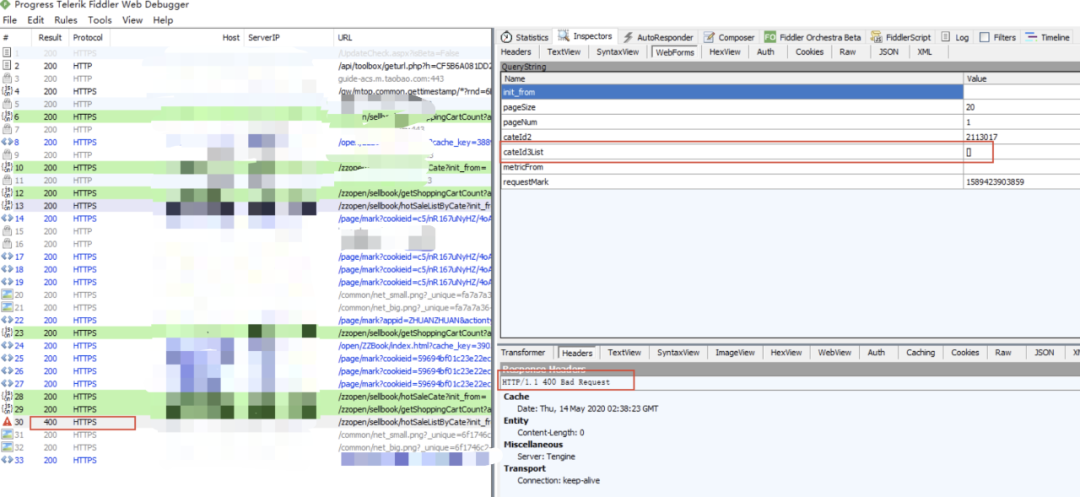
ps.该项目网络请求使用的是axios,这个接口在发出时没做过多的处理(可以理解成和用原生的axios发出请求是一样的);
下面都是以axios.get的方式为例来探讨下这个问题
(
axios
版本0.19.2)
。
问题定位
当时为了不阻塞测试流程,就先让QA通过在fiddler配置规则绕过了这个问题,使用的是fiddler自带的rewrite功能。
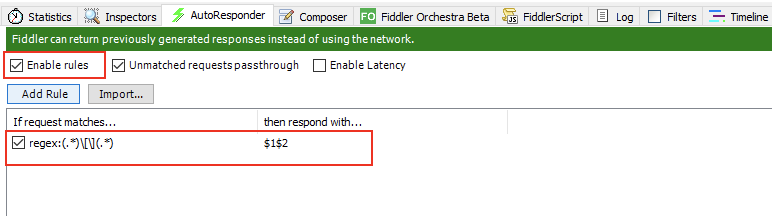
这里rewrite做的事就是把请求参数的
[
、
]
给替成编码后的。
根据以往使用axios的经验,我们在发请求时传入的参数明明是不需要主动预编码的,这里为什么会出问题呀!使用时,我们会像下面例子这样:
const axios = require('axios');
const argString = '你好';
axios.get('/zzopen/sellbook/searchDefaultWord', {
params: {
arg: argString
}
}).then(function (response) {
console.log(response);
})
通过抓包发现发出去的请求,
你好
确实已经被编码成
%E4%BD%A0%E5%A5%BD
,我们并没有手动的去编码,这一切看起来都是理所当然的。

接下来,我们把上面请求的代码修改成这样:
const axios = require('axios');
const argString = JSON.stringify(["你", "好"]);//"["你","好"]"
axios.get('/zzopen/sellbook/searchDefaultWord', {
params: {
arg: argString
}
}).then(function (response) {
console.log(response);
})
这时再看下发出去的请求:

抓包发现和我们预想的不太一样,原本认为[“你”, “好”]应该编码成
%5B%22%E4%BD%A0%22%2C%22%E5%A5%BD%22%5D
,而实际上却是
[%22%E4%BD%A0%22,%22%E5%A5%BD%22]
,这不符合我们的预期呀,只编码了
[
、
]
中间的内容,而中括号直接忽略了。想不明白呀,我们只能带着疑问去看看axios源码(https://github.com/axios/axios)搞啥子了,功夫不负有心人,最终找到了关键性的代码buildURL.js,这里有关键性的代码:
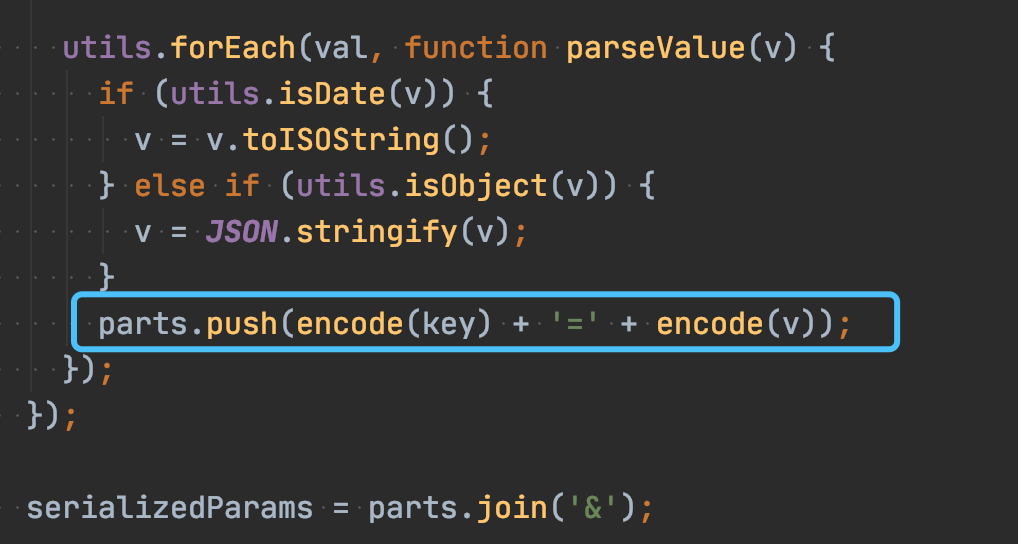
我们继续跟进去看下encode方法的实现:
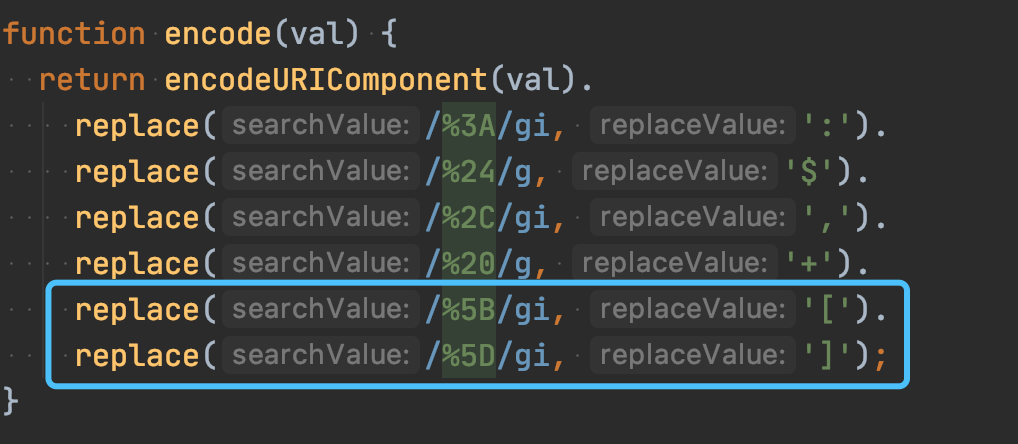
发现在这里会组装Get请求参数,外面传入的参数会在这里构造后拼接到url后,但是特殊的点就在这里:进行 encodeURIComponent 后,会在把部分encode后的参数的通过正则的方式在还原成了原本的字符了,What ???

为什么
问题看到这里从源码上也看不出来啥子了。又看了下提交历史,这块代码的修改首次提交时间2015年7月,看来是个历史悠久的问题。
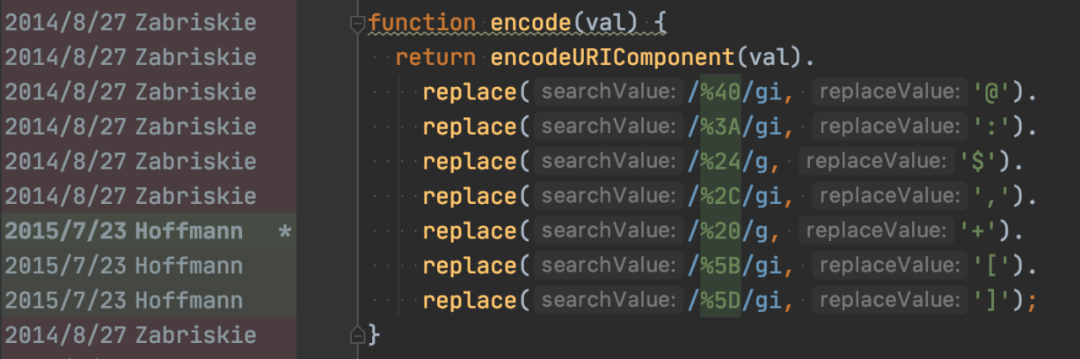
但是为什么要加上这些代码呢,提交注释里只有don’t escape square brackets。当问题不知如何下手时,就只能去怀疑猜测了。然后就想着是不是URL规范就这么规定的????,然后就去看看URI(URL是URI的子集)的规范。这里就要提到rfc3986(主要原因在这个规范里),内容比较多感兴趣的可以到这里查看https://tools.ietf.org/html/rfc3986,网上也有中文的 版的,大家感兴可以去看看。在规范中提到URL只允许包含四种大类的字符(也称非保留字符):
-
英文字母(a-zA-Z)
-
数字(0-9)
-
-_.~ 4个特殊字符
-
保留字符,RFC3986中指定了保留字符(英文字符)为:
! * ' ( ) ; : @ & = + $ , / ? # [ ]
看到这里心里大概就个底了,原来
[
、
]
是可以不用在进行编码的(编码了也没啥问题)。
再说说这个规范谁制定的,ietf,主要工作是负责互联网相关技术标准的研发和制定,是国际互联网业界具有一定权威的网络相关技术研究团体。说白了互联网标准就是这货制定的,用前端的JS视角比喻的话,就有点类似TC39,rfcxxx类似ECMAScript标准。这个规范早在2005年就制定了,为啥到现在还没有完全普及,说到这就和前端的场景更像了,虽然都是标准,但是别人可以不实现,晚实现(eg.浏览器对各语法的支持情况)。到这里编码的问题,我们了解了大致的来龙去脉。
不过,还有疑惑未解,上面还提到了概率性的400 Bad Reques,这个由于啥原因呢,想要得到答案只能从后端/运维下手了,后面和运维同学沟通了解到知道,运维
只对个别机器的tomcat做过临时的兼容配置
,
到这里答案就明了了。
如果想通过后端的方式来处理的话,就是修改Tomcat提供的配置字段(
conf/catalina.properties
),让其兼容需要的字符:

我们要怎么改
这里撇开服务端去修改Tomcat这类的配置,来谈谈前端有哪些解决方法。
-
修改请求为post
当时遇到这个问题时,没时间过多的去追究原因,就改用post请求来规避这个问题,现在回看下,post方式是规避了axios对参数的encode。
-
修改axios源码
关于这一点,在GitHub上有人提了Pull request #2563 提了,但是最终被关闭未能合并到主分支上。如果要修改的话,可以参考这个 commit id的写法:

-
参数直接拼接URL上
从axios源码上看,我们也可以预先把请求参数拼接到URL上,然后axios就不会再对处理,像这样:
const axios = require('axios');
const argString = JSON.stringify(["你", "好"]);//"["你","好"]"
axios.post('/zzopen/sellbook/searchDefaultWord?arg=' + encodeURIComponent(argString))
.then(function (response) {
console.log(response);
})
可以看到参数正常编码了

-
使用paramsSerializer处理
axios给出的建议如果参数不满足默认的编码方式的话,可以通过paramsSerializer进行自定义编码(序列化),这种方式还是值得推荐的,也能够一劳永逸。
const axios = require('axios');
axios.defaults.paramsSerializer = (params) => {
return Object.keys(params).filter(it => {
return params.hasOwnProperty(it)
}).reduce((pre, curr) => {
return params[curr] ? (pre ? pre + '&' : '') + curr + '=' + encodeURIComponent(params[curr]) : pre;
}, '');
};
//正常请求
const argString = JSON.stringify(["你", "好"]);//"["你","好"]"
axios.get('/zzopen/sellbook/searchDefaultWord', {
params: {
arg: argString,
}
}).then(function (response) {
console.log(response);
})
最后
这个问题,可简单可复杂。往简单的说,我们可以换成post请求完事,仿佛没发生过;往复杂方向去看,需要我们一路往下去深究,不停的问为什么,不停的找答案;回头再看这个过程,其实就是一个自我学习提升的过程。