目录
一、数据库集簇、元组
1. 数据库集簇
数据库集簇:
一个PG服务器管理一个数据库集簇,包含一个自定义的数据库集簇文件夹(一般命名为data),该文件夹包含一个base文件夹与其他数据库集簇信息文件,其中两个重要的文件为
|
pg_hba.conf |
控制 PostgreSQL 客户端认证 |
|
postgresql.conf |
保存数据库相关的配置参数 |
数据库:
对应base下的子目录
数据库对象
:表、索引之类的,对应base下的子目录下的文件(多于1G的可能被分为多个文件),这些数据文件由变量relfilenode管理,relfilenode一般与oid一致,即文件名就是数据库对象的id。
Truncate:
Truncate相当于drop table后再create table,所以relfilenode会被更改。
每个表都有两个与之关联的文件,_fsm和_vm分别存储了表文件每个页面上的空闲空间信息与可见性信息。索引没有可见性映射文件,因为索引对所有事务都可见,只有空闲空间映射文件。
2. 表空间
表空间:
PostgreSQL中的表空间是
base目录之外的附加数据区域
。pg数据库一般默认安装完后有两个表空间,pg_default和pg_golebal。这两个表空间的物理位置都默认在data目录下。如果不进行其他配置的话,那么所有的数据都会存在pg_default中。pg数据库是可以让用户自己创建表空间的,同时指定物理位置。这样的好处就是可以让频繁使用的数据库使用性能好的ssd挂载盘,其他可以放在hdd中,充分考虑到业务的需求。当然也可以进行数据迁移。
创建表空间并迁移数据的示例:
postgresql数据库表空间迁移 – echao – 博客园 (cnblogs.com)
表空间在磁盘上的布局
:

3. 元组
数据文件(
堆表、索引,也包括空闲空间映射和可见性映射
)内部被划分为固定长度的页,或者叫区块,大小默认为8192B(8KB)。

为了识别表中的元组,数据库内部会使用元组标识符(tuple identifier,TID)。
TID由一对值组成,分别是元组所属页面的区块号和指向元组的行指针的偏移号(所以对于所有数据文件都是有TID的,不只是堆表文件)。
区别于行指针。
堆元组写:
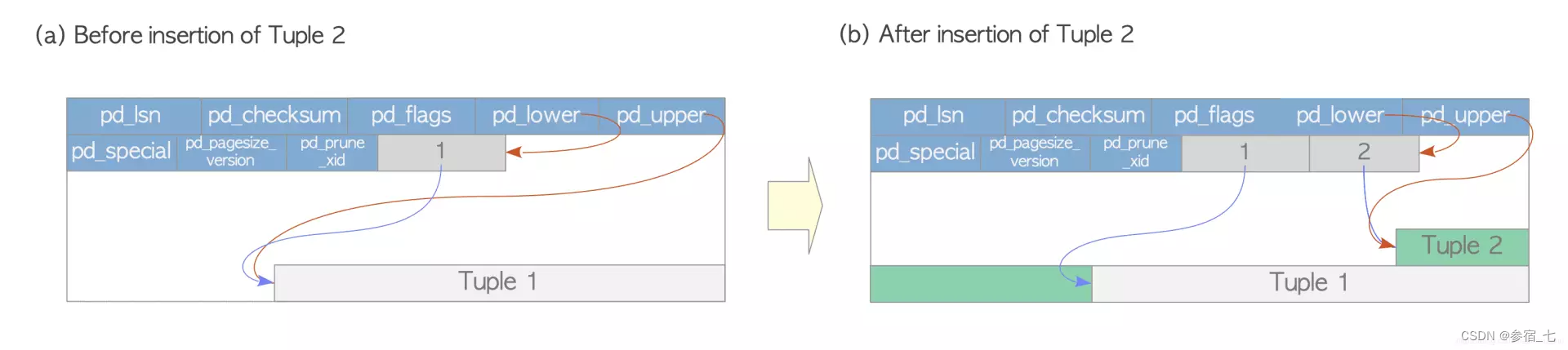
堆元组读(顺序扫描与索引扫描):

二、进程与内存架构
1. 进程架构
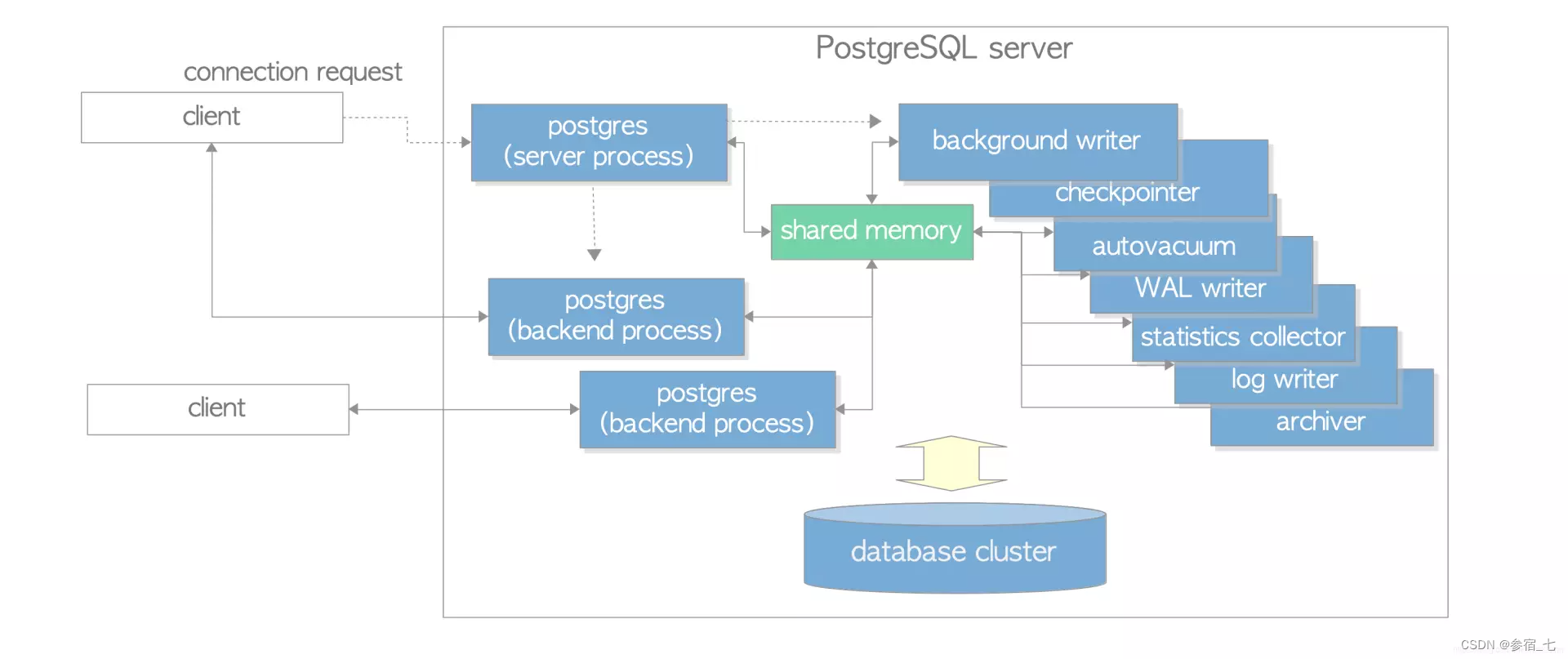
后端进程:
一个后端进程服务一个连接
后台工作进程:
数据库并行计算为一个查询生成的多个执行子进程
后台进程:
为管理数据库而产生的一些进程
background writer:进程将shared buffer pool中的脏数据写到磁盘,检查点总能触发这个进程
checkpointer:在9.2版本以后,检查点会触发产生这个进程
autovacuum launcher:为vacuum process周期性的调用autovacuum work processes
WAL writer:周期性的从wal buffer刷新数据到磁盘(这个是只从wal buffer中写事务日志的,而background writer是只从shared buffer pool中写用户数据的,其实事务日志也包含了用户数据吧,因为可以从日志中恢复数据)
statistics collector:收集统计信息进程,比如pg_stat_activity 和pg_stat_database的数据
logging collector (logger):将错误信息写入到日志
archiver:将日志归档的进程
2. 内存架构
-
Local memory area – 为
每一个后端进程
分配的内存 -
Shared memory area –为
所有的后台进程
分配的内存

|
sub-area |
description |
|
work_mem |
用户在sort,distinct,merge join,hash join的时候会用到这块区域 |
|
maintenance_work_mem |
vacuum,reindex会用到这块区域 |
|
temp_buffers |
存储临时表会用到这块区域 |
|
shared buffer pool |
表或索引的(脏)数据 |
|
WAL buffer |
日志的(脏)数据 |
|
commit log |
为并发控制保存的事务状态信息 |