nn.BCELoss和nn.CrossEntropyloss总结
nn.BCEloss
公式如下:
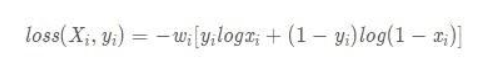
1.输入的X 代表模型的最后输出 y 代表你的label 我们的目的就是为了让模型去更好的学习label 所以loss 越小的话 x越接近label 我们的学习效果也越好
2. 使用这个公式前 x需要先通过sigmoid 激活函数 归一化到0-1之间
3. 一般二分类都是用的nn.BCELoss 因为二分类只有0 1 之分 正样本是1 负样本是0 看这个公式 当是正样本的时候 公式为 -w(ylogx) 不看w 的话 Loss的值域应该是 0到正无穷 所以loss最小是0 也就是x为1的时候 所以 x越大loss越小 也就是x越接近正样本1 loss越小 这就是这个公式的意义 反之一样
4. 使用BCELoss input和target shape 是一样的 nn.CrossEntropyloss和这个不同
nn.CrossEntropyloss
公式如:
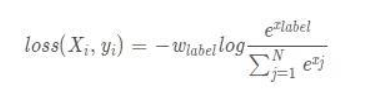
logsoftmax 公式:
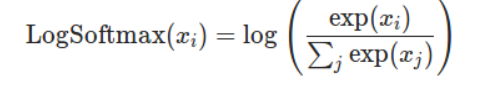
nll loss 公式:
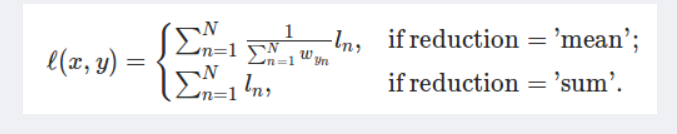
这个公式简单来说就是 logsoftmax+ nllloss的结合体,不明白的先看我参考的那几篇博文
log里面实际上就是softmax 公式 所以输入不需要像BECLoss 一样先经过激活函数 这里面自带激活函数
加上log 就是 logsoftmax 了
再取负数 就是nllloss的概念了 这里nllloss里面有参数 mean 和 sum 实际上就是对应的nn.CrossEntropyloss 里面的reduction参数 mean代表取均值 sum代表取总和
input和target 的shape 不一样 input 是N*C C代表种类个数 target 是N
这里的原因就是上面的nllloss的缘故 他的作用是把对应标签位置的值拿出来取负数
举个例子
比如输入是3*3 代表 3张图片预测3类 每一张图片都预测他属于每一类的概率
因为经过了softmax所以概率和为1 我们假设是
[[0.2,0.3,0.5],
[0.8,0.1,0.1],
[0.7,0.2,0.1] 可以看出来 每一行的和为1 行代表图片个数 列代表种类 而我们的标签 是3 和输入不对应
比如是[0,1,2] 这时候 会自动one-hot编码 比如0 会变成[1,0,0]他会吧每一行对应的标签的数拿出来 第一个0 应该是第0类 所以吧0.8拿出来 第二个是1 吧0.1拿出来 以此类推。 这样就拿出来了3个数 根据reduction的设置 取平均或者总和 代表了最后的损失 可以看出 只有loss越小 说明标签是对应的 学习的越好。
总结
总结一下nn.CrossEntropyloss
看整个公式 实际就是交叉熵公式
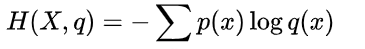
原文链接:
https://blog.csdn.net/weixin_50249353/article/details/119239907