文章目录

不稳定的排序:快选堆希
比较次数(时间复杂度)与关键字次序无关:一堆(堆排序)海龟(归并排序)选(选择排序)基(基数排序)友
基本概念

有些时候不需要稳定,就速度就行


插入排序
每次将⼀个待排序的记录按其关键字大小插⼊到前面已排好序的⼦序列中,直到全部记录插入完成。
1.插入排序
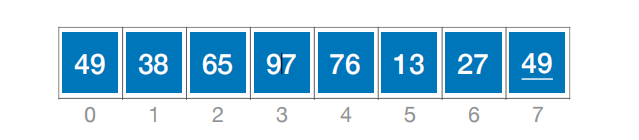





插到前面去,要把前面的全部往后挪(用一个temp暂存要插的元素,挪完了再把它复制出来)

带哨兵的实现:

带哨兵减少检查条件,当j=0的时候就停止,然后把A[1]=A[0]
,因为j+1=1
优点:不⽤每轮循环都判断 j>=0
空间复杂度:O(1)
最好时间复杂度—— O(n),排好了已经,直接n次
最坏时间复杂度——O(n
2
),n次,每次都移动n个
算法稳定性:稳定
2.折半插入排序(优化)
先⽤折半查找找到应该插⼊的位置,再移动元素

最开始先把i里的值复制到哨兵里,找到后把low~i-1全部右移,然后把哨兵里的值复制到low里去



如果等于,继续找,知道low>high,这是为了算法的稳定性(相等的右边说不定还有这个值)


low如果最后停在i上,就不用管


时间复杂度还是O(n
2
)
反正只要是插入排序,怎么优化都是O(n
2
)
3.对链表进行插入排序

只需要修改一下指针,不需要全部移动了,不过注意时间复杂度还是O(n
2
)
小结

希尔排序


第一次间隔一般是n/2,后面逐步缩小(÷2),每次都把小组里的元素进行插入排序,最后d=1,完成排序




此时整个表已经基本有序,最后再对全部进行一次插入排序

希尔本⼈建议:每次将增量缩小⼀半
具体的增量缩小的方法,是看题怎么给的


时间复杂度目前没有一个准确的值,与增量序列是有关系的,选的好的话是优于O(n
2
)的

不适用链表(对隔着d的元素排序,用链表查要花一定时间,不方便)

优于插入排序
冒泡排序
基于交换的排序





每一趟结束可以确定一个元素的最终位置(最小的,第二小的……)

前边已经确定最终位置的元素不⽤再对⽐
重复这项工作,直到所有的元素排序完成


算法稳定,因为只有大于的时候才会交换,等于的时候不会
i之前的元素已经有序,j到i的时候就停止

注意这个每次交换里面需要操作三次

冒泡适用于链表,改下指针就行了
快速排序
基于交换的排序
1.算法思想


每次选一个基准(通常选第一个),通过一趟排序将小于基准的放到左边,大于的放到右边,此时基准就在正确的位置上了(也是一趟排序确定一个元素的位置),然后分别对左边、右边的再进行选基准,排序的操作,如此循环直至排序完成



取最左边的为基准,里面的元素拿出来(用来比较),low所指暂时变空,此时让high左移,high所指如果小于基准则放到low里去(否则high左移,里面的东西不动),此时high变空,让low右移,low所指如果大于基准则放到high里去(否则low继续右移),循环,最终low和high会碰到,这个地方就是基准的位置


第一次划分好之后,对左边再进行排序,对右边也排序,循环,直至都排好为止(比如某队列只剩一个元素就不用排了)



2.代码

3.算法效率

空间复杂度=O(递归层数),递归工作栈


把元素组织成一个二叉树,来分析复杂度

每次选的基准,让两边不均匀,会使递归深度增加(二叉树不平衡),而时间复杂度其实就取决于这个递归深度
若每⼀次选中的“枢轴”将待排序序列划分为均匀的两个部分,则递归深度最小,算法效率最高(平衡二叉树)





简单选择排序
每⼀趟在待排序元素中选取关键字最小的元素加入有序子序列




选最小的,然后和前面的交换,循环直到排好(最后剩⼀个不
用再处理)



每次选最小的,O(n),一共n-1次,所以时间复杂度是O(n
2
)

适用于链表,遍历找最小,交换一下就行了(修改指针)

堆排序



堆顶元素关键字最大(小),所以堆排序就是每次取出堆顶元素然后调整堆即可
1.建立大根堆

终端结点不用检查





不满足就把更大的孩子换上来,从后往前检查,这样下面的孩子换上来可以和上面的继续比较

换好之后,之前小的往下,有可能导致下面的不符合了
若元素互换破坏了下⼀级的堆,则采⽤相同的⽅法继续往下调整(⼩元素不断“下坠”)
换上去之后再把小元素下坠,直到无法下坠为止


2.基于大根堆进行排序


每次把堆顶元素和最后一个互换,然后再调整恢复成大根堆(堆顶元素下去之后就把它看作不是大根堆里的)


第二趟,堆顶78换下来,加入了有序子序列



循环如此,最后所有的元素都排序完成(只剩下最后⼀个待排序元素时,不⽤再调整)

注意:基于“⼤根堆”的堆排序得到“递增序列”

前面有建堆和调整堆的代码


每下坠一层,要横向比较一下孩子结点哪个更大,所以要比较两次

每次下坠比较关键字2次,最多下坠h-1层,所以一趟的时间复杂度为O(log
2
n),n趟就是O(nlog
2
n)


如果左右孩子一样大,优先和左孩子换

结论:堆排序是不稳定的

3.堆的插入删除
①插入


新元素放在表尾,然后调整(对比三次,还要和最上面的比一次)
②删除



被删除的地方用最下面的替代,然后再调整

每下坠一层都要对比2次,孩子之间要对比一次,选更小的那边去下坠(这样下坠了才能维持根的性质)
小结

归并排序




循环,直至排序完成(有一个子表全部进去的话,直接把另一个添加进去就行了)

每次选一个最小的要对比m-1次

对一个长的序列,一直归并,直到全部合在一起

两个元素相等时,优先使用靠前的那个(稳定性)

2个2个归并,所以趟数是log
2
n,每趟O(n),所以时间复杂度为O(nlog
2
n)

基数排序



挂上去,再收下来(头指针指的先挂上去的,也是先取的)

第一波按个位排序之后,第二波当十位相等时,放前面的肯定是个位更大的



再进行一次分配收集,排序完成

第一趟个位相同的时候在前面的就排在前面

基数排序不是基于“比较”的排序算法

分配时,n个数字,收集时找r个队列,所以一趟是n+r,d趟就是O(d(n+r)),d就是有几位数字
基数排序通常基于链式存储实现
基数排序是稳定的(相等的本来在前面收集取下来也会在前面)


d就是趟数
r是取值,辅助队列的个数(有多少串,决定取的时候)
n大的时候这个算法优秀,大的话d和r就不算事了(d(n+r))
反例:给5个⼈的身份证号排序(收集回收18趟,不如直接排)
反例:给中文人名排序(每个名字可能有几万种取值),取得时候太麻烦
擅长:给⼗亿⼈的身份证号排序,n太大的时候比n
2
,nlog
2
n好用

外部排序
外部排序
1.外存与内存之间的数据交换


2.外部排序原理
在外部是没办法排序的,只有读到内存里修改了再弄出来

在内部采用归并排序


在内部进行一次内部排序(就用前面的方法,直接排好),然后再挨个输出回去

构造好一个初始的归并段
构造初始归并段:需要16次“读”和16次“写”

然后开启第二次,把两个归并段归并成一个


先从两个段前面取,用归并排序,每次选两个输入区中最小的放到输出缓冲区,输出区满了就取出去(直接覆盖回去,上面那个只是为了看着清楚),1空了就用1的下一段补上,2空了用2的补上(1只放段1的,2只放段2的,这样保证一直是最小的,所以不能直接用内部排序,因为不能保证段1的后面部分一定比段2的前面小,2也是如此)


第一趟归并完成之后








循环,反正就一直两个段归并,规则跟之前一样
3.性能分析

每趟归并读写各16次(每趟都要把所有的块读写一遍),时间开销主要在读写上,因为读写太慢了
4.优化方案
①多路归并

规则还是与之前一样

可以一次归并出一个更长的有序序列

多路归并也有坏处,不能整太多:要开辟缓冲区,选关键字对比次数增加
②减少初始归并段数量

用更多的缓冲区,这样一次生成的初始归并段就更大



败者树
败者树
k路归并,每次要比较k-1次,太麻烦,败者树就是为了优化这个

产生了7个失败者,所以对比7次
叶子结点是所有的参赛者,往上则记录各失败者,最上面多了个胜者

败者树——可视为⼀棵完全⼆叉树(多了⼀个头头,最终胜者)。k个叶结点分别是当前参加比较的元素,非叶子结点用来记忆左右子树中的“失败者”,而让胜者往上继续进行比较,⼀直到根结点。
如果此时天津饭退赛,重新角逐冠军就不需要比赛7场了(因为已经保存了每个点的失败者,直接往上比就行了)

派大星直接往上比就行了,输了就留在那(然后赢了的向上移)

第一次刚构造败者树,对比k-1次

找到一个最小的,把它移出去(进入输出序列了),由于它是来自段3,所以从段3弄进来一个新的,开始排,失败者和胜者都是存的来自哪个段(这样方便去弄一个新的进来)

有了败者树,选出最小元素,只需对比关键字⌈log2k⌉次(树的高度)


置换-选择排序
置换-选择排序
可用“置换-选择排序”进⼀步减少初始归并段数量

土办法想扩大初始归并段容量只有在内存开辟更大的空间
1.算法思想

假设这个区只能装三个,但是它可以一直把里面最小的弄出去,这样又可以装一个进来,一直排序,这样就可以用很小的一个区域整出一个很长的初始归并段


有个minimax,当里面的元素比这大的时候就选个最小的(要比minimax大)弄到归并段里,并且把minimax的值改了

10比minimax小了,不能输出,必须留着等起,先把14弄出去


到这,2也不能出去了

直到3个元素都比minimax小,此时就截断,第一个归并段完成

然后再如此循环,开始整归并段2


最后把全部的元素都排好,这样每个归并段都比较长,用到的内存区也少
小结

最佳归并树
最佳归并树

读写次数就是里面所含块数之和(有多少块就读写多少次)
这个重要结论主要是因为读一次写一次,所以乘2

前面肯定要越小越好,不然归并出来的段一直很大,读写次数就会特别多(每次归并都要读写归并段里所有的块,所以前面得越小越好)

注意:对于k叉归并,若初始归并段的数量⽆法构成严格的 k 叉归并树, 则需要补充⼏个⻓度为 0 的“虚段”,再进⾏ k 叉哈夫曼树的构造。


初始归并段数量为x,如果x-1能整除k-1,则不需要虚段,如果不能,则添加到可以整除为止(计算要添加多少个虚段)

