学习资料
【MySQL数据库教程天花板,mysql安装到mysql高级,强!硬!-哔哩哔哩】
【阿里巴巴Java开发手册】https://www.w3cschool.cn/alibaba_java
锁的不同角度分类
锁的分类图如下

其他锁之:全局锁
全局锁就是对
整个数据库实例
加锁。当你需要让整个库处于
只读状态
的时候,可以使用这个命令,之后其他线程的以下语句会被阻塞:数据更新语句(数据的增删改)、数据定义语句(包括建表、修改表结构等)和更新类事务的提交语句。全局锁的典型使用
场景
是:做
全库逻辑备份
。
全局锁的命令:
Flush tables with read lock
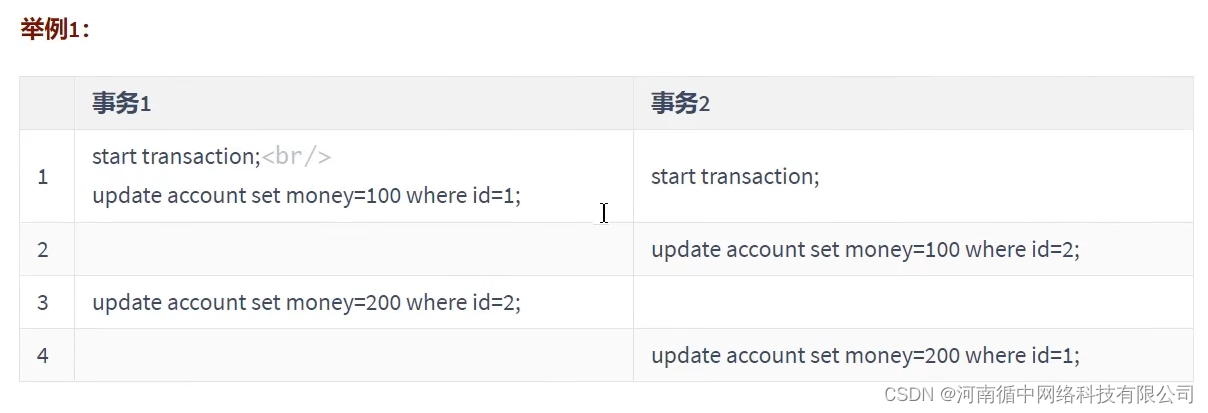
其他锁之:死锁
概念
两个事务都持有对方需要的锁,并且在等待对方释放,并且双方谁都不会释放自己的锁。

产生死锁的必要条件
1、两个或者两个以上的事务。
2、每个事务都已经持有锁并且申请新的锁。
3、锁资源同时只能被同一个事务持有或者不兼容。
4、事物之间因为持有锁和申请锁导致彼此循环等待。
死锁的关键在于:两个(或以上)的Session加锁的顺序不一致。
如何处理死锁
方式1:
等待,直到超时(innodb_lock_wait_timeout=50s)。
即当两个事务互相等待时,当一个事务等待时间超过设置的阈值时,就将其
回滚
,另外事务继续进行。这种方法简单有效,在innodb中,参数
innodb_lock_wait_timeout
用来设置超时时间。
缺点:对于在线服务来说,这个等待时间往往是无法接受的。
那将此值修改短一些,比如1s,0.1s是否合适?不合适,容易误伤到普通的锁等待。
方式2
:使用死锁检测进行死锁处理
方式1检测死锁太过被动,innodb还提供了
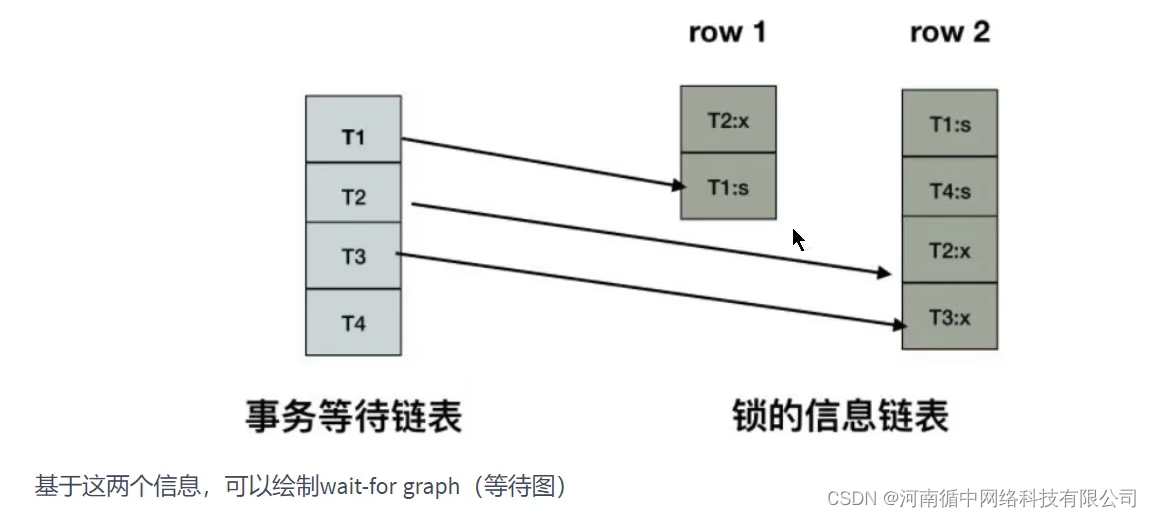
wait-for graph算法
来主动进行死锁检测,每当加锁请求无法立即满足需要进入等待时,wait-for graph算法都会被触发。
这是一种较为
主动的死锁检测机制
,要求数据库保存
锁的信息链表
和
事务等待链表
两部分信息。
死锁检测的原理是构建一个以事务为顶点,锁为边的有向图,判断有向图是否存在环,存在即有死锁。
一旦检测到回路,有死锁,这时候InnoDB存储引擎会选择
回滚undo量最小的事务
,让其他事务继续执行(
innodb_deadlock_detect=on
表示开启这个逻辑)。
缺点:每个新的被阻塞的线程,都要判断是不是由于自己的加入导致了死锁,这个操作时间复杂度是0(n)。如果100个并发线程同时更新同一行,意味着要检测100*100=1万次,1万个线程就会有1千万次检测。
如何解决?
方式1:关闭死锁检测,但意味着可能会出现大量的超时,会导致业务有损。
方式2:控制并发访问的数量。比如在中间件中实现对于相同行的更新,在进入引擎之前排队,这样在InnoDB内部就不会有大量的死锁检测工作。
进一步的思路:
可以考虑通过将一行改成逻辑上的多行来减少
锁冲突
。比如,连锁超市账户总额的记录,可以考虑放到多条记录上。账户总额等于这多个记录的值的总和。

如何避免死锁
1、合理设置索引,使业务SQL尽可能通过索引定位更少的行,减少锁竞争。
2、调整业务逻辑SQL执行顺序,避免update/delete长时间持有锁的SQL在事务前面。
3、避免大事务,尽量将大事务拆成多个小事务来处理,小事务缩短锁定资源的时间,发生锁冲突的几率也更小。
4、在并发比较高的系统中,不要显式加锁,特别是是在事务里显示加锁。如select … for update语句,如果是在事务里运行了start transaction或设置了autocommit等于0,那么就会锁定所查找到的记录。
5、降低隔离级别。如果业务允许,将隔离级别调低也是较好的选择,比如将隔离级别从RR调整为RC,可以避免掉很多因为gap锁造成的死锁。