坚持写博客,分享自己的在学习、工作中的所得
- 给自己做备忘
- 对知识点记录、总结,加深理解
- 给有需要的人一些帮助,少踩一个坑,多走几步路
尽量以合适的方式排版,图文兼有
如果写的有误,或者有不理解的,均可在评论区留言
如果内容对你有帮助,欢迎点赞 ? 收藏 ⭐留言 ?。
虽然平台并不会有任何奖励,但是我会很开心,可以让我保持写博客的热情
文章目录
动态学习率
因为经常会使用到动态学习率,将其可视化会更好理解。
optimizer提供初始lr
lr_scheduler的step()从lr变化到eta_min
如果初始设置的lr比eta_min大,则先减小到eta_min,再增大到lr
如果初始设置的lr比eta_min小,则先增大到eta_min,再减小到lr
last_epoch:上一个epoch数,当为-1时,学习率设置为初始值。
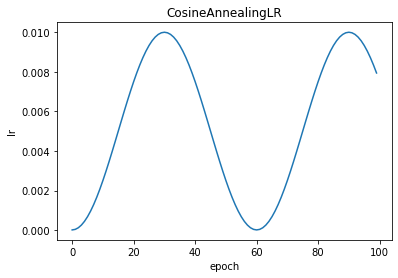
CosineAnnealingLR
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1, verbose=False)
CosineAnnealingLR:余弦退火学习率,
T_max
为半周期,每经过
2*T_max
之后
lr
回到原来的值,
eta_min
与
optimizer
的
lr
作比较,大的为最大值,小的为最小值,从
lr
到
eta_min
按余弦更新
T_max:经过多少个iter,学习率达到最大值
eta_min:学习率最小值
import torch
from torchvision.models import AlexNet
from torch import optim
import matplotlib.pyplot as plt
model = AlexNet(num_classes=2)
optimizer = torch.optim.SGD(model.parameters(), lr=1e-5, momentum=0.9, nesterov=False)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=30, eta_min=0.01)
EPOCHS = 100
x = list(range(EPOCHS))
y = []
for epoch in range(1,EPOCHS+1):
optimizer.zero_grad()
optimizer.step()
y.append(scheduler.get_last_lr()[0])
scheduler.step()
# 画出lr的变化
plt.figure()
plt.plot(x, y)
plt.xlabel("epoch")
plt.ylabel("lr")
plt.title("CosineAnnealingLR")
plt.show()
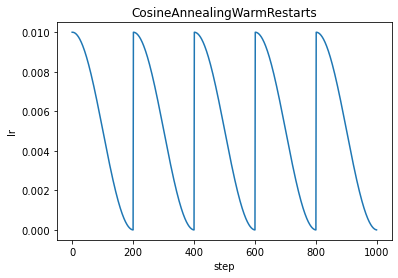
CosineAnnealingWarmRestarts
torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0, T_mult=1, eta_min=0, last_epoch=-1, verbose=False)
CosineAnnealingWarmRestarts:带热重启的余弦退火
SGDR: Stochastic Gradient Descent with Warm Restarts.
T_0:第一次restart的迭代次数。
T_mult:restart之后增加 Ti 的因子,大于1的整数
eta_min:学习率最小值
import torch
from torchvision.models import AlexNet
from torch import optim
import matplotlib.pyplot as plt
import math
model = AlexNet(num_classes=2)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9, nesterov=False)
scheduler = optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=20, T_mult=1, eta_min=1e-7)
EPOCHS = 100
dataloader = list(range(10))
iters = len(dataloader)
y = []
for epoch in range(EPOCHS):
for i, sample in enumerate(dataloader):
optimizer.zero_grad()
optimizer.step()
y.append(scheduler.get_last_lr()[0])
scheduler.step(epoch + i / iters)
# 画出lr的变化
plt.figure()
x = list(range(len(y)))
plt.plot(x, y)
plt.xlabel("epoch")
plt.ylabel("lr")
plt.title("CosineAnnealingWarmRestarts")
plt.show()
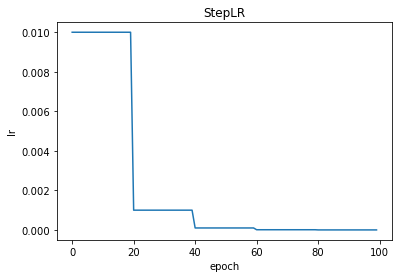
StepLR
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1, verbose=False)
StepLR:阶梯学习率。每隔相同
step_size
更新一次
lr
,改变
gamma
倍。
import torch
from torchvision.models import AlexNet
from torch import optim
import matplotlib.pyplot as plt
import math
model = AlexNet(num_classes=2)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9, nesterov=False)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.1)
EPOCHS = 100
y = []
for epoch in range(1,EPOCHS+1):
optimizer.zero_grad()
optimizer.step()
y.append(scheduler.get_last_lr()[0])
scheduler.step()
# 画出lr的变化
x = list(range(EPOCHS))
plt.figure()
plt.plot(x, y)
plt.xlabel("epoch")
plt.ylabel("lr")
plt.title("StepLR")
plt.show()
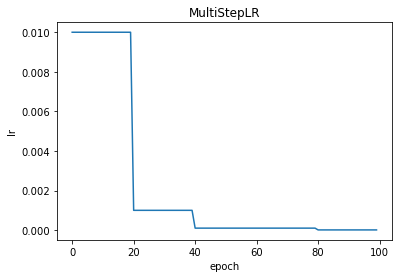
MultiStepLR
torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1, verbose=False)
MultiStepLR:多阶梯学习率。
milestones
对应位置更新一次
lr
,改变
gamma
倍。
与StepLR的差别是StepLR是每隔相同step_size更新一次lr;
而MultiStepLR是为milestones提供一个list,每到milestones的一个元素更新一次lr。
注意:milestones的元素必须是随索引增长的,即后一个元素必须比前一个元素大。
import torch
from torchvision.models import AlexNet
from torch import optim
import matplotlib.pyplot as plt
import math
model = AlexNet(num_classes=2)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9, nesterov=False)
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[20,40,80], gamma=0.1)
EPOCHS = 100
y = []
for epoch in range(1,EPOCHS+1):
optimizer.zero_grad()
optimizer.step()
y.append(scheduler.get_last_lr()[0])
scheduler.step()
# 画出lr的变化
x = list(range(EPOCHS))
plt.figure()
plt.plot(x, y)
plt.xlabel("epoch")
plt.ylabel("lr")
plt.title("MultiStepLR")
plt.show()
ExponentialLR
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1, verbose=False)
每个epoch使用gamma衰减学习率lr
ExponentialLR:指数学习率。每次更新为
lr *= gamma
相当于StepLR的step_size=1
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.9)
这里说明一下:
有的博客提到
调整公式: lr = lr * gamma**epoch, gamma为学习率调整倍数的底,指数为epoch
按照下面的代码,每个epoch的学习率都是在之前的学习率之前的学习率基础上乘以gamma值得到:
lr *= gamma
但是如果是在全局上,加上指数学习率这个名字,公式确实应该是
lr = lr * gamma**epoch
,只是这里的学习率是初始化的学习率,而上面我理解的学习率是根据上一个epoch的学习率来计算当前epoch的学习率。其实都是一样的。只是后面这个公式能更好的体现
ExponentialLR
,并且在继续训练中,可以通过
start_epoch
就能计算出对应的
epoch
的
lr
。
import torch
from torchvision.models import AlexNet
from torch import optim
import matplotlib.pyplot as plt
import math
model = AlexNet(num_classes=2)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9, nesterov=False)
scheduler = optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.9)
EPOCHS = 100
y = []
for epoch in range(1,EPOCHS+1):
optimizer.zero_grad()
optimizer.step()
y.append(scheduler.get_last_lr()[0])
scheduler.step()
# 画出lr的变化
x = list(range(EPOCHS))
plt.figure()
plt.plot(x, y)
plt.xlabel("epoch")
plt.ylabel("lr")
plt.title("ExponentialLR")
plt.show()
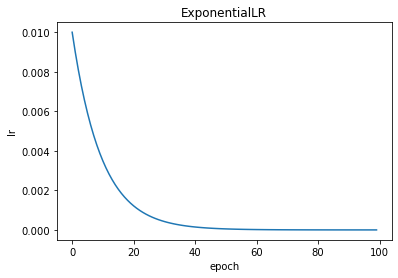
ReduceLROnPlateau
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08, verbose=False)
ReduceLROnPlateau:当指标停止改进时降低学习率。
scheduler.step(val_loss)
,给传入scheduler某个指标(比如val_loss或者val_acc),当
patience
个周期中这个指标变化小于
threshold
时将
lr
衰减
factor
倍,如果新旧
lr
之间的差异小于
eps
,则忽略更新。
注意:跟其他scheduler不太一样的地方是:scheduler.step(val_loss)需要传参,没办法通过get_last_lr或get_lr得到lr
scheduler.get_last_lr()
AttributeError: ‘ReduceLROnPlateau’ object has no attribute ‘get_last_lr’
scheduler.get_lr()
AttributeError: ‘ReduceLROnPlateau’ object has no attribute ‘get_lr’
import torch
from torchvision.models import AlexNet
from torch import optim
import matplotlib.pyplot as plt
import math
model = AlexNet(num_classes=2)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9, nesterov=False)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=5, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08, verbose=False)
EPOCHS = 100
y = []
val_loss = 10
for epoch in range(1,EPOCHS+1):
optimizer.zero_grad()
optimizer.step()
# 如果固定下降val_loss,则lr不更新
# val_loss *= 0.1
if epoch%10 == 0:
val_loss *= 0.1
y.append(optimizer.state_dict()['param_groups'][0]['lr'])
scheduler.step(val_loss)
# 画出lr的变化
x = list(range(EPOCHS))
plt.figure()
plt.plot(x, y)
plt.xlabel("epoch")
plt.ylabel("lr")
plt.title("ReduceLROnPlateau")
plt.show()
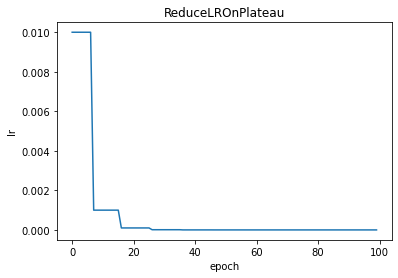
CyclicLR
torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr, max_lr, step_size_up=2000, step_size_down=None, mode='triangular', gamma=1.0, scale_fn=None, scale_mode='cycle', cycle_momentum=True, base_momentum=0.8, max_momentum=0.9, last_epoch=-1, verbose=False)
CyclicLR:循环学习率策略在每批之后改变学习率。应在批次用于训练后调用步骤。
base_lr:初始学习率,即各参数组在循环中的下边界。
max_lr:每个参数组在循环中的上学习率边界。
step_size_up:学习率上升的迭代次数,参考代码和图片更易理解。
step_size_down:学习率下降的迭代次数,参考代码和图片更易理解。
mode 的参数有:
triangular
,
triangular2
,
exp_range
scale_fn:由单个参数 lambda 函数定义的自定义缩放策略,其中
0 <= scale_fn(x) <= 1 for all x >= 0
。如果指定,则忽略
mode
参数
scale_mode:参数有:
cycle
,
iterations
step_size_up
和
step_size_down
配合调整形态,step_size_down为None则默认step_size_down=step_size_up
import torch
from torchvision.models import AlexNet
from torch import optim
import matplotlib.pyplot as plt
import math
model = AlexNet(num_classes=2)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9, nesterov=False)
scheduler = optim.lr_scheduler.CyclicLR(optimizer, base_lr=0.01, max_lr=0.0001, step_size_up=2000, step_size_down=500, mode='triangular') #mode in ['triangular', 'triangular2', 'exp_range']
EPOCHS = 100
dataloader = list(range(100))
y = []
for epoch in range(1,EPOCHS+1):
for batch in dataloader:
optimizer.zero_grad()
optimizer.step()
y.append(scheduler.get_last_lr()[0])
scheduler.step()
# 画出lr的变化
x = list(range(len(y)))
plt.figure()
plt.plot(x, y)
plt.xlabel("epoch")
plt.ylabel("lr")
plt.title("CyclicLR")
plt.show()
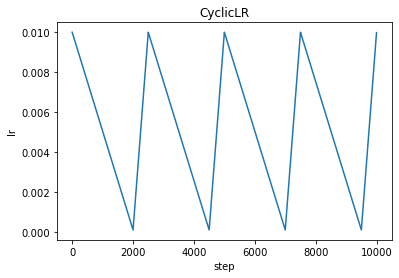
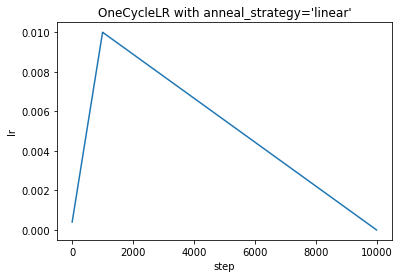
OneCycleLR
torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr, total_steps=None, epochs=None, steps_per_epoch=None, pct_start=0.3, anneal_strategy='cos', cycle_momentum=True, base_momentum=0.85, max_momentum=0.95, div_factor=25.0, final_div_factor=10000.0, three_phase=False, last_epoch=-1, verbose=False)
OneCycleLR:OneCycle 学习率策略在
每个batch
之后改变学习率。应在每个
batch
训练后调用
step()
。学习率与
optimizer
设置的学习率完全无关。
根据OneCycle学习率策略设置每个参数组的学习率。 OneCycle 策略将学习率从初始学习率退火到某个最大学习率,然后从该最大学习率退火到远低于初始学习率的某个最小学习率。
循环中的总步骤数可以通过以下两种方式之一确定(按优先顺序列出):
1.提供了 total_steps 的值。
2.了多个时代 (epoch) 和每个时代的多个步骤 (steps_per_epoch)。在这种情况下,总步数由 total_steps = epochs * steps_per_epoch 推断
pct_start:于提高学习率的周期百分比(以步数计)。就是上升阶段的占比
div_factor:通过
initial_lr = max_lr/div_factor
确定初始学习率
final_div_factor:通过
min_lr = initial_lr/final_div_factor
确定最小学习率
import torch
from torchvision.models import AlexNet
from torch import optim
import matplotlib.pyplot as plt
import math
EPOCHS = 100
dataloader = list(range(100))
model = AlexNet(num_classes=2)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9, nesterov=False)
scheduler = optim.lr_scheduler.OneCycleLR(optimizer, max_lr=0.01, total_steps=None, epochs=EPOCHS, steps_per_epoch=len(dataloader), pct_start=0.1, anneal_strategy='cos') # anneal_strategy:'cos', 'linear'
y = []
for epoch in range(1,EPOCHS+1):
for batch in dataloader:
optimizer.zero_grad()
optimizer.step()
y.append(scheduler.get_last_lr()[0])
scheduler.step()
# 画出lr的变化
x = list(range(len(y)))
plt.figure()
plt.plot(x, y)
plt.xlabel("step")
plt.ylabel("lr")
plt.title("OneCycleLR")
plt.show()
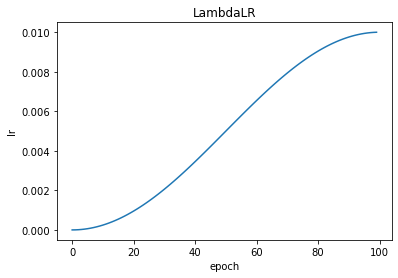
LambdaLR
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1, verbose=False)
LambdaLR:按照自定义规则更新lr
import torch
from torchvision.models import AlexNet
from torch import optim
import matplotlib.pyplot as plt
import math
model = AlexNet(num_classes=2)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9, nesterov=False)
y1=0.0
y2=1.0
steps=100
lf = lambda x: ((1 - math.cos(x * math.pi / steps)) / 2) * (y2 - y1) + y1
scheduler = optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
EPOCHS = 100
y = []
for epoch in range(1,EPOCHS+1):
optimizer.zero_grad()
optimizer.step()
y.append(scheduler.get_last_lr()[0])
scheduler.step()
# 画出lr的变化
x = list(range(EPOCHS))
plt.figure()
plt.plot(x, y)
plt.xlabel("epoch")
plt.ylabel("lr")
plt.title("LambdaLR")
plt.show()
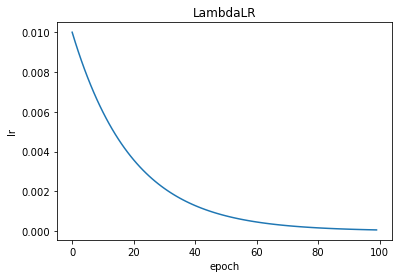
import torch
from torchvision.models import AlexNet
from torch import optim
import matplotlib.pyplot as plt
import math
model = AlexNet(num_classes=2)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9, nesterov=False)
lambda1 = lambda epoch: epoch // 30
lambda2 = lambda epoch: 0.95 ** epoch
scheduler = optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda2)
EPOCHS = 100
y = []
for epoch in range(1,EPOCHS+1):
optimizer.zero_grad()
optimizer.step()
y.append(scheduler.get_last_lr()[0])
scheduler.step()
# 画出lr的变化
x = list(range(EPOCHS))
plt.figure()
plt.plot(x, y)
plt.xlabel("epoch")
plt.ylabel("lr")
plt.title("LambdaLR")
plt.show()
参考:
https://pytorch.org/docs/stable/optim.html
如果内容对你有帮助,或者觉得写的不错
?️?欢迎点赞 ? 收藏 ⭐留言 ?
有问题,请在评论区留言