LeetCode刷题笔记(算法思想 一)
一、双指针
167. 两数之和 II – 输入有序数组
给定一个已按照升序排列的有序数组,找到两个数使得它们相加之和等于目标数。
函数应该返回这两个下标值 index1 和 index2,其中 index1 必须小于 index2。
说明:
- 返回的下标值(index1 和 index2)不是从零开始的。
- 你可以假设每个输入只对应唯一的答案,而且你不可以重复使用相同的元素。
示例:
输入: numbers = [2, 7, 11, 15], target = 9
输出: [1,2]
解释: 2 与 7 之和等于目标数 9 。因此 index1 = 1, index2 = 2 。
思路:
定义两个指针,i 从数组开头向尾遍历,j 从数组尾向开头遍历,每次将指针指向的两数之和与target比较,比target大则 j 向前移,比target小则 i 向后移,和target相等则返回。注意题目要求下标不是从0开始。
另外本题还可以用
二分查找
法实现:循环遍历数组,由于target已知,target与数组中a的差即为要找的另一个数b。利用二分法可以快速查找b,最后返回排序好的a,b的下标。
代码实现:
# 双指针解法:
class Solution:
def twoSum(self, nums, target):
i, j = 0, len(nums)-1
while i < j:
if nums[i] + nums[j] > target:
j -= 1
elif nums[i] + nums[j] < target:
i += 1
elif nums[i] + nums[j] == target:
return sorted([i+1,j+1]) # 下标不从0开始
return None
# 二分查找解法:
class Solution:
def binary_search(self, li, left, right, val):
while left <= right:
mid = (left + right) // 2
if li[mid] > val:
right = mid - 1
elif li[mid] < val:
left = mid + 1
else:
return mid
return None
def twoSum(self, nums, target):
for i in range(len(nums)):
a = nums[i]
b = target - a
if b >= a:
j = self.binary_search(nums,i+1,len(nums)-1,b)
else:
j = self.binary_search(nums,0,i-1,b)
if j:
break
return sorted([i+1,j+1])
633. 平方数之和
给定一个非负整数 c ,你要判断是否存在两个整数 a 和 b,使得 a^2 + b^2 = c。
示例1:
输入: 5
输出: True
解释: 1 * 1 + 2 * 2 = 5
示例2:
输入: 3
输出: False
思路:
(1)双指针方法:由于a^2 + b^2 = c,a和b均小于c的平方根。设定两个指针,一个p从0开始往右扫描,一个r从int(c**0.5)开始往左扫描,循环结束条件是当p > r时则结束循环。循环里,当 p^2 + r^2 == c时,返回True;当p^2 + r^2 > c时,说明r选的大了,于是r -=1;当p^2 + r^2 < c时,说明p选的小了,于是 p += 1;循环结束还没找到,返回False。
(2)对上面方法改进,在循环里,b = math.sqrt(c – a*a),如果b是整数,b == int(b),直接返回True;循环结束还没找到,返回False。
代码实现:
import math
class Solution:
def judgeSquareSum(self, c: int) -> bool:
a = 0
while a*a <= c:
b = math.sqrt(c - a*a)
if b == int(b):
return True
a += 1
return False
345. 反转字符串中的元音字母
编写一个函数,以字符串作为输入,反转该字符串中的元音字母。
示例 1:
输入: "hello"
输出: "holle"
示例 2:
输入: "leetcode"
输出: "leotcede"
说明: 元音字母不包含字母”y”。
思路:
定义一个列表存储十个元音字母(大小写),将字符串转为列表,定义两个指针,i从0开始往右扫描,j从列表最后一个元素往左扫描。循环结束条件为 i >= j,如果指针指向的两个元素均在列表里(均为元音字母),交换并把 i += 1,j -= 1;如果一个在一个不在,不在的那个指针移动至下一位置;如果都不在,则两个指针都移动至下一位置。
代码实现:
class Solution:
def reverseVowels(self, s: str) -> str:
li = list(s)
vowel = ['a','e','i','o','u','A','E','I','O','U']
i = 0
j = len(li)-1
while i < j:
if li[i] in vowel and li[j] in vowel:
li[i], li[j] = li[j], li[i]
i += 1
j -= 1
elif li[i] in vowel and li[j] not in vowel:
j -= 1
elif li[j] in vowel and li[i] not in vowel:
i += 1
else:
i += 1
j -= 1
return "".join(li)
680. 验证回文字符串 Ⅱ
给定一个非空字符串 s,最多删除一个字符。判断是否能成为回文字符串。
示例 1:
输入: "aba"
输出: True
示例 2:
输入: "abca"
输出: True
解释: 你可以删除c字符。
注意: 字符串只包含从 a-z 的小写字母。字符串的最大长度是50000。
思路:
如果字符串等于它的倒序,直接返回True。定义两个指针,i从0开始往右扫描,j从列表最后一个元素往左扫描。循环结束条件是 i >= j,如果 s[i] == s[j] ,两指针分别移到下一位置;如果 s[i] != s[j],就看除去 i 位置元素字符串是否回文,或者除去 j 位置元素字符串是否回文,两者有一个成立则返回True,两者都不成立返回False。
代码实现:
class Solution:
def validPalindrome(self, s: str) -> bool:
if s == s[::-1]:
return True
i = 0
j = len(s)-1
while i < j:
if s[i] == s[j]:
i += 1
j -= 1
else:
res1 = s[:i]+s[i+1:]
res2 = s[:j]+s[j+1:]
if res1 == res1[::-1] or res2== res2[::-1]:
return True
else:
return False
return True
88. 合并两个有序数组
给你两个有序整数数组 nums1 和 nums2,请你将 nums2 合并到 nums1 中,使 nums1 成为一个有序数组。
说明:
- 初始化 nums1 和 nums2 的元素数量分别为 m 和 n 。
- 你可以假设 nums1 有足够的空间(空间大小大于或等于 m + n)来保存 nums2 中的元素。
示例:
输入:
nums1 = [1,2,3,0,0,0], m = 3
nums2 = [2,5,6], n = 3
输出: [1,2,2,3,5,6]
思路:
双指针方法:首先判断如果m=0,直接将数组1清空,把数组2 extend过去;两数组指针分别从m和n开始,从后往前遍历,把两者之间较大的从后往前放到数组1;注意当m=0而n != 0的情况。
代码实现:
class Solution:
def merge(self, nums1: List[int], m: int, nums2: List[int], n: int) -> None:
"""
Do not return anything, modify nums1 in-place instead.
"""
if m == 0:
nums1.clear()
nums1.extend(nums2)
while m != 0:
if n > 0 and nums1[m-1] <= nums2[n-1]:
nums1[m+n-1] = nums2[n-1]
n -= 1
else:
nums1[m+n-1] = nums1[m-1]
m -= 1
while n != 0:
nums1[m+n-1] = nums2[n-1]
n -= 1
141. 环形链表
给定一个链表,判断链表中是否有环。
为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。
示例 1:
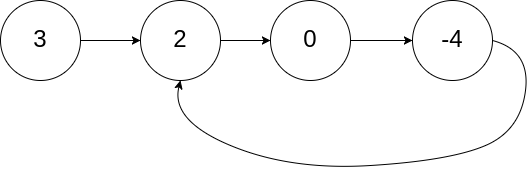
输入:head = [3,2,0,-4], pos = 1
输出:true
解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
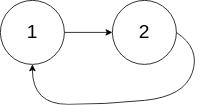
输入:head = [1,2], pos = 0
输出:true
解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:
输入:head = [1], pos = -1
输出:false
解释:链表中没有环。

进阶:你能用 O(1)(即,常量)内存解决此问题吗?
思路:
判断环形链表有一个巧妙的方法就是用到快慢指针,slow指针一次挪动一个节点,fast指针一次挪动两个节点,如果链表没有环,肯定是快指针先走完,两个指针不会相遇;如果链表有环,两个指针最终肯定会在环里绕圈,而两指针速度不同所以一定会相遇。循环结束条件是slow == fast,所以通常一开始都自定义一个节点ListNode(0),这个节点的下一个是head,将slow指向自定义节点而fast指向head,目的是错开俩指针位置以进入循环。此处代码不将slow指向head而fast指向head.next的原因是如果链表只有一个节点,那就没有head下一个为None就没有.next。另外要注意考虑边界情况,fast是否存在,fast.fast是否存在等。
代码实现:
class Solution:
def hasCycle(self, head: ListNode) -> bool:
slow = ListNode(0)
slow.next = head
fast = head
while slow != fast:
if fast and fast.next:
fast = fast.next.next
else:
return False
slow = slow.next
return True
142. 环形链表 II
给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。
说明:不允许修改给定的链表。
示例 1:
输入:head = [3,2,0,-4], pos = 1
输出:tail connects to node index 1
解释:链表中有一个环,其尾部连接到第二个节点。

示例 2:
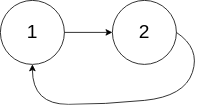
输入:head = [1,2], pos = 0
输出:tail connects to node index 0
解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:
输入:head = [1], pos = -1
输出:no cycle
解释:链表中没有环。

进阶:你是否可以不用额外空间解决此题?
思路:
如果链表有环,快慢指针一定会在环内相遇(相遇证明有环),要找到环的入口,还要进行第二轮,将fast指针重置为head位置,slow保持相遇位置不变,这时fast和slow都是一次走一步,两指针这次相遇的位置即为环的入口。
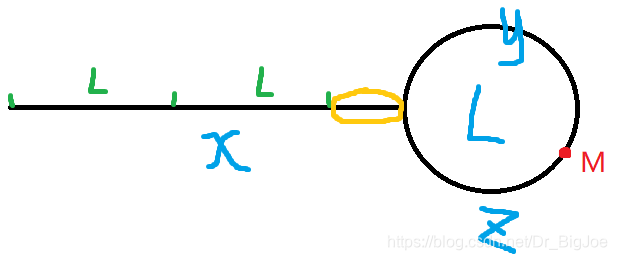
证明:
第二轮当fast从head出发,slow从第一轮相遇点出发,两指针步长均为1,再次相遇时的位置即为环的入口。假设环的长度为L,从head到环入口的长度为x,环入口到相遇点M的长度为y,从相遇点M到环入口的长度为z。假设slow从相遇点M出发,已经走了n圈(nL),则fast从head出发,也同样走了nL,若两指针在环入口相遇,问题转化为证明:x – nL(图中黄色圈出的部分) = z,即 x = nL + z。
第一轮相遇时,Sslow = x + y; Sfast = 2(x + y); 此时fast比slow多走了k个L (k>0),故有:2(x + y) = x + y + kL; => x = kL – y; => x = (k-1)L + z 得证。
代码实现:
class Solution:
def detectCycle(self, head: ListNode) -> ListNode:
slow, fast = head, head
while True:
if fast and fast.next:
slow = slow.next
fast = fast.next.next
if slow == fast:
break
else:
return None
fast = head
while slow != fast:
slow = slow.next
fast = fast.next
return slow
524. 通过删除字母匹配到字典里最长单词
给定一个字符串和一个字符串字典,找到字典里面最长的字符串,该字符串可以通过删除给定字符串的某些字符来得到。如果答案不止一个,返回长度最长且字典顺序最小的字符串。如果答案不存在,则返回空字符串。
示例 1:
输入:
s = "abpcplea", d = ["ale","apple","monkey","plea"]
输出:
"apple"
示例 2:
输入:
s = "abpcplea", d = ["a","b","c"]
输出:
"a"
说明:
所有输入的字符串只包含小写字母。
字典的大小不会超过 1000。
所有输入的字符串长度不会超过 1000。
思路:
定义两个指针分别遍历两个单词,当遍历字典里单词的指针扫描完一整个单词,说明这个单词有可能是结果,把它再和结果字符串进行比较,选择较长的一个单词,若长度相等,返回字典顺序最小的。注意字典顺序是指按照字母表顺序,比如aa<ab,不是按照字符串在本题“字典”中的下标顺序。
代码实现:
class Solution:
def findLongestWord(self, s: str, d):
res = ""
for str_d in d:
j = 0
for i in range(len(s)):
if j < len(str_d):
if s[i] == str_d[j]:
j += 1
if j == len(str_d): # 表示指针j扫描完了d中某个字符串,说明这个字符串可能是要找的
# 字典顺序是指按照字母表顺序,比如aa<ab,不是按照字符串在本题“字典”中的下标顺序
if (len(str_d) > len(res)) or (len(str_d) == len(res) and str_d < res):
res = str_d
return res
二、排序
215. 数组中的第K个最大元素
在未排序的数组中找到第 k 个最大的元素。请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
示例 1:
输入: [3,2,1,5,6,4] 和 k = 2
输出: 5
示例 2:
输入: [3,2,3,1,2,4,5,5,6] 和 k = 4
输出: 4
说明: 你可以假设 k 总是有效的,且 1 ≤ k ≤ 数组的长度。
思路:
直接利用Python内置heapq.nlargest(k, nums)返回前k大的元素。求前k大是建立k个元素的小根堆;求前k小是建立k个元素的大根堆。
代码实现:
import heapq
class Solution:
def findKthLargest(self, nums, k):
li = heapq.nlargest(k, nums)
return li[-1]
347. 前 K 个高频元素
给定一个非空的整数数组,返回其中出现频率前 k 高的元素。
示例 1:
输入: nums = [1,1,1,2,2,3], k = 2
输出: [1,2]
示例 2:
输入: nums = [1], k = 1
输出: [1]
提示:
你可以假设给定的 k 总是合理的,且 1 ≤ k ≤ 数组中不相同的元素的个数。
你的算法的时间复杂度必须优于 O(n log n) , n 是数组的大小。
题目数据保证答案唯一,换句话说,数组中前 k 个高频元素的集合是唯一的。
你可以按任意顺序返回答案。
思路:
用哈希表来存储每个元素出现的次数,Python中字典就是根据哈希表实现的,所以新建一个空字典,以每个数作为键,以每个数出现的次数作为对应的值。按字典的值倒序排列,输出前两个的键。注意字典是无序的,排序之后要传给一个变量,这个变量是排好序的,变量的形式是列表里放着一个一个元组。
代码实现:
class Solution:
def topKFrequent(self, nums, k: int):
hash = {}
for i in range(len(nums)):
if nums[i] not in hash.keys():
hash[nums[i]] = 1
elif nums[i] in hash.keys():
hash[nums[i]] += 1
# print(hash)
# 字典是无序的,排序之后要传给一个变量,这个变量是排好序的
d_order = sorted(hash.items(),key=lambda x:x[1],reverse=True)
# print(d_order)
res = []
for i in range(k):
res.append(d_order[i][0])
return res
451. 根据字符出现频率排序
给定一个字符串,请将字符串里的字符按照出现的频率降序排列。
示例 1:
输入:
"tree"
输出:
"eert"
解释:
'e'出现两次,'r'和't'都只出现一次。
因此'e'必须出现在'r'和't'之前。此外,"eetr"也是一个有效的答案。
示例 2:
输入:
"cccaaa"
输出:
"cccaaa"
解释:
'c'和'a'都出现三次。此外,"aaaccc"也是有效的答案。
注意"cacaca"是不正确的,因为相同的字母必须放在一起。
示例 3:
输入:
"Aabb"
输出:
"bbAa"
解释:
此外,"bbaA"也是一个有效的答案,但"Aabb"是不正确的。
注意'A'和'a'被认为是两种不同的字符。
思路:
利用Python自带的Counter统计每个字符出现的次数,按次数倒序排列并拼接字符串输出。也可以直接利用Counter类的 most_common(),结果就是按出现次数倒序排列的。
代码实现:
import collections
class Solution:
def frequencySort(self, s: str) -> str:
hash = collections.Counter(s)
print(hash)
d_order = sorted(hash.items(),key= lambda x:x[1],reverse=True)
res = []
for i in range(len(d_order)):
res.append(d_order[i][0]*d_order[i][1])
return "".join(res)
直接利用Counter类的 most_common(),一行搞定:
import collections
class Solution:
def frequencySort(self, s: str) -> str:
# Counter(s) 返回一个类似字典的结构,键是s中的项,值是这个项出现的次数
# Counter类有一个函数most_common(int n),列出前n个元素,如果不加参数,就全部返回,相当于按照出现次数从大到小输出
return "".join(k*v for k,v in collections.Counter(s).most_common())
75. 颜色分类
给定一个包含红色、白色和蓝色,一共 n 个元素的数组,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。
此题中,我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。
注意: 不能使用代码库中的排序函数来解决这道题。
示例:
输入: [2,0,2,1,1,0]
输出: [0,0,1,1,2,2]
进阶:
一个直观的解决方案是使用计数排序的两趟扫描算法。
首先,迭代计算出0、1 和 2 元素的个数,然后按照0、1、2的排序,重写当前数组。
你能想出一个仅使用常数空间的一趟扫描算法吗?
思路:
此题是经典的
荷兰国旗
问题,使用三路快排方法效率较高。用两个指针zero,two将数组分为三个区间,用另一个指针p遍历整个数组。定义三个区间,排序完成时:[0,zero)都是0;[zero,two)都是1;[tow:]都是2。用指针p遍历整个数组,将每个元素放到正确的区间,通过移动zero和two,当p超过two时,数组刚好被遍历完一遍,并且是排好序的。
代码实现:
# 三路快排方法:
class Solution:
def sortColors(self, nums):
# 定义三个区间,排序完成时:[0,zero)都是0;[zero,two)都是1;[tow:]都是2
# 用指针p遍历整个数组,将每个元素放到正确的区间,通过移动zero和two
# 当p超过two时,数组刚好被遍历完一遍,并且是排好序的
zero = 0
two = len(nums)-1
p = 0
while p <= two:
if nums[p] == 0:
self.switch(nums, p, zero)
p += 1
zero += 1
elif nums[p] == 1:
p += 1
else: # nums[p] == 2
self.switch(nums, p, two)
two -=1
print(nums)
def switch(self, nums, i, j):
nums[i], nums[j] = nums[j], nums[i]
================================================================
以上为个人学习笔记总结,供学习参考交流,未经允许禁止转载或商用。
- 题目全部出自LeetCode官网:https://leetcode-cn.com/
- 题目分类参考这篇文章:https://github.com/CyC2018/CS-Notes/blob/master/notes/Leetcode%20%E9%A2%98%E8%A7%A3%20-%20%E7%9B%AE%E5%BD%95.md