最近出现一个线上问题,就是导出之后内存使用率激增,并且迟迟释放不掉,导致服务挂掉。首先声明一下出现问题的场景
系统的订单导出,订单字段较多,数据量较大。
产生这个问题的时候第一时间去看了代码
orderService.listOrders(objectToMaps, uid, request, startDate, endDate, page, size, permission, organizationNodeIds,true);
if (objectToMaps.isEmpty()) {
break;
}
Workbook localWorkbook = null;
if (exportFile.exists()) {
try {
localWorkbook = ExcelUtil.load(new FileInputStream(exportFile));
} catch (InvalidFormatException e) {
log.error("error:{}", e);
} catch (IOException e) {
log.error("read excel failed, error:{}", e);
}
}
HSSFWorkbook workbook = null;
if (request.getType() == 3) {
workbook = exportReceiveOrderToWorkbook(uid, operator, objectToMaps, request, startDate, endDate, localWorkbook, count);
count += objectToMaps.size();
} else {
if (withCargoes) {
List<String> orderIds = objectToMaps.parallelStream().map(o -> (String) o.get("id")).collect(Collectors.toList());
Map<String, List<TtmsOrderCargoEntity>> orderCargoes = ttmsOrderModuleService.findAllOrderCargoesByOrderIds(orderIds);
final int[] totalOrders = {objectToMaps.size()};
objectToMaps.forEach(order -> {
String orderId = (String) order.get("id");
List<TtmsOrderCargoEntity> cargoes = orderCargoes.get(orderId);
if (!CollectionUtils.isEmpty(cargoes)) {
order.put("orderCargoes", cargoes);
totalOrders[0] += cargoes.size() - 1;
}
});
workbook = exportOrdersWithCargoesToWorkbook(uid, operator, objectToMaps, request, startDate, endDate, localWorkbook, count);
count += totalOrders[0];
} else {
workbook = exportCustomerOrdersToWorkbook(uid, operator, objectToMaps, request, startDate, endDate, localWorkbook, count);
count += objectToMaps.size();
}
}
if (workbook != null) {
log.info("save export file to {}", exportFile.getAbsolutePath());
try {
FileOutputStream fos = new FileOutputStream(exportFile);
workbook.write(fos);
fos.close();
// workbook.write(fis);
} catch (IOException e) {
log.error("error:", e);
}
}
objectToMaps.clear();
page++;
if (page >= MAX_PAGES) {
break;
}
}
然后发现做法是分批次查询,查询之后写入文件然后将文件写入本地,然后再读进来,将数据增量写入,这样做的初衷可能是为了提高效率,但是确为后面埋下了一个深坑。
内存占用率一直居高不下,并且如果说短时间内多做几次导出的时候导致的是永久代内存溢出。本地设置的1G的JVM,但是在开始导出的时候内存从200+M直线飙升到700M左右
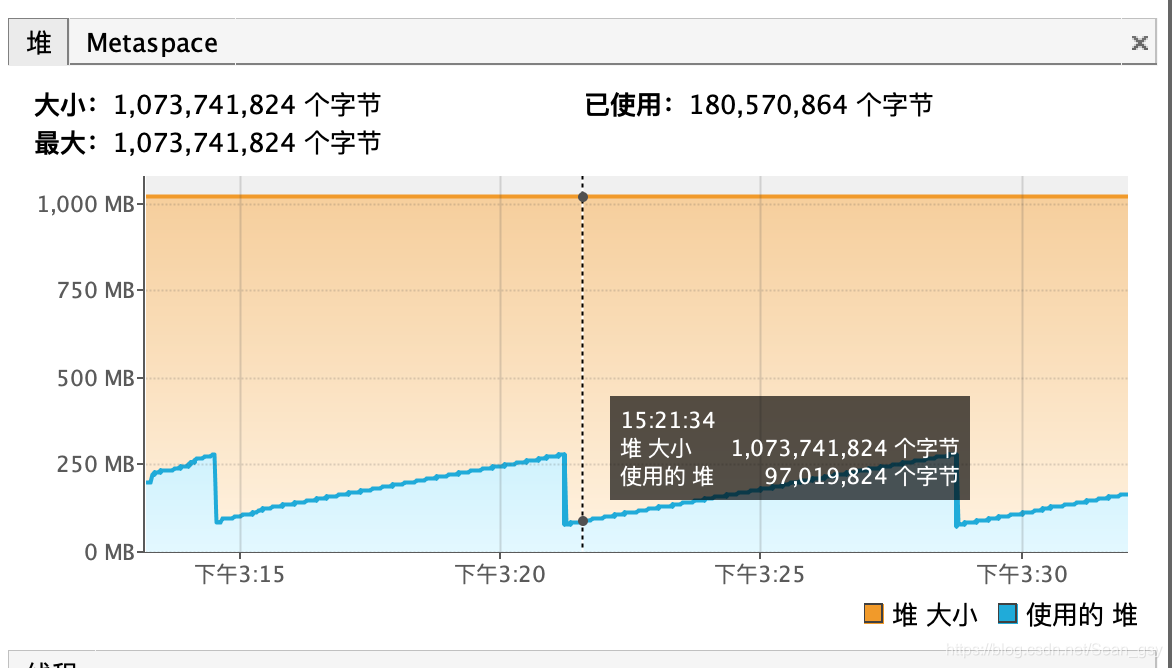
上面是正常的情况下本地的内存
打开visualVM大致看一下gc的回收频率,发现这段时间GC在频繁的youngGC,初步猜测是导出的时候查询的数据量比较大,但是后来改为两百条查一次,还是没有变动,排除数据问题
这个时候猜测是poi提供的API的问题,而且这个时候youngGC之后内存一直没有减少,一直保持在增长之后的水平,并没有GC掉很多对象,初步猜测是因为对象太大直接进入老年代。这个时候导出已经完成了,再看内存,依然是保持在刚才的水平,过了大概五分多钟之后,来了一次FullGC,内存直接从700降到300左右,初步判断是因为老年代GC需要进行多次标记(GC回收算法)。
在修改代码之前发现用的是HSSFWorkBook,后来去看了一下说明,HSSFWorkbook只能操作excel2003一下版本,XSSFWorkbook只能操作excel2007以上版本,而且看了很多网上说的方式,但是并没有任何解决方案。
从POI 3.8版本开始,提供了一种基于XSSF的低内存占用的API—-SXSSFWorkBook,所以我们就用了这个版本的来替代以前旧版本的API,但是问题好像并没有解决,反而更加严重了。
那么我猜测是新版本的API不适合这样的操作。后来去看了一下文档,发现最新版本的SXSSFWorkBook适合大量数据操作而且不会占用太大的内存,那么为什么我们用的时候依然会出现这样的问题呢?用法不对?是的,没错。
以前的时候为了效率我们采用先创建写入数据,然后保存文件,然后读文件增量写入,如此往复。但是这样的可能适合以前的版本,并不适用于新版本的API,开始行动,不保存文件,分批次查询数据,分批次写入SXSSFWorkBook。跑起来之后发现内存的使用率是有所上升,而且youngGC的频率很高,但是并没有出现内存直线飙升的现象。而且在波动之后内存回归正常,并没有出现内存一直释放不掉只能等FullGC的情况。所以还是用法的问题,还是需要多看文档
回顾一下问题,为什么之前版本的会一直常驻在内存等待FullGC呢?猜测是因为以前版本的API占用内存确实较大,对象过大直接进入老年代,而老年代的GC回收频率比不上年轻代,所以GC需要去标记判断很多次才会把对象回收掉。而且另外一点就是我们的做法,创建对象,写出到文件,读文件,写入数据,写出文件 ,读文件……如此往复更加是雪上加霜。所以此次的问题主要还是代码待优化,没有理解官方给出的用法
如果有理解上的错误,还有待各位大神提出见解