HBase高可用
在HBase中Hmaster负责监控RegionServer的生命周期,均衡RegionServer的负载,如果Hmaster挂掉了,那么整个HBase集群将陷入不健康的状态,并且此时的工作状态并不会维持太久。所以HBase支持对Hmaster的高可用配置。
1)
关闭
HBase
集群(如果没有开启则跳过此步)
|
$ bin/stop-hbase.sh |
2)
在
conf
目录下创建
backup-masters
文件
|
$ touch conf/bac |
3)
在
backup-masters
文件中配置高可用
HMaster
节点
|
$ echo |
4)
将整个
conf
目录
scp
到其他节点
|
$ scp -r conf/
|
5)
重新启动
HBase
后打开页面测试查看
2.Hadoop的通用性优化
1) NameNode
元数据备份使用
SSD
2)
定时备份
NameNode
上的元数据
每小时或者每天备份,如果数据极其重要,可以5~10分钟备份一次。备份可以通过定时任务复制元数据目录即可。
3)
为
NameNode
指定多个元数据目录
使用
dfs.name.dir
或者
dfs.namenode.name.dir
指定。这样可以提供元数据的冗余和健壮性,以免发生故障。
4) NameNode
的
dir
自恢复
设置dfs.namenode.name.dir.restore为true,允许尝试恢复之前失败的dfs.namenode.name.dir目录,在创建checkpoint时做此尝试,如果设置了多个磁盘,建议允许。
5) HDFS
保证
RPC
调用会有较多的线程数
hdfs-site.xml
|
属性:
|
6) HDFS
副本数的调整
hdfs-site.xml
|
属性:
|
7) HDFS
文件块大小的调整
hdfs-site.xml
|
属性:
|
8) MapReduce Job
任务服务线程数调整
mapred-site.xml
|
属性:
|
9) Http
服务器工作线程数
mapred-site.xml
|
属性:
|
10)
文件排序合并优化
mapred-site.xml
|
属性:
|
11)
设置任务并发
mapred-site.xml
|
属性:
|
12) MR
输出数据的压缩
mapred-site.xml
|
属性:
|
13)
优化
Mapper
和
Reducer
的个数
mapred-site.xml
|
属性:
|
大概估算公式:
map = 2 + ⅔cpu_core
reduce = 2 + ⅓cpu_core
3.Linux优化
1)
开启文件系统的预读缓存可以提高读取速度
|
$ sudo blockdev –setra 32768 /dev/sda |
注意:
ra是readahead的缩写
2)
关闭进程睡眠池
即不允许后台进程进入睡眠状态,如果进程空闲,则直接kill掉释放资源
|
$ sudo sysctl -w |
3)
调整
ulimit
上限,默认值为比较小的数字
|
$
|
优化修改:
|
$ sudo vi /etc/security/limits.conf
|
4)
开启集群的时间同步
NTP
集群中某台机器同步网络时间服务器的时间,集群中其他机器则同步这台机器的时间。
5)
更新系统补丁
更新补丁前,请先测试新版本补丁对集群节点的兼容性。
4.Zookeeper优化
1)
优化
Zookeeper
会话超时时间
hbase-site.xml
|
参数:
|
5.HBase优化
编码和压缩
如果是限定符占的空间较大,建议使用数据块编码。
如果是值占的空间较大,建议使用压缩器
预分区
每一个region维护着startRow与endRowKey,如果加入的数据符合某个region维护的rowKey范围,则该数据交给这个region维护。
那么依照这个原则,我们可以将数据索要投放的分区提前大致的规划好,以提高HBase性能。
1)
手动设定预分区
|
hb |
2)
生成
16
进制序列预分区
|
create ‘staf |
3)
按照文件中设置的规则预分区
创建splits.txt文件内容如下:
|
aaaa
|
然后执行:
|
create ‘ |
4)
使用
JavaAPI
创建预分区
|
//
|
内存优化
HBase操作过程中需要大量的内存开销,毕竟Table是可以缓存在内存中的,一般会分配整个可用内存的70%给HBase的Java堆。但是不建议分配非常大的堆内存,因为GC过程持续太久会导致RegionServer处于长期不可用状态,一般16~48G内存就可以了,如果因为框架占用内存过高导致系统内存不足,框架一样会被系统服务拖死。
基础优化
1)
允许在HDFS
的文件中追加内容
不是不允许追加内容么?没错,请看背景故事:
http://blog.cloudera.com/blog/2009/07/file-appends-in-hdfs/
hdfs-site.xml
、hbase-site.xml
|
属性:
|
2)
优化DataNode
允许的最大文件打开数
hdfs-site.xml
|
属性
|
3)
优化延迟高的数据操作的等待时间
hdfs-site.xml
|
属性:
|
4)
优化数据的写入效率
mapred-site.xml
|
属性:
|
5)
优化DataNode
存储
|
属性:
|
6)
设置RPC
监听数量
hbase-site.xml
|
属性:
|
7)
优化HStore
文件大小
hbase-site.xml
|
属性:
|
8)
优化hbase
客户端缓存
hbase-site.xml
|
属性:
|
9)
指定scan.next
扫描HBase
所获取的行数
hbase-site.xml
|
属性:
|
10) flush
、compact
、split
机制
当
MemStore
达到阈值,将
Memstore
中的数据
Flush
进
Storefile
;
c
ompact机制则是
把
flush
出来的小文件合并成大的
Storefile
文件。
split则是
当
Region
达到阈值,会把过大的
Region
一分为二。
涉及属性:
即:
128M
就是
Memstore
的默认阈值
|
hbase.hregion.memstore.flush.size |
即:这个参数的作用是当单个
HRegion
内所有的
Memstore
大小总和超过指定值时,
flush
该
HRegion
的所有
memstore
。
RegionServer
的
flush
是通过将请求添加一个队列,模拟生产消费模型来异步处理的。那这里就有一个问题,当队列来不及消费,产生大量积压请求时,可能会导致内存陡增,最坏的情况是触发
OOM
。
|
hbase.regionserver.global.memstore.upperLimit
|
即:当
MemStore
使用内存总量达到
hbase.regionserver.global.memstore.upperLimit
指定值时,将会有多个
MemStores flush
到文件中,
MemStore flush
顺序是按照大小降序执行的,直到刷新到
MemStore
使用内存略小于
lowerLimit
6.Master和RegionServer的JVM调优
先调大堆内存
这往往是出问题的第一环节。由于默认的RegionServer的内存才1GB,而Memstore默认是占40%,所以分配给Memstore的才400MB,在实际场景下,很容易就写阻塞了。你可以通过指定HBASE_HEAPSIZE参数来调整所有HBase实例(不管是Master还是RegionServer)占用的内存大小。方法是:

这个参数会影响所有HBase实例,包括Master和Region。这样的话Master和RegionServer都会占用8GB。不过我建议大家用Master和RegionServer专有的参数来分别设定他们的内存大小。
- PermSize的调整

提示
这两句配置的意思是Master和RegionServer的永久对象区(Permanent Generation,这个区域在非堆内存里面)占用了128MB的内存。根据注释的意思是这个配置存在的意义是为了在JDK 7下可以安全运行实例,所以如果你用的是JDK 8可以删掉这两行,并且由于JDK 8已经去除了PermGen,所以设置了也没用。
如果你用的是JDK 8之前的版本,此时RegionServer发生内存泄露问题,并且日志提示:OOM
如果你确定已经把Xmx调得比较大了,那就需要把PermSize和MaxPermSize都调大一些(一般不会出现这种情况,调成128MB已经算比较大了)。
现在回归到设置JVM使用的最大内存话题上,在这两行的下面加上:

这样就把Master的JVM内存设置为4GB,把RegionServer的内存设置为8GB了
这里只是举例说明Master可以调整内存为4GB,但是不代表Master的最优内存大小就是4GB,具体的内存大小需要根据你自己的机器情况来调整。
请永远至少留10%的内存给操作系统来进行必要的操作
可怕的Full GC
随着内存的加大,有一个不容忽视的问题也出现了,那就是JVM的堆内存越大,Full GC的时间越久。Full GC有时候可以达到好几分钟。
在Full GC的时候JVM会停止响应任何的请求,整个JVM的世界就像是停止了一样,所以这种暂停又被叫做Stop-The-World(STW)。
当ZooKeeper像往常一样通过心跳来检测RegionServer节点是否存活的时候,发现已经很久没有接收到来自RegionServer的回应,会直接把这个RegionServer标记为已经宕机。等到这台RegionServer终于结束了Full GC后,去查看ZooKeeper的时候会发现原来自己已经“被宕机”了,为了防止脑裂问题的发生,它会自己停止自己。这种场景称为RegionServer自杀,它还有另一个美丽的名字叫朱丽叶暂停,而且这问题还挺常见的,早期一直困扰着HBase开发人员。所以我们一定要设定好GC回收策略,避免长时间的Full GC发生,或者是尽量减小Full GC的时间。
- GC回收策略优化
由于数据都是在RegionServer里面的,Master只是做一些管理操作,所以一般内存问题都出在RegionServer上。接下来主要用RegionServer来讲解参数配置,如果你想调整Master的内存参数,只需要把HBASE_REGIONSERVER_OPTS换成HBASE_MASTER_OPTS就行了。
JVM提供了4种GC回收器:
串行回收器(SerialGC)。
并行回收器(ParallelGC),主要针对年轻带进行优化(JDK 8默认策略)。
并发回收器(ConcMarkSweepGC,简称CMS),主要针对年老带进行优化。
G1GC回收器,主要针对大内存(32GB以上才叫大内存)进行优化。
- ParallelGC和CMS的组合方案
并行收回器的性能虽然没有串行回收器那么好,但是Full GC时间较短。对于RegionServer来说,Full GC是致命的,就算性能下降一些也没有关系,所以我们最好使用并行回收器。
并发回收器主要是减少老年代的暂停时间,可以保证应用不停止的情况下进行收集。但是它也有缺点,那就是每次都会留下一些“浮动垃圾”。这些浮动垃圾只能在下次垃圾回收的时候被回收,不过这些我们也可以忍受。
基于以上描述比较符合HBase的配置是:
年轻带使用并行回收器ParallelGC。
年老带使用并发回收器ConcMarkSweepGC。
修改的方式还是修改$HBASE_HOME/conf/hbase-env.sh,在我们前面修改xms和xmx的地方加上-XX:+UseParNewGCXX:+UseConcMarkSweepGC,就像这样:

- G1GC方案
如果你的JDK版本大于1.7.0_04(JDK7 update4),并且你的RegionServer内存大于4GB(换句话说如果小于4GB就不用考虑G1GC了,直接用ParallelGC + CMS),你可以考虑使用G1GC策略,这是JDK 7新加入的策略。不过仅仅是考虑,请不要不进行测试比较就直接改为G1GC。
这种策略专门适用于堆内存很大的情况。引入G1GC策略的原因是,就算采用了CMS策略,我们还是不能避免Full GC。因为在以下两种情况下,CMS还是会触发Full GC:
在CMS工作的时候,有一些对象要从年轻代移动到老年代,但是此时老年代空间不足了,此时只能触发Full GC,然后引发STW(Stop The World)暂停,JVM又开始不响应任何请求了。当被回收掉的内存空间太碎太细小,导致新加入老年代的对象放不进去,只好触发Full GC来整理空间,JVM还是会进入不响应任何请求的状态。
G1GC策略通过把堆内存划分为多个Region,然后对各个Region单独进行GC,这样整体的Full GC可以被最大限度地避免(Full GC还是不可避免的,我们只是尽力延迟Full GC的到来时间),而且这种策略还可以通过手动指定MaxGCPauseMillis参数来控制一旦发生Full GC的时候的最大暂停时间,避免时间太长造成RegionServer自杀。设置的方式是:

没有哪种策略是最好的,如果有的话JVM早就把别的策略都删除了,所以究竟是使用并行回收器和并发回收器的组合,还是使用G1GC,这还得靠大家通过具体试验来判断。不过还是有一些简单的方式可以决定使用哪种策略:
如果你的RegionServer内存小于4GB,就不需要考虑G1GC策略了,直接用-XX:+UseParNewGC-XX:+UseConcMarkSweepGC。
如果你的RegionServer内存大于32GB,建议使用G1GC策略。
试验的时候或者运行的时候都要记得把调试参数加上:
![]()
这样才能看到试验的量化结果,为试验提供更详细的信息。在此引用Justin Kestelyn在文章Tuning Java Garbage Collection for HBase中经过测试得出的调优参数结果,供大家参考:
32GB heap的时候,-XX:G1NewSizePercent=3。
64GB heap的时候,-XX:G1NewSizePercent=2。
100GB或者更大的内存的时候,-XX:G1NewSizePercent=1。
其他参数:
-XX:+UseG1GC。
-Xms100g -Xmx100g(文中做实验的堆内存大小)。
-XX:MaxGCPauseMillis=100。
-XX:+ParallelRefProcEnabled。
-XX:-ResizePLAB。
-XX:ParallelGCThreads= 8+(40-8)(5/8)=28。
-XX:G1NewSizePercent=1。
Memstore的专属JVM策略MSLAB
现在要提到一个全新的策略MSLAB,虽然它目的也是减少Full GC,但是它的意义不止于此,所以我并没有把MSLAB放到“可怕的Full GC”小节中。就像我之前说的,堆内存足够大的时候发生Full GC的停留时间可以长达好几分钟。解决这个问题不能完全靠JVM的GC回收策略,最好的解决方案是从应用本身入手,自己来管好自己的内存空间。
随着硬件科技的进步,现在的服务器内存可以达到32GB、64GB甚至100GB,人们发现就算是使用CMS策略来进行垃圾回收(GC),依然会触发Full GC。但是在2GB、4GB的时代,一次Full GC最多也就几十秒,不会超过一分钟;但是随着内存的加大,Full GC的时间逐渐变长。增加的速率是8~10秒/G。你可以想象一下拥有100GB的堆内存的
RegionServer进行一次Full GC究竟要花费多少时间。而采用了CMS后还是发生Full GC的原因是:
(1)同步模式失败(concurrent mode failure):在CMS还没有把垃圾收集完的时候空间还没有完全释放,而这个时候如果新生代的对象过快地转化为老生代的对象时发现老生代的可用空间不够了。此时收集器会停止并发收集过程,转为单线程的STW(Stop The World)暂停,这就又回到了Full GC的过程了。
不过这个过程可以通过设置-XX:CMSInitiatingOccupancyFraction=N来缓解。N代表了当JVM启动垃圾回收时的堆内存占用百分比。你设置的越小,JVM越早启动垃圾回收进程,一般设置为70。
(2)由于碎片化造成的失败(Promotion Failure due to Fragmentation):当前要从新生代提升到老年代的对象比老年代的所有可以使用的连续的内存空间都大。比如你当前的老年代里面有500MB的空间是可以用的,但是都是1KB大小的碎片空间,现在有一个2KB的对象要提升为老年代却发现没有一个空间可以插入。这时也会触发STW暂停,进行Full GC。这个问题无论你把-XX:CMSInitiatingOccupancyFraction=N调多小都是无法解决的,因为CMS只做回收不做合并,所以只要你的RegionServer启动得够久一定会遇上Full GC。
很多人可能会疑惑为什么会出现碎片内存空间?
我们知道Memstore是会定期刷写成为一个HFile的,在刷写的同时这个Memstore所占用的内存空间就会被标记为待回收,一旦被回收了,这部分内存就可以再次被使用,但是由于JVM分配对象都是按顺序分配下去的,所以你的内存空间使用了一段时间后的情况如图

假设红色块占用的内存大小都是1KB,此时有一个2KB大小的对象从新生代升级到老生代,但是此时JVM已经找不到连续的2KB内存空间去放这个新对象了,如图
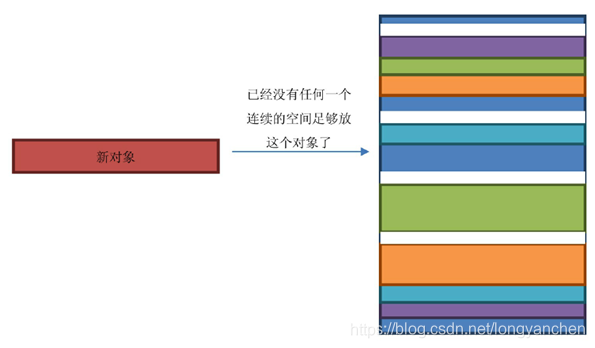
此时的堆内存就像一个瑞士奶酪(Swiss Cheese),如图

JVM也没有办法,为了不让情况继续地恶化下去,只好停止接收一切请求,然后启用一个单独的进程来进行内存空间的重新排列。这个排列的时间随着内存空间的增大而增大,当内存足够大的时候,暂停的时间足以让ZooKeeper认为我们的RegionServer已死。
其实JVM为了避免这个问题有一个基于线程的解决方案,叫TLAB(Thread-Local allocation buffer)。当你使用TLAB的时候,每一个线程都会分配一个固定大小的内存空间,专门给这个线程使用,当线程用完这个空间后再新申请的空间还是这么大,这样下来就不会出现特别小的碎片空间,基本所有的对象都可以有地方放。缺点就是无论你
的线程里面有没有对象都需要占用这么大的内存,其中有很大一部分空间是闲置的,内存空间利用率会降低。不过能避免Full GC,这些都是值得的。
但是HBase不能直接使用这个方案,因为在HBase中多个Region是被一个线程管理的,多个Memstore占用的空间还是无法合理地分开。于是HBase就自己实现了一套以Memstore为最小单元的内存管理机制,称为MSLAB(Memstore-Local Allocation Buffers)。这套机制完全沿袭了TLAB的实现思路,只不过内存空间是由Memstore来分配的。MSLAB的具体实现如下:
引入chunk的概念,所谓的chunk就是一块内存,大小默认为2MB。
RegionServer中维护着一个全局的MemStoreChunkPool实例,从名字很容看出,是一个chunk池。
每个MemStore实例里面有一个MemStoreLAB实例。
当MemStore接收到KeyValue数据的时候先从ChunkPool中申请一个chunk,然后放到这个chunk里面。
如果这个chunk放满了,就新申请一个chunk。
如果MemStore因为刷写而释放内存,则按chunk来清空内存。
由此可以看出堆内存被chunk区分为规则的空间,这样就消除了小碎片引起的无法插入数据问题,但是会降低内存利用率,因为就算你的chunk里面只放1KB的数据,这个chunk也要占2MB的大小。不过,为了不发生Full GC,这些都可以忍。
跟MSLAB相关的参数是:
hbase.hregion.memstore.mslab.enabled:设置为true,即打开MSLAB,默认为true。
hbase.hregion.memstore.mslab.chunksize:每个chunk的大小,默认为2048 * 1024 即2MB。
hbase.hregion.memstore.mslab.max.allocation:能放入chunk的最大单元格大小,默认为256KB,已经很大了。
hbase.hregion.memstore.chunkpool.maxsize:在整个memstore可以占用的堆内存中,chunkPool占用的比例。该值为一个百分比,取值范围为0.0~1.0。默认值为0.0。
hbase.hregion.memstore.chunkpool.initialsize:在RegionServer启动的时候可以预分配一些空的chunk出来放到chunkPool里面待使用。该值就代表了预分配的chunk占总的chunkPool的比例。该值为一个百分比,取值范围为0.0~1.0,默认值为0.0。
你可能会觉得G1GC跟MSLAB的实现思路非常接近,那为什么还要发明MSLAB策略呢?因为G1GC是MSLAB发明后才出现的策略。
7.Region的拆分
通过查询hbase:meta我们可以形象地看到,一个Region就是一个表的一段Rowkey的数据集合。当Region太大的时候HBase会拆分它。
- 为什么要拆分Region
因为当某个Region太大的时候读取效率太低了。
大家可以想想我们为什么从MySQL、Oracle转移到NoSQL来?
最根本的原因就是这些关系型数据库把数据放到一个地方,查询的本质其实也就是遍历key;而当数据增大到上亿的时候同一个磁盘已经无法应付这些数据的读取了,因为遍历一遍数据的时间实在太长了。我们用NoSQL的理由就是其能把大数据分拆到不同的机器上,然后就像查询一个完整的数据一样查询他们。
但是当你的Region太大的时候,此时这个Region一样会遇到跟传统关系型数据库一样的问题,所以HBase会拆分Region。这也是HBase的一个优点,有些人会介绍HBase为“一个会自动分片的数据库”。Region的拆分分为自动拆分和手动拆分。自动拆分可以采用不同的策略。
Region的自动拆分
- ConstantSizeRegionSplitPolicy
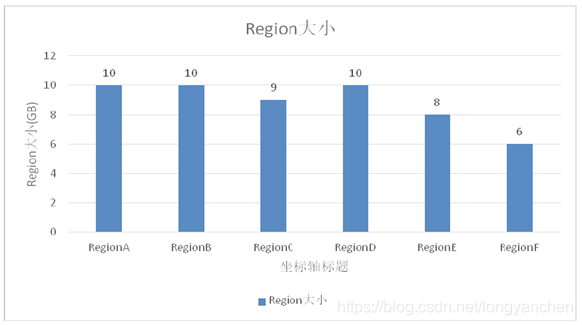
早在0.94版本的时候HBase只有一种拆分策略ConstantSizeRegionSplitPolicy。这个策略非常简单,从名字上就可以看出这个策略就是按照固定大小来拆分Region。它唯一用到的参数是:
![]()
当单个Region大小超过了10GB,就会被HBase拆分成为2个Region。采用这种策略后的集群中的Region大小很平均
- IncreasingToUpperBoundRegionSplitPolicy
0.94版本之后,有了IncreasingToUpperBoundRegionSplitPolicy策略。这种策略从名字上就可以看出是限制不断增长的文件尺寸的策略。我们以前使用传统关系型数据库的时候或许有这样的经验,有的数据库的文件增长是翻倍增长的,比如第一个文件是64MB,第二个就是128MB,第三个就是256MB。这种策略就是模仿此类情况来实现的。文件尺寸限制是动态的,依赖以下公式来计算:
![]()
tableRegionCount:表在所有RegionServer上所拥有的Region数量总和。
initialSize:
如果你定义了hbase.increasing.policy.initial.size,则使用这个数值;
如果没有定义,就用memstore的刷写大小的2倍,即hbase.hregion.memstore.flush.size * 2。
defaultRegionMaxFileSize:ConstantSizeRegionSplitPolicy所用到的hbase.hregion.max.filesize,即Region最大大小。
Math.min:取这两个数值的最小值。
假如hbase.hregion.memstore.flush.size定义为128MB,那么文件尺寸的上限增长将是这样:
(1)刚开始只有一个文件的时候,上限是256MB,因为1^3 *128*2 = 256MB。
(2)当有2个文件的时候,上限是2GB,因为2^3 * 128*2 =2048MB。
(3)当有3个文件的时候,上限是6.75GB,因为3^3 * 128 * 2 =6912MB。
(4)以此类推,直到计算出来的上限达到hbase.hregion.max.filesize region所定义的10GB。
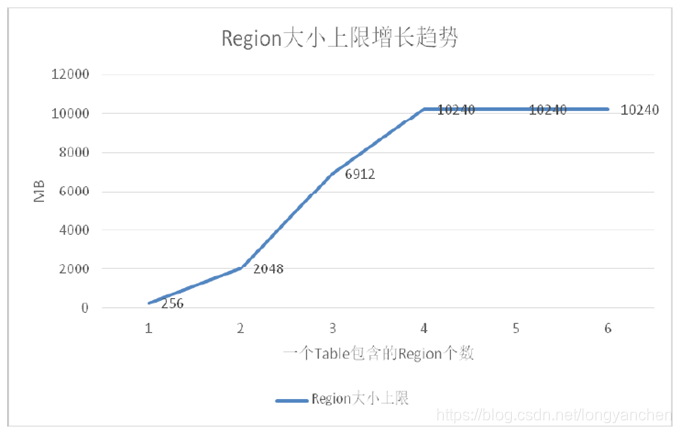
当Region个数达到4个的时候由于计算出来的上限已经达到了16GB大于10GB了,所以后面当Region数量再增加的时候文件大小上限已经不会增加了。
在最新的版本里
IncreasingToUpperBoundRegionSplitPolicy
是默认的配置。
- KeyPrefixRegionSplitPolicy
除了简单粗暴地根据大小来拆分,我们还可以自己定义拆分点。KeyPrefixRegionSplitPolicy 是IncreasingToUpperBoundRegionSplitPolicy的子类,在前者的基础上增加了对拆分点(splitPoint,拆分点就是Region被拆分处的rowkey)的定义。它保证了有相同前缀的rowkey不会被拆分到两个不同的Region
里面。
这个策略用到的参数是:KeyPrefixRegionSplitPolicy.prefix_length rowkey:前缀长度
该策略会根据KeyPrefixRegionSplitPolicy.prefix_length所定义的长度来截取rowkey作为分组的依据,同一个组的数据不会被划分到不同的Region上。
用默认策略拆分跟用KeyPrefixRegionSplitPolicy拆分的区别如图
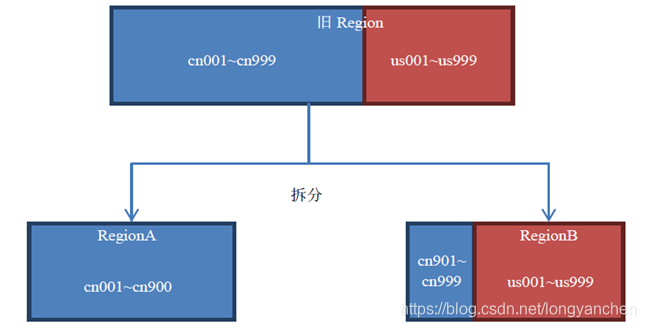
用KeyPrefixRegionSplitPolicy拆分的结果,如图
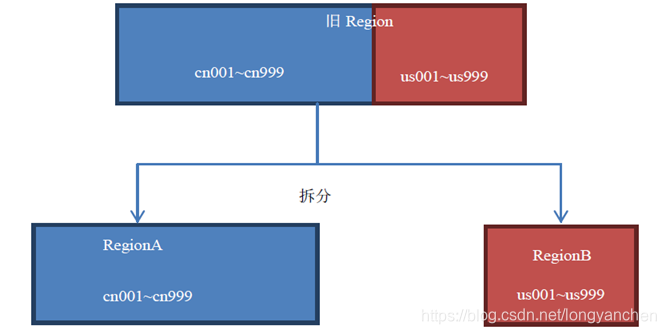
在这种场景下,按照默认的配置肯定会把同一个前缀的数据切分到不同的Region上。如果你的所有数据都只有一两个前缀,那么KeyPrefixRegionSplitPolicy就无效了,此时采用默认的策略较好。如果你的前缀划分的比较细,你的查询就比较容易发生跨Region查询的情况, 此时采用KeyPrefixRegionSplitPolicy较好。
所以这个策略适用的场景是:
数据有多种前缀。
查询多是针对前缀,比较少跨越多个前缀来查询数据。
- DelimitedKeyPrefixRegionSplitPolicy
该策略也是继承自IncreasingToUpperBoundRegionSplitPolicy,它也是根据你的rowkey前缀来进行切分的。唯一的不同就是:
KeyPrefixRegionSplitPolicy是根据rowkey的固定前几位字符来进行判断,而DelimitedKeyPrefixRegionSplitPolicy是根据分隔符来判断的。在有些系统中rowkey的前缀可能不一定都是定长的,比如你拿服务器的名字来当前缀,有的服务器叫host12有的叫host1。这些场景下严格地要求所有前缀都定长可能比较难,而且这个定长如果未来想改也不容易。DelimitedKeyPrefixRegionSplitPolicy就给了你一个定义长度字符前缀的自由。使用这个策略需要在表定义中加入以下属性:DelimitedKeyPrefixRegionSplitPolicy.delimiter:前缀分隔符比如你定义了前缀分隔符为_,那么host1_001和host12_999的前缀就分别是host1和host12。
- BusyRegionSplitPolicy
此前的拆分策略都没有考虑热点问题。所谓热点问题就是数据库中的Region被访问的频率并不一样,某些Region在短时间内被访问的很频繁,承载了很大的压力,这些Region就是热点Region。BusyRegionSplitPolicy就是为了解决这种场景而产生的。它是如何判断哪个Region是热点的呢
先要介绍它用到的参数:
hbase.busy.policy.blockedRequests:请求阻塞率,即请求被阻塞的严重程度。取值范围是0.0~1.0,默认是0.2,即20%的请求被阻塞的意思。
hbase.busy.policy.minAge:拆分最小年龄,当Region的年龄比这个小的时候不拆分,这是为了防止在判断是否要拆分的时候出现了短时间的访问频率波峰,结果没必要拆分的Region被拆分了,因为短时间的波峰会很快地降回到正常水平。单位毫秒,默认值是600000,即10分钟。
hbase.busy.policy.aggWindow:计算是否繁忙的时间窗口,单位毫秒,默认值是300000,即5分钟。用以控制计算的频率。
计算该Region是否繁忙的计算方法如下:
如果“当前时间–上次检测时间>=hbase.busy.policy.aggWindow”,则进行如下计算:这段时间被阻塞的请求/这段时间的总请求 = 请求的被阻塞率(aggBlockedRate)
如果“aggBlockedRate >hbase.busy.policy.blockedRequests”,则判断该Region为繁忙。
如果你的系统常常会出现热点Region,而你对性能有很高的追求,那么这种策略可能会比较适合你。它会通过拆分热点Region来缓解热点Region的压力,但是根据热点来拆分Region也会带来很多不确定性因素,因为你也不知道下一个被拆分的Region是哪个。
- DisabledRegionSplitPolicy
这种策略其实不是一种策略。如果你看这个策略的源码会发现就一个方法shouldSplit,并且永远返回false。聪明的你一定一下就猜到了,设置成这种策略就是Region永不自动拆分。
如果使用DisabledRegionSplitPolicy让Region永不自动拆分之后,你依然可以通过手动拆分来拆分Region。
这个策略有什么用
无论你设置了哪种拆分策略,一开始数据进入Hbase的时候都只会往一个Region塞数据。必须要等到一个Region的大小膨胀到某个阀值的时候才会根据拆分策略来进行拆分。但是当大量的数据涌入的时候,可能会出现一边拆分一边写入大量数据的情况,由于拆分要占用大量IO,有可能对数据库造成一定的压力。如果你事先就知道这个Table应该按怎样的策略来拆分Region的话,你也可以事先定义拆分点(SplitPoint)。所谓拆分点就是拆分处的rowkey,比如你可以按26个字母来定义25个拆分点,这样数据一到HBase就会被分配到各自所属的Region里面。这时候我们就可以把自动拆分关掉,只用手动拆分。手动拆分有两种情况:预拆分(pre-splitting)和强制拆分(forced splits)。
Region的预拆分
预拆分(pre-splitting)就是在建表的时候就定义好了拆分点的算法,所以叫预拆分。使用org.apache.hadoop.hbase.util.RegionSplitter类来创建表,并传入拆分点算法就可以在建表的同时定义拆分点算法。
我们要新建一张表,并且规定了该表的Region数量永远只有10个

上面这条命令的意思就是新建一个叫my_split_table的表,并根据HexStringSplit拆分点算法预拆分为10个Region,同时要建立的列族叫mycf。
HexStringSplit把数据从“00000000”到“FFFFFFFF”之间的数据长度按照n等分之后算出每一段的起始rowkey和结束rowkey,以此作为拆分点。完毕,就是这么简单。
UniformSplit有点像HexStringSplit的byte版,不管传参还是n,唯一不一样的是起始和结束不是String,而是byte[]。
起始rowkey是ArrayUtils.EMPTY_BYTE_ARRAY。
结束rowkey是new byte[] {xFF, xFF, xFF, xFF, xFF, xFF,xFF, xFF}。
最后调用Bytes.split方法把起始rowkey到结束rowkey之间的长度n等分,然后取每一段的起始和结束作为拆分点。
默认的拆分点算法就这两个。你还可以通过实现SplitAlgorithm接口实现自己的拆分算法。或者干脆手动定出拆分点。
手动指定拆分点的方法就是在建表的时候跟上SPLITS参数

Region的强制拆分
除了预拆分和自动拆分以外,你还可以对运行了一段时间的Region进行强制地手动拆分(forced splits)。方法是调用hbase shell的split方法,

这个就是把test_table1,c,1476406588669.96dd8c68396fda69这个Region从新的拆分点999处拆成2个Region。
split方法的调用方式:
split ‘tableName’
split ‘namespace:tableName’
split ‘regionName’ # format: ‘tableName,startKey,id’
split ‘tableName’, ‘splitKey’
split ‘regionName’, ‘splitKey’
总结
一开始可以先定义拆分点,但是当数据开始工作起来后会出现热点不均的情况,所以推荐的方法是:
(1)用预拆分导入初始数据。
(2)然后用自动拆分来让HBase来自动管理Region。
建议:不要关闭自动拆分。
Region的拆分对性能的影响还是很大的,默认的策略已经适用于大多数情况。
如果要调整,尽量不要调整到特别不适合你的策略,比如设置成KeyPrefixRegionSplitPolicy,然后还用时间戳来做rowkey。
一种策略的选择要看多方面因素,有可能你的集群同时适合多种策略,这样就要看哪种策略效果最好了。如果无法计算出来,就一个一个地尝试过去,用实践来检验真理。
8.Region的合并
Region可以被拆分,也可以被合并。不过Region的合并(merge)并不是为了性能考虑的,而更多地是出于维护的目的被创造出来的。
啥时候才会用到合并呢
比如你删了大量的数据,每个Region都变小了,这个时候分成这么多个Region就有点浪费了,可以把Region合并起来,然后可以减少一些RegionServer服务器来节省成本。
通过Merge类合并Region
合并通过使用org.apache.hadoop.hbase.util.Merge类来实现,具体做法在下面说明。
举个例子,比如我想把以下两个Region合并:
test_table1,b,1476406588669.39eecae03539ba0a63264c24130c2cb1.
test_table1,c,1476406588669.96dd8c68396fda694ab9b0423a60a4d9.
就需要在Linux下(不需要进入hbase shell)执行以下命令:
得先把集群给下线了才行,先把HMaster和所有的HRegionServer全部都停掉,再执行

不过每次merge都要关闭整个HBase这也太麻烦了,好在后来HBase又增加了online_merge。我管通过Merge类来合并叫冷合并,oneline_merge叫热合并。
热合并
hbase shell提供了一个命令叫online_merge,通过这个方法可以进行热合并(online_merge)。我举个例子说明这个命令怎么用。比如
要合并以下两个Region:
test_table1,a,1476406588669.d1f84781ec2b93224528cbb79107ce12.
test_table1,b,1476408648520.d129fb5306f604b850ee4dc7aa2eed36.
online_merge的传参是Region的hash值,Region的hash值就是Region名最后那段在两个.号之间的字符串。
比如:
(1)Region的名字叫test_table1,a,1476406588669.d1f84781ec2b93224528cbb79107ce12.
(2)那么它的哈希值就是d1f84781ec2b93224528cbb79107ce12需要在hbase shell(这回要进入hbase shell了)中执行以下命令:

执行完了之后再去看hbase:meta,就会看到这两个Region被合并成一个Region了。
如果你在执行的过程中看到类似这样的报错信息:

说明要合并的两个Region其中有一个是离线的(offline)。可以用hbase shell的assign命令上线该Region,然后再执行merge_region命令。
8.WAL的优化
首先我们知道一个Region只有一个WAL实例。WAL实例启动后在内存中维护了一个
ConcurrentNavigableMap
。这是一个线程安全的并发集合。这个ConcurrentNavigableMap包含了很多个WAL文件的引用。当一个文件写满了就会开始下一个文件。当WAL工作的时候WAL文件数量会不断增长直到达到一个阈值后开始滚动。
跟WAL有关的优化参数有:
hbase.regionserver.maxlogs:Region中的最大WAL文件数量,默认值是32。
hbase.regionserver.hlog.blocksize:HDFS块大小,没有默认值,如果你不设定该值,HBase就会直接调用HDFS的API去获取。
hbase.regionserver.logroll.multiplier:WAL文件大小因子。每一个WAL文件所占的大小通过HDFS块大小*WAL文件大小因子得出。默认值是0.95。
早期关于WAL的设置优化主要是针对如何设置合理的hbase.regionserver.maxlogs的。maxlogs就是允许有多少个WAL文件同时存在于Region之中,当WAL的数量超过了这个阈值之后就会引发WAL日志滚动,旧的日志会被清理掉。
关于如何设置合理的maxlogs数值,Hortonworks给出了建议公式:
![]()
regionserver_heap_size:RegionServer的堆内存大小。
memstore fraction:memstore在JVM的堆内存中占用的比例。
default_WAL_size:单个WAL文件的大小。
举个例子:
regionserver_heap_size:假设你的集群中的每个RegionServer的堆内存大小是16GB。
memstore fraction:假设你的memstore占40%的堆内存大小,那么这个数值就是0.4。
default_WAL_size:假设你设定了
hbase.regionserver.logroll.multiplier为0.95,而HDFS的块大小是64MB,那么现在你的单个WAL文件的大小就是60.8MB,为了计算简单,我们就算60MB吧。
套用这个公式的计算过程是:结果是WAL大小上限的最优值是109个。
![]()
不过,后来HBase舍弃了hbase.regionserver.maxlogs。理由是我们大多数人并不知道这个公式,所以直接采用了默认值。但是在刚刚的例子中,maxlogs轻易地就超过了100。而在例子中的参数其实都是很平常的服务器设置。这就给大多数用户造成了很多不便。所以摆在HBase的前面有两条路:
调大hbase.regionserver.maxlogs的默认值。把maxlogs的定义权从用户手中收回,直接由HBase内部自己计算出maxlogs的最优值。
在新的版本中,HBase选择了后者。具体的做法是这样的:根据以下公式来计算maxlogs的数值:
Math.max(32, (regionserverHeapSize * memstoreSizeRatio * 2/ logRollSize))
regionserverHeapSize:RegionServer的堆内存大小。
memstoreSizeRatio:memstore在JVM的堆内存中占用的比例。
logRollSize:单个WAL文件的大小。
所以这个公式的意思其实就是在通过公式计算出的理想WAL文件数量和32(以前的默认值)之间取最大值。可以看出计算理想的maxlogs公式跟我们前面写的建议公式几乎是一样的。只是在前面的建议公式的基础上再乘以2,所以得出的数值会比建议公式的计算结果大一倍。
在新的版本中,如果你还是设置了hbase.regionserver.maxlogs,会得到一句警告:
![]()
就是告诉你这个值已经被弃用了,设置了也没用。有的人可能会说我说了这么多不等于白说吗?因为结论就是WAL没啥可以优化的啊。其实我的目的就是让你们了解一下WAL优化 的历史,以免有的读者在网上看了资料后来设置maxlogs,但是发现并没有用,而且还得到了一句警告,会感觉很迷茫。
讲完了Region这个级别的性能优化机制后,现在要往更小的存储单元Store进发。其实Region级别的优化对性能的提高效果并不是很大,而对于Store的优化比对Region的优化更重要。