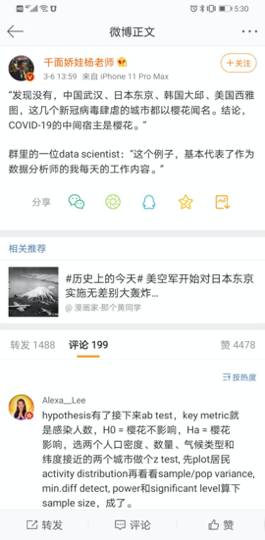
上图是关于一个数据分析的笑话,就像手里有把锤子,看什么都像钉子。知道些数据分析的技巧,逮着话题就分析。有句话说,只要你拷问数据上百遍,数据总能招供。不过我们可以从里边窥见数据分析的一般性技巧:假设检验,采样,方差分析,相关性分析等等。
数据分析,或者说数据挖掘,目的是从大数据中寻找到有趣模式和知识。
数据挖掘,使用到了多种技术,包括统计学,模式识别,可视化,机器学习等等。今天我们来探究一下在数据挖掘领域,有哪些算法可以使用。
女士品茶和数据分析
女式品茶是数据分析领域非常有名且有趣的一个故事。一位女士声称能够品尝出来奶茶是先加奶还是先加茶。然后大家设计了多轮实验来验证。然后一位数据科学家通过分析女士猜中的次数来判定她是否有这种能力。这是一个典型的通过假设检验来验证实时的案例。
《女式品茶》这本书,介绍了统计理论发展历史的一本书,介绍了数学家们关于统计学的非常有趣的历史,相比一本正经的教科书,比较生动形象。在书中介绍到一个有趣的事情,在二战后,美国人派遣了大量专家前往日本,教日本人学会美国社会是怎么运作的,其中有一位统计学家也在其中。统计学家向日本的汽车行业介绍了如何用抽样检验来保证汽车生产的质量。日本的汽车产业借助于统计理论,实现了生产质量的提升。在云计算领域,稳定性和SLA代表服务质量,如何利用好数据分析,保障稳定性,实现异常的发现,根因的诊断,是一个值得研究的课题。
统计和假设检验
数据特征描述
统计量是用来描数据特征,例如常用的均值,概括了数据的大致水位,还有哪些统计量来描述数据?
-
位置度量
- 均值、加权均值、切尾均值(可以排除尾部极大极小值的干扰)。
- 中位数,加权中位数。中位数可以很好的避免极值的干扰。除了中位数,还有百分位数,四分位距,比如99百分位。
- 最大,最小,和。
- 利群点
-
变异性,变异性代表是数据偏离中心的程度
-
偏差,平均绝对偏差,方差,中位数结对偏差,极差

探索数据分布
探索数据分布,可以快速了解数据的大致分布,对整体的情况做一个掌控。
-
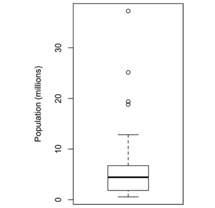
百分位数/箱线图,百分位是常用的分析数据分布的度量指标,可以了解所有数据在分布情况。
-
- 频数和直方图
- 峰度和偏度,峰度代表的是数据集中的程度,偏度代表的是数据偏离中心的程度。
分类数据描述
分类数据指的是离散数据,连续数据也可以根据区间分成离散数据。
- 众数:出现次数最多的类别和值。
- 期望值:根据概率算出期望
- 条形图:代表每个类别的频数
- 饼图:代表各个分类的占比
相关性
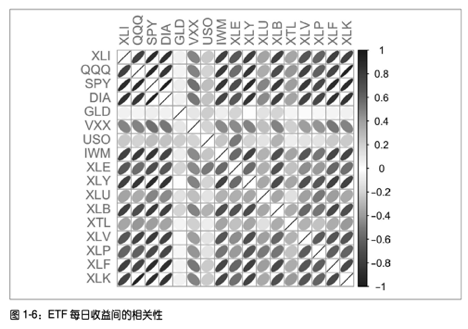
相关性考察的是双因子之间的相关性,可以用相关矩阵来表达,如上图。计算相关系数一般用皮尔逊系数。
相关性视图
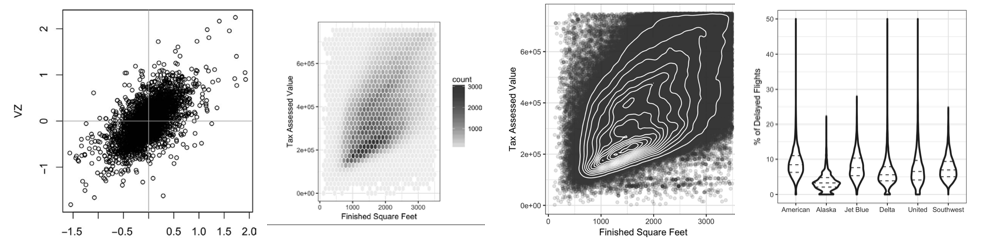
图形是最直观的表达形式,可以让读者快速看出数据的特征,上图从左到右依次是散点图、六边形图、等势线图,小提琴图。
- 散点图,可以用来观察两个指标之间的相关性
- 六边形图是对散点图的一种概括,当点比较多时,用六边形来表示,颜色越深,代表数据越多。
- 等势线图
- 小提琴图:作用类似于百分位图,但可以快速看出数据的分布,越宽的地方,代表数据越多。
抽样分布和假设检验
抽样理论是发展了数百年的数学理论,以应对大数据情况下,对大数据的分析。比如如果数据量过大,无法展开人工绘图和检测。
正态分布
钟形正态分布是一种常见的分布形态,不过这里介绍一种更加直观的形式,QQ图。QQ图把数据绘制到对角线上,如果和对角线严格匹配,那么代表是标准的正态分布。像右图那样,尾部偏离对角线,则代表有长尾分布。
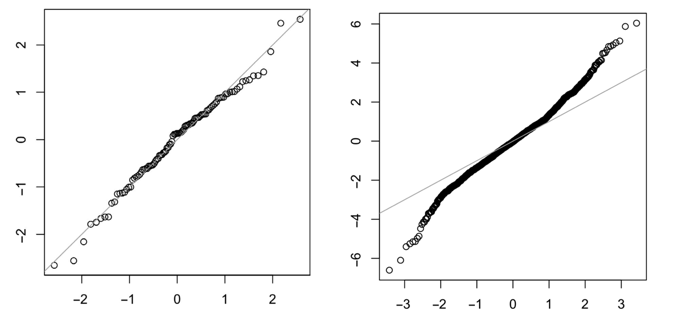
正态分布可以用来做异常检测,比如如果确定数据是遵从正态分布的。那么可以通过3σ来判定异常,如果数据偏离到均值的3σ之外,则认为数据是利群点。但前提是要保证数据是遵从正态分布的。
T检验
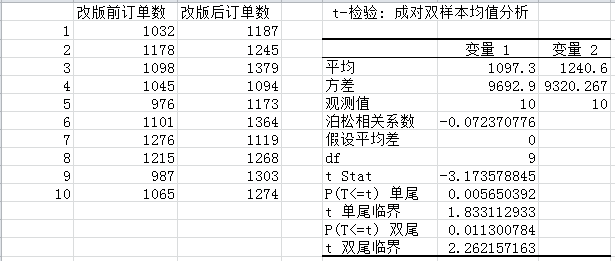
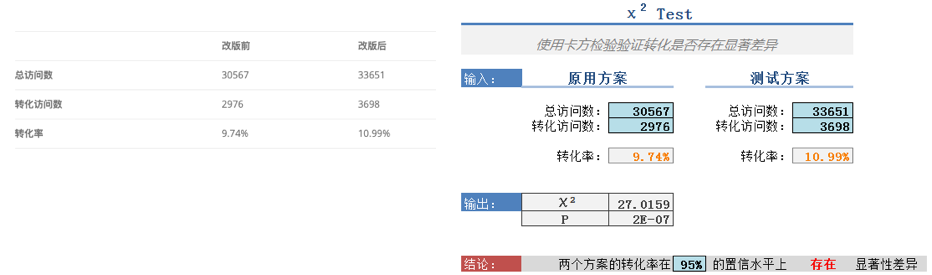
T检验可以用来对A/B 测试对比,例如下图的案例,改版前后的订单数,如何确定改版确实提升了订单数呢,而不是随机的波动?可以通过T检验来判定。
泊松分布和故障率估计
这里无意深入数学原理中来介绍二项分布、泊松分布、指数分布。三种是可以相互推倒出来。
泊松分布,假定事件发生的概率相同,推测最大期望值,例如包子店,每天要准备多少个馒头才能保证既不浪费,又能够充分的供应。根据每天供应的数量,计算出样本均值,近似代表泊松分布的期望值λ,就可以估算出泊松的概率密度函数。寻找出概率密度最大的部分对应的数值。
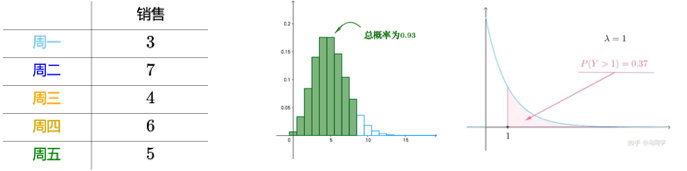
统计实验和显著性检验
统计实验可以用于A/B test中,例如两种价格的购买量,是随机结果吗?是否有显著性差异,可以通过卡方检验来完成。
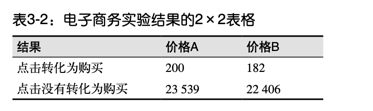
卡方检验,可以验证两个因素之间的相关性。在网站分析中可以用于转化率、Bounce Rate等所有比率度量的比较分析。
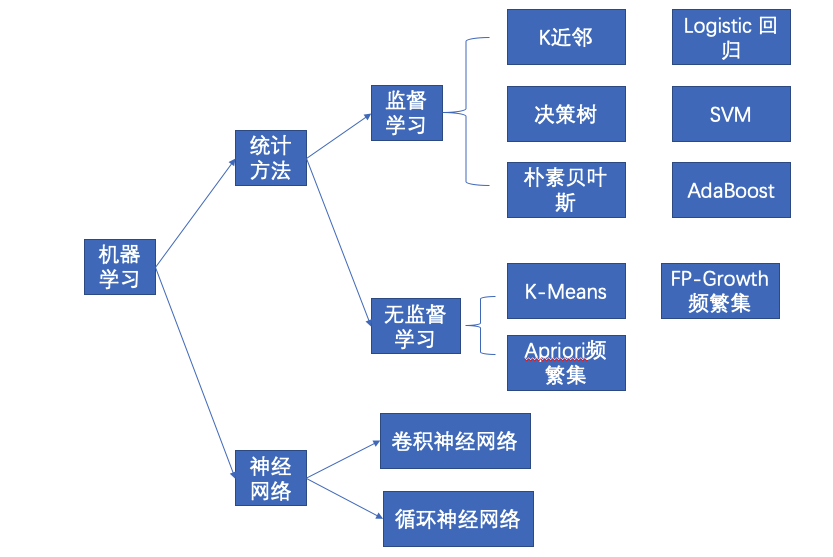
机器学习
机器学习从大的方向上分为:
- 基于统计算法的机器学习
- 基于神经网络机器学习
从使用目标上来划分,包括:
- 分类
- 聚类
- 挖掘频繁集、相关性
- 用于预测的回归
- 离群点分析
分类算法
分类算法是一种有监督学习方法,给定一批数据和对应类别(标签),求解未知数据的类别(标签)。
K近邻算法
K近邻算法是最简单的有监督学习分类算法,不需要做提前训练模型,在计算未知数据时,查找距离未知数据最近的K个点,然后查看这K个点的类别,出现最多的类别就是未知数据的类别。
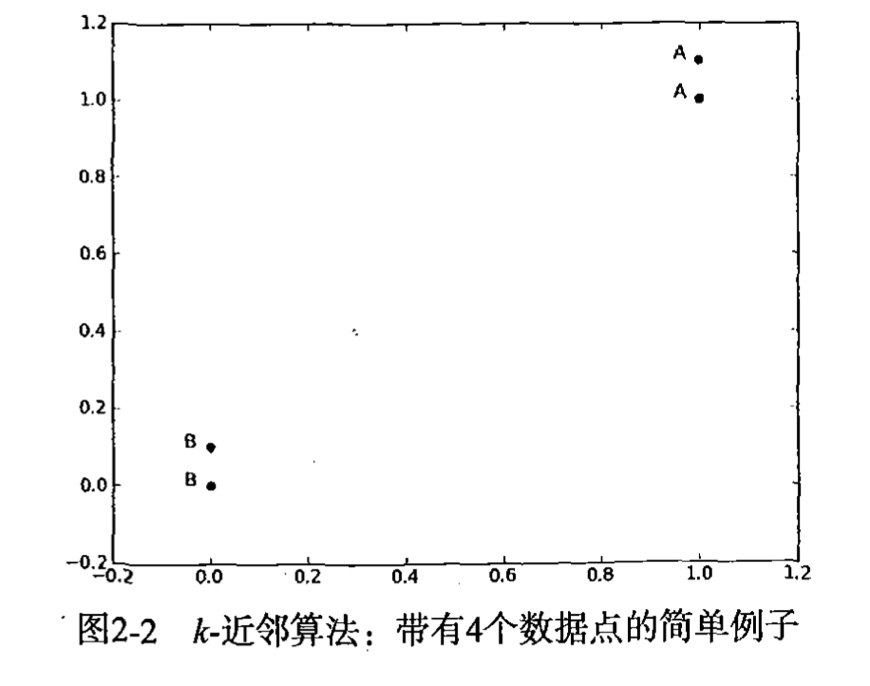
K近邻算法的优势和劣势都是很明显的。
优势:
- 逻辑简单
- 实现简单
- 不需要事先训练模型
劣势:
- 针对每个未知点,都需要计算和每个已知数据的距离,存在大量的重复计算。
K近邻一个案例,如下图,识别手写数字,可以把图片的每个像素,转写成一维向量。有标签的数据会标记图片的实际数字。当要识别一个新的图片的时候,计算新图片和带标签图片的向量距离,判定图片的数字。

决策树
决策树也是一种分类算法,是一种有监督学习。决策树的好处在于,能够训练出模型,再利用模型推断新数据。
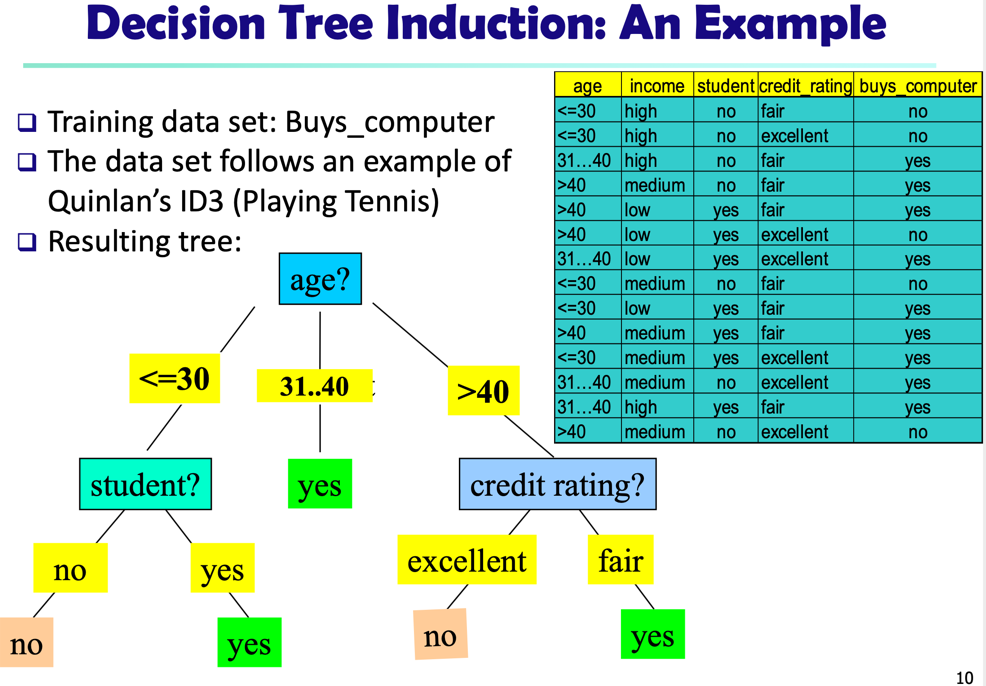
决策树的构建过程:每轮迭代,选出一个最佳特征,使得按照这个特征分类后,数据的熵最小。熵代表的是数据的混乱程度。
决策树的优点:
- 计算复杂度不高
- 分类方法容易理解
- 相比其他算法有较高的准确率
缺点:
- 容易过拟合
朴素贝叶斯
朴素贝叶斯是基于条件概率的算法,通过计算条件和标签的条件概率,计算当出现特定条件时,是特定目标的概率。举个例子,一段邮件,要判断是否是垃圾邮件,判断每个词出现的情况下,邮件是垃圾邮件的概率。那么再出现新邮件时,可以根据每个词的频率,判断是否是垃圾邮件。
Logistic回归
logistic回归是用回归方法来实现分类目的。
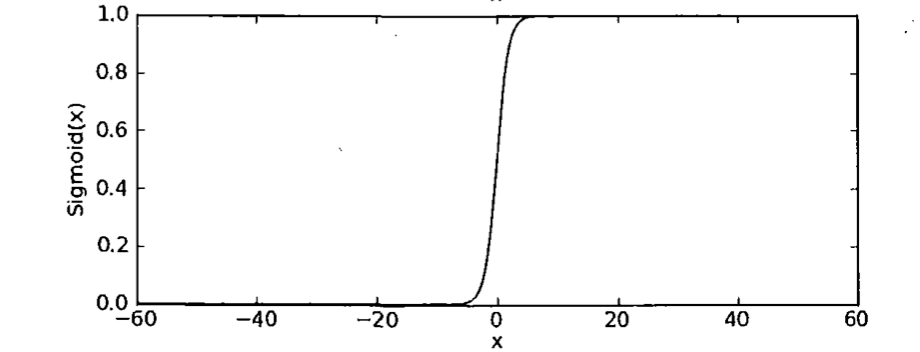
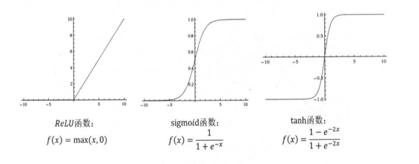
logistic回归采用的是非线性函数,或者说激活函数,如图,类似一个开关作用,开关可以起到分类的作用。
支持向量机SVM
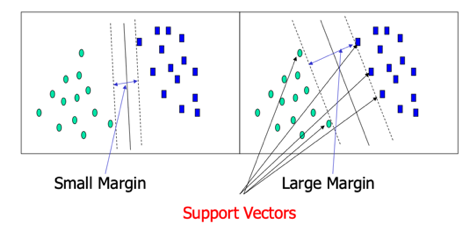
支持向量机是在多个类别中间,寻找一个平面,使得所有的点距离这个平面的距离最远,那么离这个平面最近的点,就是支持向量。如上图所示,右侧的平面距离所有点距离最远。
上图中,现在对于线性空间才存在这样的一个平面,对于非线性空间怎么处理呢?如下图,一个环形的图形,可以通过
核函数
把非线性空间转化成线性空间,再寻找支持向量。
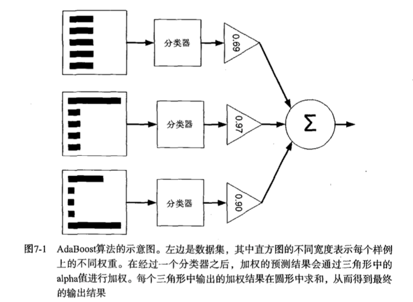
Adaboost
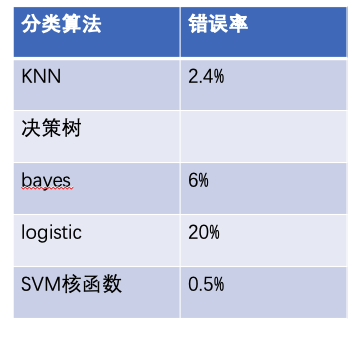
在上文中,介绍了多种分类算法,那么每一种算法的准确率如何呢?参考下表,可以说大部分算法的错误率较高,很难应用到实际生产中。究其原因,是单算法表达能力不强,无法应对复杂场景,容易在训练时被训练数据带偏,不能处理新的数据。
Adaboost是自适应的分类器,原理借鉴统计学中ada boosting。通过多个弱分类器,组成一个强分类器,每个分类器分配一个权重,在inference的时候,共同决定结果。
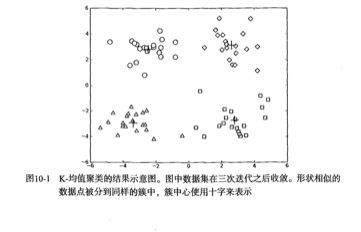
聚类算法
聚类和分类的区别:分类是有监督学习,聚类是无监督学习。
k means算法
把一批数据分成k类,给出每一类的均值。
- k mean初始时随机分配k个质心,
- 计算所有点距离每个质心的距离。
- 把每个点分配给距离最近的质心,形成k个族群。
- 计算每个族群新的质心。
- 重复上述步骤,直到质心的位置不再变化为止。
频繁集
频繁集是找出频繁出现的模式,子序列,子结构。著名的啤酒和尿布的故事,就是从一堆物品中,寻找高频出现的集合,并做关联销售。在频繁集算法中,常用的有Ariori和FP-growth算法。
离群点分析
离群点分析,算是一个数据挖掘目标,实现方法是多种多样的。
-
监督学习方法
- 分类方法建模
-
无监督学习
-
统计方法
- 例如3σ方法
- 接近度方法:基于密度或者距离来判断
- 聚类:属于稀疏类的数据。
-
统计方法
深度神经网络
上边提到的adaboost,是利用多种弱分类器来实现一个强大的分类器。算法本身包含了一层网络结构。深度神经网络是一种更加复杂的网络结构。神经网络,从输入节点到输出节点之间有多层隐藏层,每一层有多个节点,相邻的层次之间1*1全连接。多层节点形成前向反馈网络。在最后一层增加一层损失函数层,损失函数连接最终结果。中间层的每个节点,都会连接一些激活函数,参考前文logistic回归中提到的开关函数,通过这类非线性的开关函数,实现非线性的拟合。『深度神经网络』中的深度,含义就是多层网络。
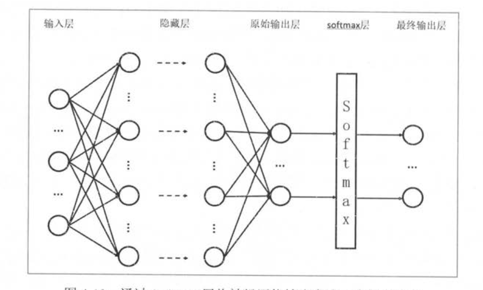
卷积神经网络CNN
上文提到的深度神经网络,各层之间是全链接,对于一些复杂的模型,会导致训练的参数非常多,训练十分困难。 卷积神经网络,节点之间不是全链接。相邻层,通过一个公共的卷积来连接。卷积内是全链接,因此大大减少了训练参数。
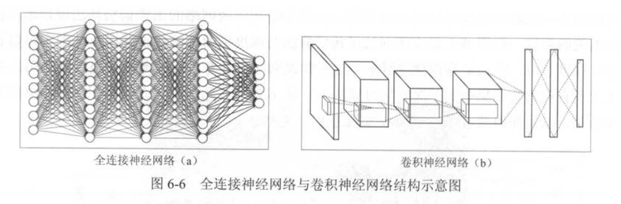
一个常见的卷积神经网络如下图所示,通过多层的卷积,池化层、激活函数组成,最后添加一个全连接层,连接到输出。

CNN大多应用于图像识别领域。
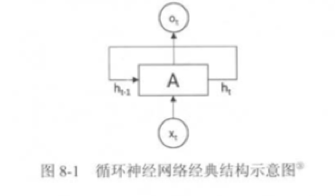
循环神经网络
CNN内部没有状态,单纯从输入到输出。因此无法训练上下相关联的场景,例如时间序列数据。循环神经网络RNN,通过内部保存状态,可以让历史上的信息影响未来的输出。已有的状态+输入 ,映射到新的状态和输出。但是RNN无法保存远期记忆,总是由最近的输入决定输出。 LSTM解决了长程依赖问题,通过一些门开关,选择性的把信息输出到下游。适用于时间序列,文本等上下文相互关联的场景。
强化学习
深度神经网络、卷积神经网络、循环神经网络,这些都是有监督学习,在大部分应用场景下,要获得大量的有标签的标注数据,这是不现实的。例如无人驾驶,围棋等场景。这种场景可以通过强化学习来完成。强化学习有三要素,分别是:
- 环境:例如当前棋盘的状态
- 动作:对当前环境的动作,例如下一步的落子
- 评分:最终的评分
通过评分大大小,来判断结果的好坏。并最终训练出最好的模型。
总结
上文列出了一些统计和假设检验、以及统计机器学习、神经网络机器学习的方法。统计机器学习属于比较传统的算法范畴,而神经网络属于最近几年比较火的内容,在特定场景下,还需要根据实际场景选择特定的算法。
参考资料
招聘阿里云智能事业群-智能日志分析研发专家-杭州/上海 扫码加我