注:本文章仅为记录本人安装过程,如有不足之处欢迎大家指正。
文章目录
一、安装前提
安装Spark前需确保
JDK1.8
、
Python3.8.5
、
Hadoop2.10.2
等已安装完成并配置对应的环境变量。如未安装以上环境,请移步如下链接:
CentOS 7下安装jdk
CentOS 7下安装Python3.8.5
CentOS 7下搭建伪分布式hadoop2.10.2
二、下载解压
1.切换至指定目录下(下列代码以本人常用路径为例)
cd /usr/local/
2.使用wget命令下载Spark压缩包
此处使用的华为云镜像,也可替换为其他镜像源
wget https://repo.huaweicloud.com/apache/spark/spark-3.2.3/spark-3.2.3-bin-without-hadoop.tgz
如果wget命令不能使用,也可以将该压缩包下载后通过Xftp等工具上传至指定目录下。
3.解压并删除压缩包
tar -zxvf ./spark-3.2.3-bin-without-hadoop.tgz && rm -rf ./spark-3.2.3-bin-without-hadoop.tgz
4.文件夹更名
mv ./spark-3.2.3-bin-without-hadoop/ ./spark-3.2.3
执行完以上步骤后可以看到Spark压缩包已经成功解压并完成了目录更名

三、修改配置文件并添加环境变量
1.修改配置文件
首先进入配置文件所在目录
cd /usr/local/spark-3.2.3/conf
然后使用配置文件的模板生成配置文件
cp spark-env.sh.template spark-env.sh
配置文件生成后再进行修改
vi spark-env.sh
需要在该配置文件中添加如下代码,其中的hadoop路径请修改为自己所安装的路径
# hadoop路径
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop-2.10.2/bin/hadoop classpath)
2.设置环境变量
首先使用编辑模式打开环境变量文件
vi /etc/profile
然后在该文件中添加如下代码并保存,其中包含了Spark安装目录以及PySpark,PySpark 是 Spark 为 Python 开发者提供的 API,不需要可以不添加。(由于文章开头已提到默认安装了JDK、Python、Hadoop并配置了对应的环境变量,故此处不涉及上述环境的环境变量)
# spark
export PATH=$PATH:$SPARK_HOME/bin
export SPARK_HOME=/usr/local/spark-3.2.3
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.9.5-src.zip:$PYTHONPATH
# pyspark
export PYSPARK_PYTHON=python3
export PATH=$HADOOP_HOME/bin:$SPARK_HOME/bin:$PATH
使环境变量生效
source /etc/profile
四、测试运行
1.运行spark-shell
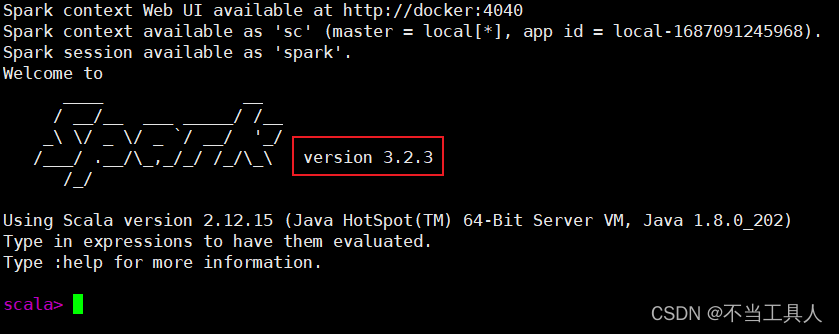
spark-shell
可以看到成功运行spark-shell,并标注出了Spark版本信息
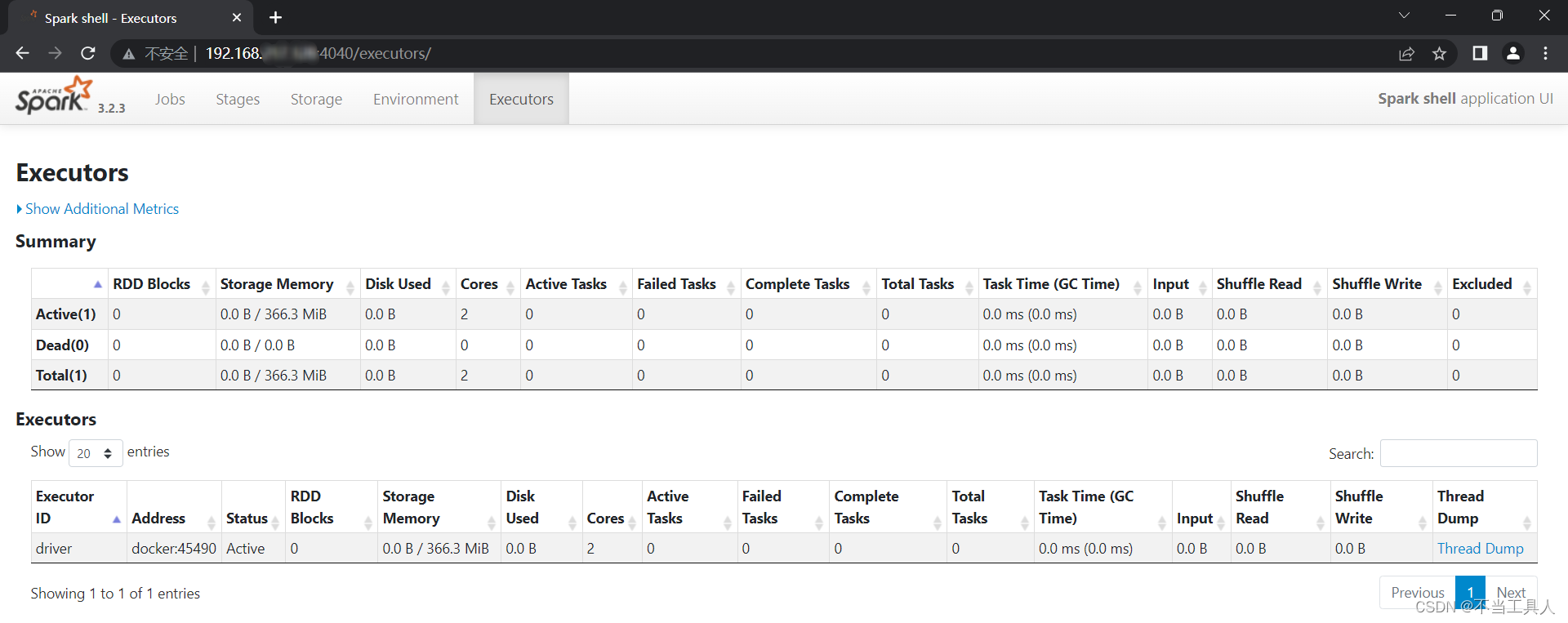
此时使用浏览器打开网页“
http://虚拟机ip:4040/
”则可查看SparkUI相关信息。(如果无法访问可能是防火墙原因)
使用如下命令即可退出spark-shell,也可以使用键盘Ctrl+C结束进程
:quit
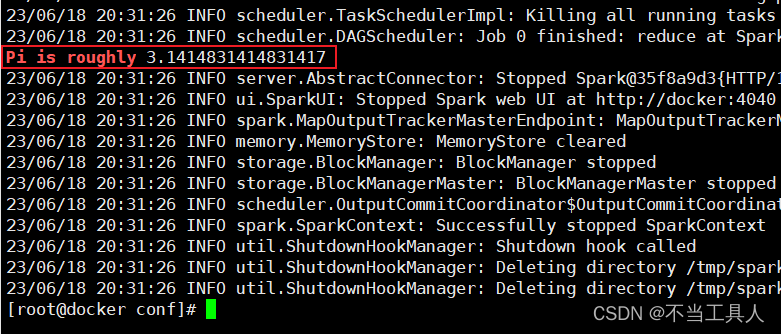
2.运行自带示例
运行自带示例测试打印圆周率
run-example SparkPi 10 | grep "Pi is roughly"
可以看到运行结果已经高亮显示出来
总结
本文章仅为
记录本人安装过程
,如有不足之处欢迎大家指正。